Радиотехники, электроники и автоматики»
МГТУ МИРЭА
Факультет информационных технологий (ИТ)
Кафедра № 239 «АСОУ» МГТУ МИРЭА при ФГУП НИИ «Восход»
Отчет по лабораторной работе №2
По дисциплине
«Системы искусственного интеллекта»
Тема: «Классификация объектов по их признакам»
| Выполнил студент гр. ИТВ-2-08 | [NAME HERE] | ||
| Преподаватель | |||
| А.Н. Вараксин | |||
| Оценка | |||
| Дата | |||
Москва 2012 г.
Цель работы:
Увеличение вероятности правильной классификации объектов по родам.
Исходные данные:
1. Пакет Matlab;
2. Данные, сгруппированные по родам.
3. Исходная матрица перепутывания для оценки вероятности правильной классификации ОВ:

Вероятность правильной классификации Pов=0,64
4. Матрица перепутывания для оценки качества ЭВ:
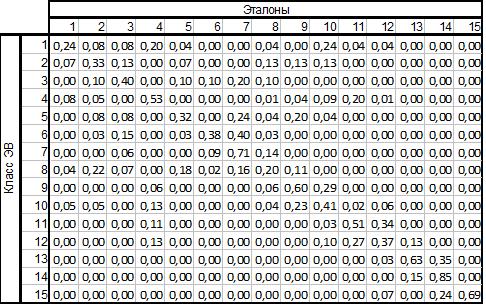
Вероятность правильной классификации Pэв=0,47
Фрагмент исходных данных:
1.01 23.6 41.80 4.51 9.95 11.06 1.04
1.02 23.4 50.44 3.64 9.36 12.41 1.14
1.03 23.2 44.39 3.80 10.23 9.56 1.00
1.04 23.3 40.91 3.13 9.61 11.47 1.05
1.05 23.9 40.82 4.19 9.72 10.17 1.42
1.06 23.8 41.84 4.42 11.94 9.88 1.35
1.07 24.4 47.85 3.80 7.55 10.63 1.50
1.08 23.7 41.72 4.00 12.52 11.18 1.32
1.09 21.7 43.66 3.54 11.27 9.88 1.36
1.10 23.7 45.78 3.19 12.81 12.28 1.40
1.11 26.8 38.57 4.42 11.49 8.88 1.64
1.12 24.2 45.00 3.95 14.25 10.25 1.57
1.13 24.5 42.46 3.64 15.03 9.88 1.75
1.14 25.9 39.05 4.00 15.00 10.70 1.68
1.15 24.8 38.37 3.19 12.88 7.91 1.55
1.16 25.1 41.08 2.80 15.13 8.00 1.53
1.17 25.4 40.32 2.65 15.44 8.50 1.65
1.18 26.5 37.12 3.13 14.64 8.41 1.20
1.19 25.7 39.50 2.58 14.14 7.32 1.80
1.20 26.7 41.92 3.54 15.97 7.07 1.54
1.21 32.5 32.36 2.68 12.62 9.93 1.49
1.22 31.2 28.02 3.26 12.18 8.40 1.56
1.23 31.1 32.96 2.94 11.74 7.80 1.65
1.24 30.8 30.58 2.88 11.61 8.65 1.54
1.25 32.0 34.18 3.21 13.27 8.61 1.55
1.26 27.6 33.40 2.83 12.05 8.00 1.59
1.27 29.4 32.62 3.45 9.75 10.83 1.53
1.28 28.8 35.44 3.18 9.13 12.89 1.71
1.29 29.5 37.51 4.24 10.60 9.71 1.62
...
15.082 13.9 64.06 3.37 7.60 17.06 2.60
15.083 13.7 73.22 4.00 7.83 16.82 2.62
15.084 15.7 69.30 3.13 9.25 16.89 2.40
15.085 14.4 65.29 4.55 8.13 13.24 2.35
15.086 14.7 61.90 2.65 10.17 14.39 2.55
15.087 13.8 69.57 3.95 9.70 16.64 2.49
15.088 13.6 66.63 2.58 6.90 16.07 2.38
15.089 14.9 63.25 3.20 8.34 15.32 2.92
15.090 12.8 76.04 3.64 8.15 16.77 2.90
15.091 14.2 75.64 3.13 6.64 16.89 2.65
15.092 13.8 75.14 3.64 8.50 19.76 2.61
15.093 14.8 70.76 4.00 8.41 17.38 2.84
15.094 13.7 65.39 2.25 7.53 15.63 2.80
15.095 14.9 79.86 3.19 6.19 17.29 2.69
15.096 13.6 70.40 2.58 6.37 17.78 2.59
15.097 14.3 66.54 2.80 6.90 19.12 2.67
15.098 15.0 71.43 2.50 8.15 19.01 2.29
15.099 14.0 67.60 3.80 9.10 17.16 2.56
15.100 14.5 71.17 3.37 7.13 17.88 2.39
15.101 14.2 73.44 3.64 7.07 16.36 2.52
15.102 15.0 63.38 4.00 8.50 16.41 2.23
15.103 14.5 64.27 3.13 7.53 16.44 2.28
15.104 15.8 67.92 3.80 7.32 16.40 2.04
15.105 15.1 63.72 2.58 7.55 18.00 2.05
15.106 15.3 71.29 3.95 6.99 15.44 2.20
