1. Генеральная совокупность – это статистическая совокупность
1. Состоящая из большого числа элементов, однородных относительно некоторого качественного или количественного признака, характеризующего эти объекты.
2. Распределение которой по интересующему нас признаку необходимо изучить.
3. Состоящая из всех возможных элементов, однородных относительно некоторого качественного или количественного признака, характеризующего эти объекты.*
2. Выборка – это
1. Множество объектов, отобранных для изучения параметров распределения генеральной совокупности. *
2. Множество объектов, отобранных для изучения.
3. Любая часть генеральной совокупности.
3. Основным требованием к выборке при изучении параметров генеральной совокупности является
1. Ее объем.
2. Ее математическое ожидание.
3. Ее репрезентативность.*
4. Для описания выборки
1. Ранжируют варианты выборки и находят ее числовые характеристики.*
2. Строят гистограмму.
3. Находят среднее арифметическое значение выборки.
5. Генеральной средней 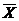 называют
называют
1. Среднее арифметическое значений х1, х2,..., хN (где N - число членов генеральной совокупности)  *
*
2. Среднее арифметическое значений х1, х2,..., хN (где N - число членов генеральной совокупности) 
3. Среднее арифметическое всех выборок, взятых из этой генеральной совокупности.
6. Генеральная дисперсия определяет
1. Меру рассеяния значений количественного признака Х генеральной совокупности около генеральной средней.
2. Среднее арифметическое квадратов отклонений величин хi генеральной совокупности от их среднего арифметического или m. *
3. Значение количественного признака Х генеральной совокупности.
7. Генеральная дисперсия может быть представлена выражением
1. 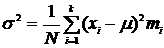 .*
.*
2. 
3. 
8. Выборочная дисперсия может быть представлена выражением
1. 
2. 
3.  , где: mi - частота появления признака.*
, где: mi - частота появления признака.*
9. Выборочная средняя является
1. Смещенной оценкой оцениваемого параметра генеральной совокупности.
2. Несмещенной оценкой аналогичного параметра генеральной совокупности, так как выполняется условие: 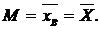 *
*
3. Оценкой несмещенной аналогичного параметра генеральной совокупности, так как выполняется условие: 
10. Оценка генеральной дисперсии может быть произведена при помощи выражения
1.  при условии, что n > 30.
при условии, что n > 30.
2. 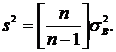 , при условии, что n < 30.*
, при условии, что n < 30.*
3.  , при условии, что n > 30.
, при условии, что n > 30.
11. В интервальной оценке устанавливается
1. Вероятность того, что непрерывная случайная величина может принять то или иное значение из некоторого доверительного интервала.*
2. Доверительная вероятность, с которой эта оценка попадает в оцененный интервал.
3. Интервал, в котором принимают значения все случайные величины, входящие в генеральную совокупность.
12. Коэффициент Стьюдента (tp,n) вводится
1. При интервальной оценке некоторого параметра генеральной совокупности для корректировки доверительного интервала, если мощность выборки n > 30.
2. При интервальной оценке некоторого параметра генеральной совокупности для корректировки доверительного интервала, если мощность выборки n < 30. *
3. При точечной оценке параметра генеральной совокупности для корректировки доверительного интервала, если мощность выборки n < 30.
13. Коэффициент Стьюдента зависит
1. Как от мощности выборки, так и от выбранной доверительной вероятности *
2. Только от мощности выборки.
3. От выбранной доверительной вероятности (вероятности, с которой интервальная оценка покроет оцениваемый параметр) и не зависит от мощности выборки.
14. Уровень значимости оценивает
1. Вероятность допустимой ошибки.*
2. Вероятность того, что числовое значение характеристики генеральной совокупности находится вне доверительного интервала.
3. Вероятность того, что числовое значение характеристики генеральной совокупности находится в пределах доверительного интервала.
15. Нулевая гипотеза H0 – статистическая гипотеза, исходящая из предположения
1. Что между генеральными параметрами сравниваемых групп разница равна нулю и различия, наблюдаемые между выборочными показателями, носят не систематический, а случайный характер.*
2. Об отсутствии различия между выборочными параметрами.
3. О равенстве нулю разницы между соответствующими генеральными и выборочными параметрами независимо от уровня значимости.
