Здесь, вместо арифметических сравнений ключей проверяется, равны ли нулю или единице отдельные биты ключей. В общих чертах идея метода следующая:
I этап. Файл сортируется по старшему значащему биту ключа так, что все ключи, начинающиеся с нуля, оказываются перед всеми ключами, начинающимися с единицы. Для этого надо найти самый левый ключ ki, начинающийся с единицы, и самый правый kj, начинающийся с нуля, после чего записи Ri и Rjменяются местами. Процесс повторяется до тех пор, пока не станет i>j.
II этап. Обозначим через F0 множество элементов, начинающихся с нуля, а через F1 – остальные. Применим к F0 обменную поразрядную сортировку (начинаем теперь со второго бита слева) до тех пор, пока множество F0 не будет полностью отсортировано. Затем проделываем то же самое с множеством F1. Как и при быстрой сортировке, для хранения информации о подфайлах, ожидающих сортировки, можно воспользоваться стеком. Стратегию формирования стека здесь применяют другую: в стек помещают не больший из подфайлов, а правый подфайл, при этом элемент стека (r,b) означает, что подфайл с правой границей r ожидает сортировку по биту b. Левую границу можно не запоминать, она всегда задана неявно, так как файл обрабатывается слева направо.
Алгоритм:
Записи от 1-й до N-й R1,R2,…,RNпереразмещаются на том же месте. После завершения сортировки их ключи будут упорядочены
k1≤…≤kn.
Предполагается, что все ключи – это m-разрядные двоичные числа:
а1,а2,…,аm.
R1 [Начальная установка.] Опустошить стек, установить l←1,
r←N,b←1.
R2 [Начать новую стадию.] Сортировать подфайл записей со
следующими границами:
Rl≤…≤Rrпо биту b.
По смыслу алгоритма l≤r; если l=r, то перейти к R10, в
противном случае i←l,j←r.
R3 [Проверить k i на единицу.] Проверить бит b ключа k i на единицу.
Если (ki)b=1, то перейти к шагу R6.
R4 [Увеличить i.] Если i≤j, то возвратиться к R3, иначе к шагу R8.
R5 [Проверить k j+1 на ноль.] Проверить бит b ключа kj+1.
Если (kj+1)b=0, то перейти к шагу R7.
R6 [Уменьшить j.] Уменьшить j на 1. Если i≤j, то перейти к шагу R5, иначе к R8.
R7 [Поменять местами записи Riи Rj+1.] Поменять местами Ri и Rj+1, затем перейти к шагу R4.
R8 [Проверить особые случаи.] К этому моменту стадия разделения
завершена, i=j+1, бит b ключей от kl до kj равен нулю, а бит b ключей от ki до kr равен единице. Увеличить b на 1. Если b>m, где m – общее число битов в ключах, то перейти к шагу R10. Это значит, что подфайл
Rl…Rr отсортирован. Если в файле не может быть равных ключей, то такую проверку можно не делать. Иначе, если j<1 или j=r, возвратиться к шагу R2 (все просмотренные биты оказались равными соответственно
единице или нулю).
Если j=l, то увеличить l на 1 и перейти к шагу R2 (встретился
только один бит, равный нулю).
R9 [Поместить в стек.] Поместить в стек элемент (r,b), затем установить
r←j и перейти к R2.
R10 [Взять из стека.] Если стек пуст, то сортировка закончена, иначе
установить l←r+1, взять из стека элемент (r’,b’), установить
r←r’,b←b’ и возвратиться к шагу R2.
Для хранения “информации о границах” подфайлов, ожидающих сортировки, можно воспользоваться стеком.
Вместо того, чтобы сортировать в первую очередь наименьший из подфайлов, удобно просто продвигаться слева направо, так как размер стека в этом случае никогда не превзойдёт числа битов в сортируемых ключах.
Пример: Сортировка методом обменная поразрядная. Ключи заданы в восьмеричном виде.
 |

 15 11 22 25 3 4 17 14
15 11 22 25 3 4 17 14
10001 01101 01001 10010 10101 00011 00100 01111 01100 01010
 |

 12 15 11 25 3 4 17 21
12 15 11 25 3 4 17 21


 по 5-му
по 5-му
биту 12 15 11 14 3 4 22 21
 | |||||||
 | |||||||
 |  | ||||||
по 4-му 15 11 14 17 3 25 22 21
 биту сортировать не надо
биту сортировать не надо
 |
4 11 14 17 12 25 22 21