15.107 14.9 67.08 3.19 5.93 17.43 2.02
15.108 16.1 61.78 4.19 7.83 16.77 2.37
15.109 15.5 65.47 3.37 8.13 16.25 2.19
15.110 15.9 62.61 3.13 6.76 19.13 2.12
Теоретическая часть
Наборы данных классифицируют по следующим признакам:
v по количеству переменных (одномерные, двумерные или многомерные наборы данных);
v по типу данных (количественные или качественные);
v по тому, важна ли упорядоченность данных во времени или нет.
Существует два типа количественных данных:
v дискретные;
v непрерывные.
Дискретная - это такая переменная, которая может принимать значения только из некоторого списка определенных чисел. Примерами дискретной переменной являются число детей в семье; число вызовов "скорой помощи", поступающих в больницу; число отказов изделия; число клиентов, обратившихся в фирму за определенный промежуток времени, и т. д.
Непрерывной будем считать любую переменную, не являющуюся дискретной. Она принимает значения из некоторого промежутка. Примерами непрерывной переменной является рост взрослого человека (например от 140 до 230 см), фактическая масса буханки хлеба (например от 750 до 830 г), дальность полета снаряда, урожайность культуры, выращенной в хозяйстве и т. п.
Качественные данные - данные, которые регистрируют определенное качество, которым обладает объект.
Качественные данные бывают двух типов: порядковые, для которых существует имеющий содержательный смысл порядок; номинальные, для которых нет содержательно интерпретируемого порядка.
Порядковые данные можно ранжировать и использовать это ранжирование при проведении статистического анализа. Примером порядковых данных являются ответы на вопросы анкеты, содержащей следующие варианты ответов: да; больше да, чем нет; больше нет, чем да; нет. Хоть и можно выразить эти ответы числами (например, 4, 3, 2, 1), но предложенная шкала оценок носит субъективный характер. Нельзя считать, что разница между ответами 4 и 3 такая же, как и между ответами 2 и 1. Также нельзя считать, что ответ 3 в три раза лучше ответа 1.
Для номинальных данных нет числовых значений и нет основы для ранжирования.
Примерами номинальных данных являются регионы России, из которых приехали студенты; названия фирм изготавливающих моющие средства; пол работников фирмы.
Выполнение лабораторной работы.
1. Исходные данные представлены по родам. 15 родов образуют 15 классов распознавания.
2. Разделяем каждый класс на обучающую и экзаменационную выборку. В обучающую выборку выносятся все чётные элементы, а в экзаменационную – все нечётные.
3. Для повышения вероятности правильной классификации изменять выборку нельзя, поэтому будем улучшать её, выделяя новые эталоны для классов. Проанализировав исходные матрицы перепутывания делаем вывод о наличии ошибок второго рода в первом классе. Выделим отдельно его ОВ, найдём её средний вектор и определим по Евклидовой мере близости расстояния от него до всех векторов выборки. Отсортируем результат по возрастанию.