16. Конкурирующая (или альтернативная) гипотеза HА – статистическая гипотеза, исходящая из предположения
1. О равенстве нулю разницы между соответствующими генеральными и выборочными параметрами, но только при определенном уровне значимости.
2. О равенстве нулю разницы между соответствующими генеральными и выборочными параметрами при любом уровне значимости.
3. О наличии разницы между генеральными параметрами, оцениваемыми по выборочным показателям.*
17. Критерий значимости (достоверности) – это показатель, позволяющий судить о
1. Ошибочности выводов относительно принятой гипотезы.
2. Вероятности выводов относительно принятой гипотезы.
3. Надежности выводов относительно принятой гипотезы.*
18. Критерий значимости (достоверности) – это формула, позволяющая вычислить
1. Показатель различия между сравниваемыми параметрами в предполагаемой гипотезе.*
2. Величину нулевой гипотезы.
3. Величину альтернативной гипотезы.
19. Степени свободы – числа, показывающие
1. Суммарный объем сравниваемых выборок или генеральных совокупностей.
2. Количество свободно варьирующих членов статистической совокупности, способных принимать любые произвольные значения.*
3. Количество сравниваемых выборок.
20. Сравнение экспериментального и критического значений критерия позволяет сделать выбор между нулевой и альтернативной гипотезой
1. Если Пэксп < Пкрит, то принимается нулевая гипотеза.*
2. Если Пэксп < Пкрит, то нулевая гипотеза отвергается в пользу альтернативной.
3. Если Пэксп - Пкрит =0, то нулевая гипотеза отвергается в пользу альтернативной.
21. Критерий Лапласа применяется для сравнения генеральных средних
1. При больших объемах выборок, подчиняющихся закону нормального распределения.
2. При малых и равных объемах выборок, подчиняющихся закону нормального распределения.
3. При больших объемах выборок, подчиняющихся любому закону распределения.*
22. Критерий Фишера-Стьюдента применяется для сравнения
1. Генеральных дисперсий.
2. Выборочных средних.
3. Генеральных средних.*
23. Критерий Фишера-Стьюдента применяется для сравнения генеральных средних, если выполняются требования
1. Выборки подчиняются закону нормального распределения, имеют любые по величине равные объемы и сравнимые дисперсии.
2. Выборки подчиняются закону нормального распределения, имеют малые равные объемы и сравнимые дисперсии.
3. Выборки подчиняются закону нормального распределения, имеют малые или равные объемы и сравнимые дисперсии.*
24. Критерий Фишера-Снедекора позволяет сделать вывод между нулевой и альтернативной гипотезами для равенства
1. Генеральных дисперсий.*
2. Выборочных дисперсий.
3. Генеральной и выборочной дисперсий.
25. Критерий Фишера-Снедекора позволяет сделать вывод между нулевой и альтернативной гипотезами для равенства генеральных дисперсий, если сравниваемые выборки удовлетворяют условиям
1. Выборки подчиняются закону нормального распределения, имеют любые по величине равные объемы и сравнимые математические ожидания.
2. Выборки подчиняются закону нормального распределения, имеют малые или равные объемы и сравнимые математические ожидания.*
3. Выборки подчиняются закону нормального распределения, имеют малые равные объемы и сравнимые математические ожидания.
26. Гипотезу о законе распределения можно проверить при помощи критерия
1. Лапласа.
2. Фишера – Стьюдента.
3. Пирсона.*
27. Для проверки гипотезы о нормальном законе распределения нужно знать
1. Значения вариант и частоту их повторяемости в выборке.
2. Значения вариант и частоту их повторяемости в исследуемом законе.
3. Значения вариант и частоту их повторяемости в выборке и по исследуемому закону.*
28. Корреляционный анализ позволяет
1. Оценить степень влияния между признаками двух и более рядов.*
2. Оценить вероятность влияния между признаками двух и более рядов.
3. Оценить достоверность влияния между признаками двух и более рядов.
29. Говорят, что между признаками Х и Y существует корреляционная зависимость, если
1. Изменению одного из них соответствует изменение математического ожидания другого: M(Y)x = f(x); M(X)y = j(y). *
2. Изменению одного из них соответствует изменение другого:
Y = f(x); X = j(y).
3. Изменению одного из них соответствует несколько значений другого.
30. Коэффициент парной корреляции R может принимать только
1. Четные значения.