по 3-му 11 17 15 22
по 2-му 

 3 4 11 12 15 21 22 25
3 4 11 12 15 21 22 25

по 1-му 3 4 11 12 14 15 17 21 22 25

результат- 3 4 11 12 14 15 17 21 22 2
8. Сортировка. Методы выбора и слияния. Простой, квадратичный выбор. Выбор из дерева. Двухпутевое слияние. Метод слияния списков
Простой выбор
Простейшая сортировка, построенная на этой идее, состоит из следующих шагов:
1. Найти наименьший ключ, после чего выбрать соответствующую ему запись и переслать её в начало некоторой пустой области памяти (область вывода).
Так, как операция ввода соответствует чтению данных и не удаляет физически запись из сортируемого файла, то удаление имитируется заменой ключа на значение “∞” (∞ по предположению больше любого реального ключа).
2. Повторить шаг 1. На этот раз будет найден ключ, наименьший из оставшихся.
3. Повторять шаг 1 до тех пор, пока не будут выбраны все N записей.
Этот метод требует наличия всех исходных элементов до начала сортировки, а элементы вывода он порождает последовательно, один за другим. Картина по существу противоположна методу вставок, в котором исходные элементы должны поступать последовательно, но вплоть до завершения сортировки ничего не известно об окончательном выводе.
Описанный метод требует N-1 сравнений каждый раз, когда выбирается очередная запись.
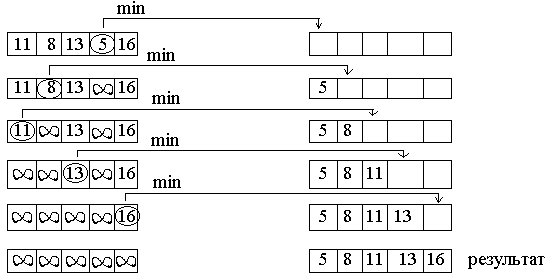 |
Пример: Сортируемый файл Область вывода
Квадратичный выбор
Рассмотрим следующий метод: пусть файл содержит 16 записей. Разобьём его на четыре группы по четыре записи:
|| 14 5 18 21 || 2 7 11 3 || 9 26 1 8 || 13 22 6 20 ||.
Найдём наибольшие элементы в каждой группе и соберём их вместе в группу '' лидеров'':
21 11 26 22
Тогда наибольший среди них и будет наибольшим в файле. Чтобы получить второй по величине элемент, достаточно просмотреть оставшиеся элементы группы, содержащей 26 (т.е. максимальный), и максимальный из них поместить в «группу лидеров» на место 26 и т.д.
Выбор из дерева
 С помощью n/2 сравнений можно определить наименьший элемент (ключ) из каждой пары, при помощи n/4 сравнений можно выбрать наименьший из каждой пары таких наименьших ключей и т.д. Наконец, при помощи n-1 сравнений можно построить дерево выбора и определить корень как наименьший ключ.
С помощью n/2 сравнений можно определить наименьший элемент (ключ) из каждой пары, при помощи n/4 сравнений можно выбрать наименьший из каждой пары таких наименьших ключей и т.д. Наконец, при помощи n-1 сравнений можно построить дерево выбора и определить корень как наименьший ключ.


 6
6



 12 6
12 6


 44 12 18 6
44 12 18 6
44 55 12 42 94 18 6 + ¥ 67
Рис. 1 Дерево выбора, выбор 1-го элемента
 На втором шаге нужно спуститься по пути, указанному наименьшим ключом, и исключить его, последовательно заменяя либо на “дыру” (или ключ ∞), либо на элемент, находящийся на противоположной ветви промежуточного узла.
На втором шаге нужно спуститься по пути, указанному наименьшим ключом, и исключить его, последовательно заменяя либо на “дыру” (или ключ ∞), либо на элемент, находящийся на противоположной ветви промежуточного узла.


12

 44 12 18
44 12 18
Рис. 2 Дерево выбора, выбор 2-го элемента
Элемент, оказавшийся в корне дерева, вновь имеет меньший ключ (среди оставшихся) и может быть исключён.
После n таких шагов дерево становится пустым (т.е. состоит из “дыр”), и процесс сортировки закончен.
Каждый из n шагов требует log2n сравнений. Вся сортировка требует порядка n*log2n элементарных операций, не считая n шагов, которые необходимы для построения дерева.
СОРТИРОВКА СЛИЯНИЕМ