Рисунок 1. График расстояний ОВ первого класса (отсортированный по возрастанию)
На графике можно наблюдать сильный изгиб (отмечен точкой). Разделим ОВ первого класса на два подкласса.
4. Находим эталоны обучающей выборки. Проще всего это сделать путем нахождения среднего вектора каждой обучающей выборки. Итого получаем 16 эталонов, два из которых соответствуют первому, а все остальные – своему классу.
5. Производим нормировку обучающей выборки путем деления каждого вектора группы на средний вектор исходного массива данных.
6. Нормируем эталоны и проверяем их качество путем сравнения каждого эталона с каждым вектором изначальной выборки и проверки принадлежности каждого вектора к тому или иному семейству путем нахождения минимального расстояния от вектора до эталона. При этом используется Евклидова мера близости:

Строим таблицу перепутывания для определения качества эталона. Таблица будет иметь размер 15 на 15 клеток. По горизонтали и вертикали откладываются номера классов. По Евклидовой мере близости определяется минимальное расстояние до шаблона, и в клетку, соответствующего шаблону семейства, прибавляется единица. После нахождения всех расстояний производится нормировка значений в клетках таблицы путем деления каждого значения на сумму значений в строке, затем суммируются все диагональные элементы и делятся на общее количество семейств. Таким же образом проверяется и качество выборки, только в этом случае с эталонами сравниваются не все векторы из изначальной выборки, а векторы из экзаменационной выборки.
Ненормированная таблица перепутывания для оценки качества ОВ
Таблица 1

Таблица 2
Нормированная таблица перепутывания для оценки качества ОВ

Полученная вероятность (в отсутствии представительной статистики частность): 0,66 (исходная – 0,64).
Таблица 3
Ненормированная таблица перепутывания для оценки качества ЭВ

Таблица 4
Нормированная таблица перепутывания для оценки качества ЭВ
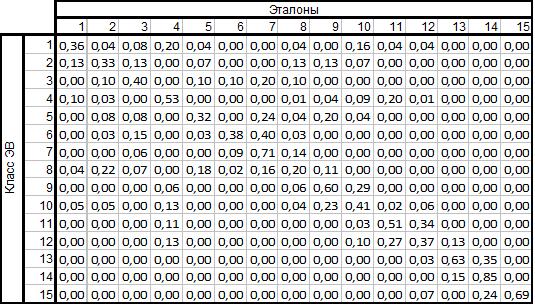
Полученная вероятность (в отсутствии представительной статистики частность): 0,49 (исходная – 0,48).
Результирующая вероятность правильной классификации ОВ составила 0,66 (первоначальная была равна 0,64), а результирующая вероятность ЭВ – 0,49 (первоначальная – 0,48). На основе анализа ошибок первого и второго рода было принято решение улучшать качество эталонов путём деления первого класса на два кластера и вычисление на их основе эталонов.
Таким образом, достигнута цель лабораторной работы по улучшению вероятности правильной классификации с 0,48 до 0,49.
Выводы
1. Проведен анализ исходных семейств с выделением 15 классов.
2. Проведен анализ классов на возможность разбиения на подклассы с целью улучшения вероятности правильной классификации и, как следствие, улучшение построенного ранее классификатора в целом.
3. Построены новые эталоны классов и проверена их вероятность правильной классификации. Установлено, что Ров возросла с 0,64 до 0,66.
4. С помощью улучшенных эталонов проверена вероятность правильной классификации. Установлено, что Рэв возросла c 0,48 до 0,49.
5. Установлено, что созданный классификатор обеспечивает лучшее качество классификации, чем предыдущий, за счёт разделения первого класса на два кластера и расчёта эталонов как среднее арифметическое для них.
6. В результате вероятность правильной классификации по родам Рэв увеличилась с 0,48 до 0,49.