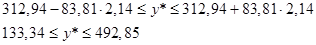1. Для построения корреляционного поля (или диаграммы рассеяния) используем Мастер диаграмм MS Excel. Для этого выделим «мышью» исходные наблюдения переменных X и Y, затем в Главном меню MS Excel выберем: Вставка – Диаграммы – Точечная – Точечная с маркерами. Полученная диаграмма рассеяния представлена на рисунке 1.

Рис. 1. Диаграмма рассеяния в MS Excel
Вывод 1: Как видно из рисунка 1, наблюдается прямая умеренная взаимосвязь между объемом продаж (Y) и расходами на рекламу (X). Точки на графике сосредоточены вокруг прямой линии, поэтому взаимосвязь между объемом продаж и расходами на рекламу уместно аппроксимировать прямой линией и применить линейную регрессию с одной объясняющей переменной.
2. Чтобы сформировать расчетную таблицу 1 (последовательно выполняя пункты 2-11 лабораторной работы), необходимо использовать Мастер формул MS Excel. В данном пункте достаточно заполнить столбцы X, Y, XY, X^2, Y^2. Основы работы с пакетом MS Excel изучаются в курсах информатики, поэтому мы не будем подробно останавливаться на описании интерфейса данной программы, а несколько позже рассмотрим лишь надстройку Анализ данных.
Таблица 1 – Подготовка данных для оценивания линейной регрессии объема продаж в зависимости от расходов на рекламу
| № пп. | X | Y | XY | X^2 | Y^2 | Yx | (Y-Yx)^2 | (Y-Yсред)^2 | (Yx-Yсред)^2 | Abs(E/Y) |
| 235,22 | 11928,89 | 32693,16 | 5125,56 | 0,87 | ||||||
| 4,8 | 657,6 | 23,04 | 246,04 | 11889,44 | 28836,29 | 3693,45 | 0,80 | |||
| 3,8 | 562,4 | 14,44 | 232,51 | 7142,72 | 25221,41 | 5520,17 | 0,57 | |||
| 8,7 | 1661,7 | 75,69 | 298,78 | 11617,09 | 13412,54 | 64,48 | 0,56 | |||
| 8,2 | 2246,8 | 67,24 | 292,02 | 324,74 | 1076,66 | 218,80 | 0,07 | |||
| 9,7 | 94,09 | 312,31 | 3328,52 | 3992,66 | 30,19 | 0,16 | ||||
| 14,7 | 6350,4 | 216,09 | 379,93 | 2711,60 | 15671,91 | 5345,73 | 0,12 | |||
| 18,7 | 8321,5 | 349,69 | 434,02 | 120,49 | 19095,79 | 16182,58 | 0,02 | |||
| 19,8 | 7266,6 | 392,04 | 448,90 | 6707,57 | 3622,54 | 20188,79 | 0,22 | |||
| 10,6 | 3890,2 | 112,36 | 324,48 | 1808,09 | 3622,54 | 312,08 | 0,12 | |||
| 8,6 | 2760,6 | 73,96 | 297,43 | 555,54 | 201,29 | 88,03 | 0,07 | |||
| 6,5 | 1995,5 | 42,25 | 269,03 | 1441,75 | 0,04 | 1427,55 | 0,12 | |||
| 12,6 | 4170,6 | 158,76 | 351,53 | 421,34 | 585,04 | 1999,34 | 0,06 | |||
| 6,5 | 2242,5 | 42,25 | 269,03 | 5771,50 | 1458,29 | 1427,55 | 0,22 | |||
| 5,8 | 2111,2 | 33,64 | 259,56 | 10907,13 | 3270,41 | 2232,54 | 0,29 | |||
| 5,7 | 2188,8 | 32,49 | 258,21 | 15823,03 | 5957,91 | 2362,17 | 0,33 | |||
| Сумма | 148,7 | 92499,43 | 158718,44 | 66219,00 | 4,60 | |||||
| Среднее | 9,29 | 306,81 | 3157,46 | 109,00 | 104053,8 | RSS | TSS | ESS |
3.. Суммы и средние по столбцам в таблице 1 необходимо определить с помощью функций СУММ(…) и СРЗНАЧ(…).
4. Оценки коэффициентов модели 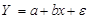 необходимо определить «вручную» ниже таблицы 1, используя ссылки на необходимые ячейки согласно формулам метода наименьших квадратов:
необходимо определить «вручную» ниже таблицы 1, используя ссылки на необходимые ячейки согласно формулам метода наименьших квадратов: 