2. Положительные значения.
3. Значения от (–1) до +1.*
31. Если значение коэффициента парной корреляции R > 0, то корреляция является
1. Прямой.*
2. Обратной.
3. Равной.
32. Если значение коэффициента парной корреляции R < 0, то корреляция является
1. Прямой.
2. Обратной.*
3. Равной.
33. Если значение коэффициента парной корреляции 0 < R < 0,4, то корреляция является
1. Сильной.
2. Средней.
3. Слабой.*
34. Если значение коэффициента парной корреляции 0,4 < R < 0,7, то корреляция является
1. Сильной.
2. Средней.*
3. Слабой.
35. Если значение коэффициента парной корреляции 0,7 < R < 1, то корреляция является
1. Сильной.*
2. Средней.
3. Слабой
36. По значению выборочного коэффициента парной корреляции
1. Нельзя судить о наличии корреляции и в генеральный совокупностях.
2. Можно судить о наличии корреляции в генеральный совокупностях только с некоторой вероятностью.*
3. Можно судить о наличии корреляции и в генеральный совокупностях.
37. Выборочный коэффициент парной корреляции является значимым, если для него будет выполняться условие
1.  .*
.*
2. 
3. 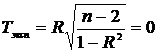
38. Значения коэффициентов уравнений регрессии
1. Не зависит от значения коэффициента парной корреляции, а зависят от числовых характеристик коррелирующих совокупностей.
2. Зависит только от значения коэффициента парной корреляции и не зависят от числовых характеристик коррелирующих совокупностей.
3. Зависит от значения коэффициента парной корреляции и числовых характеристик коррелирующих совокупностей.*
39. Корреляционное поле представляет собой
1. Линию, соединяющую точки с координатами (Xi; Yi).
2. Множество точек с координатами (Xi; Yi).*
3. Множество линий регрессии для данной корреляционной зависимости.
40. Регрессионный анализ позволяет
1. Найти функцию, которая точно описывает зависимость между значениями коррелирующих рядов.
2. Найти функцию, которая наиболее точно описывает зависимость между значениями коррелирующих рядов. *
3. Найти функцию, которая с определенной вероятностью описывает зависимость между значениями коррелирующих рядов.
41. Функция регрессии показывает
1. Как изменяются значения ряда Х при изменении значений ряда Y.
2. Как изменяются значения ряда Y при изменении значений ряда Х.
3. Как изменяется среднее значение ряда Y при изменении значений ряда Х.*
42. Функция регрессии может быть выражена
1. Только линейной зависимостью.
2. Только экспоненциальной зависимостью.
3. Любой аналитической зависимостью.*
43. Уравнение линейной регрессии имеет вид
1.  , где
, где  и
и  .
.
2.  , где
, где  и .*
и .*
3. , где  и .
и .
44. График линейной регрессии
1. Всегда проходит через точку с координатами  .*
.*
2. Никогда не пересекается с осями координат.
3. Пересекает ось ОХ в точке А.
45. Корреляция может быть найдена
1. Только между двумя рядами признаков.
2. Только между двумя или тремя рядами признаков.
3. Между любым числом рядов.*
46. Временным рядом или рядом динамики называется статистическая совокупность, состоящая из
1. Случайных величин, которые описывают различные моменты или интервалы времени.
2. Случайных величин, которые являются параметрами динамических процессов (процессов движения).
3. Случайных величин, которые измеряются в разные моменты времени.*
47. Временной ряд характеризуется
1. Количеством значений и средним арифметическим всех показателей.
2. Показателями изменения уровней и средним значением показателей.*
3. Показателями изменения уровней и средним значением момента времени.
48. Тренд временного ряда – это
1. Линия, которая соединяет точки, описывающие уровни временного ряда.
2. Функция, которая описывает изменение времени.
3. Функция, которая описывает тенденцию изменения уровней.*
49. Аналитический метод нахождения тренда заключается
1. В отыскании формулы, которая описывает зависимость между моментом времени и уровнем ряда.*
2. В отыскании линии, которая проходит через точки уровней ряда.
3. В анализе характера изменений уровней ряда.
50. Прогнозирование временного ряда производится по
1. Вычислению возможных будущих моментов времени.
2. Значению тренда в будущий момент времени.*
3. Значению тренда в предыдущий момент времени.