Вывод 2: Запишем модель линейной регрессии:  . Экономическая интерпретация коэффициентов следующая. Увеличение расходов на рекламу (Х) на 1 тыс. рублей приводит при прочих равных условиях к увеличению объема продаж (Y)в среднем на 13,52 тыс. рублей. Данный результат согласуется с экономической интуицией, так как при росте расходов на рекламу можно ожидать увеличения объема продаж. При отсутствии расходов на рекламу объем продаж может составить 181,12 тыс.руб.
. Экономическая интерпретация коэффициентов следующая. Увеличение расходов на рекламу (Х) на 1 тыс. рублей приводит при прочих равных условиях к увеличению объема продаж (Y)в среднем на 13,52 тыс. рублей. Данный результат согласуется с экономической интуицией, так как при росте расходов на рекламу можно ожидать увеличения объема продаж. При отсутствии расходов на рекламу объем продаж может составить 181,12 тыс.руб.
5. Значения дисперсий для X и Y, а также средних квадратических отклонений X, Y необходимо определить «вручную» ниже таблицы, используя ссылки на необходимые ячейки согласно формулам: 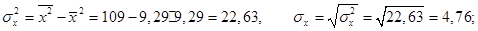
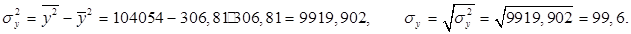 Необходимо проверить результаты с помощью функций ДИСПР(…) и СТАНДОТКЛОНП(…).
Необходимо проверить результаты с помощью функций ДИСПР(…) и СТАНДОТКЛОНП(…).
6. Значение линейного коэффициента парной корреляции необходимо определить «вручную» ниже таблицы 1, используя ссылки на необходимые ячейки согласно формуле:  Необходимо проверить результат с помощью функции КОРРЕЛ(…).
Необходимо проверить результат с помощью функции КОРРЕЛ(…).
Вывод 3: Согласно шкале Чеддока-Снедекора наблюдается умеренная прямая статистическая взаимосвязь между объемом продаж и расходами на рекламу.
7. Значение среднего коэффициента эластичности необходимо определить «вручную» ниже таблицы 1, используя ссылки на необходимые ячейки согласно формуле: 
Вывод 4: Увеличение расходов на рекламу на 1 % приводит к увеличению объема продаж на 0,41%.
8. Чтобы вычислить предсказанные моделью значения Yx в таблице 1, необходимо в уравнение регрессии  вместо x последовательно, начиная с первого, подставить наблюдаемые значения расходов на рекламу из таблицы 1. Полученные предсказанные моделью значения Yx указать в соответствующем столбце таблицы 1.
вместо x последовательно, начиная с первого, подставить наблюдаемые значения расходов на рекламу из таблицы 1. Полученные предсказанные моделью значения Yx указать в соответствующем столбце таблицы 1.
9. Остаток регрессии – это ошибка, несвязка (discrepancy) между наблюдаемым значением зависимой переменной Yi и предсказанными моделью значениями Yx. Чтобы вычислить остатки регрессии и их квадраты в таблице 1 необходимо заполнить столбец: (Y-Yx)^2.
10. Необходимо заполнить в таблице 1 столбцы (Y-Y_сред)^2, (Y_предск-Y_сред)^2.
11. Чтобы вычислить суммы квадратов отклонений (TSS, ESS, RSS), необходимо в таблице 1 в строке сумма применить функцию СУММ(…) к стобцам (Y-Y_сред)^2, (Y_предск-Y_сред)^2, (Y-Yx)^2.
Чтобы вычислить дисперсии на 1 степень свободы, надо использовать ссылки на необходимые ячейки согласно формулам:



12. Необходимо ниже таблицы 1 проверить балансовое соотношение для суммы квадратов отклонений: 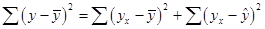
13. Значения коэффициента детерминации и индекса корреляции необходимо определить «вручную» ниже таблицы, используя ссылки на необходимые ячейки согласно формулам: 

Проверить с использованием коэффициента корреляции  и с помощью функции
и с помощью функции
КВПИРСОН(…).
Вывод 5: Доля дисперсии объема продаж, объясненная с помощью расходов на рекламу, составляет 42%. Чем ближе R2 к 1, тем лучше качество подгонки регрессии.
14. Чтобы рассчитать стандартную ошибку коэффициента регрессии и значение статистики Стьюдента, необходимо использовать ссылки на необходимые ячейки согласно формулам:


15. Для нахождения критического значения статистики Стьюдента удобно использовать функцию СТЬЮДРАСПОБР(…). В Главном меню MS Excel выберем: Формулы – Вставить функцию – Полный алфавитный перечень – СТЬЮДРАСПОБР(…).

Рис. 2. Диалоговое окно функции СТЬЮДРАСПОБР(…).
Вывод 6: Поскольку 3,17 > 2,98, то гипотеза Н0: β = 0 отвергается, т.е. согласно тесту Стьюдента коэффициент регрессии β является значимым. Это означает, что между переменными X (расходы на рекламу) и Y (объем продаж) существует значимая линейная связь.
16. Чтобы построить доверительный интервал для коэффициента регрессии на уровне значимости 0,01, необходимо, используя ссылки на необходимые ячейки, применить формулу:

Вывод 7: Диапазон границ доверительного интервала для коэффициента регрессии в модели с хорошим качеством подгонки обычно не превышает 3. В нашем случае,правая граница больше,чем левая, более чем в 3 раза, значит,качество подгонки модели рекомендуется улучшать.
17. Чтобы рассчитать значение статистики Фишера, необходимо использовать ссылки на необходимые ячейки согласно формуле: 
18. Чтобы проверить результат вычисления статистики с использованием коэффициента детерминации и статистики Стьюдента для β, необходимо использовать ссылки на необходимые ячейки согласно формулам: 
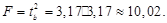
19. Для нахождения критического значения статистики Фишера удобно использовать функцию FРАСПОБР(…). В Главном меню MS Excel выберем: Формулы – Вставить функцию – Полный алфавитный перечень – FРАСПОБР(…).

Рис. 3. Диалоговое окно функции FРАСПОБР(…).
Вывод 8: Поскольку 10,02 > 4,60, то гипотеза Н0: β = 0 отвергается, т.е. согласно тесту Фишера регрессия адекватна. Это означает, что между переменными X (расходы на рекламу) и Y (объем продаж) существует значимая линейная связь.
Комментарий: В модели парной линейной регрессии не возникает вопрос о совокупном влиянии нескольких переменных, который актуален для множественной регрессии. Для того, чтобы определить, есть ли линейная зависимость между переменными X (расходы на рекламу) и Y (объем продаж), достаточно проверить значимость коэффициента β при переменной X по тесту Стьюдента. Поэтому для проверки адекватности парной регрессии достаточно выполнить только тест Стьюдента.
20. Чтобы проверить качество регрессии по средней относительной ошибке аппроксимации, необходимо в таблице 1 заполнить столбец Abs (E/Y) и использовать ссылки на необходимые ячейки согласно формуле: 
Вывод 9: Допустимый интервал средней ошибки аппроксимации – от 4% до 7%. Для построенной линейной парной регрессии средняя ошибка аппроксимации составила 28,74%, значит, качество подгонки модели рекомендуется улучшать, возможно, путем расширения модели до множественной регрессии через включение в нее дополнительных регрессоров.
21. Чтобы работать с надстройкой Анализ данных MS Excel, сначала ее надо подключить. Для этого нажмите Файл – Параметры. Далее в меню слева выберите Надстройки. Затем в разделе Управление выберите Надстройки Excel и нажмите кнопку Перейти (рис.4).

Рис. 4. Включение надстроек в Excel
В появившемся окне выберите надстройку Пакет анализа, поставив галочку напротив названия этого расширения (рис.5).

Рис. 5. Включение анализа данных в Excel
Теперь в главном меню программы на вкладке Данные (в верхней строке) появилась опция Анализ данных (рис.6). Ее мы и будем в дальнейшем использовать.


Рис.6. Кнопка Анализ данных в Excel
Нажав на кнопку Анализ данных, следует выбрать опцию Регрессия (рис.7).

Рис. 7. Выбор регрессионного анализа в Excel
На экране появится новое окно с опциями регрессионного анализа (рис.8).

Рис. 8. Окно параметров регрессии в Excel
В поле Входной интервал Y необходимо выбрать столбик, который будет отвечать за значения регрессанта – зависимой переменной (это может быть лишь один столбик). В графе Входной интервал X необходимо выбрать столбики, которые содержат значения регрессоров. Опция Метки, если в ней указать «галочку», трактует первую строку данных как названия переменных. Опция Константа – ноль позволяет строить модели без константы. Опция Уровень надежности позволяет установить значение 1-α для данной модели (где α – уровень значимости). В разделе Параметры вывода можно устанавливать, куда выводятся результаты регрессии (обычно выводят результаты на этот же лист, так как удобно держать данные и результаты оценки модели на одном листе). С помощью опции Остатки модели можно получить ряд остатков модели. С помощью опции Стандартизированные остатки вы можете получить ряд остатков, деленных на свое стандартное отклонение. График остатков отражает зависимость значения остатков от значений каждого регрессора. График подбора показывает зависимость фактических значений регрессанта от каждого регрессора и зависимость предсказанных значений регрессанта от каждого регрессора. Таким образом, благодаря этому графику можно судить о качестве подгонки модели. При построении графика нормальной вероятности по оси ординат откладываются значения регрессанта, а по оси абсцисс - процентили нормального распределения.
Чтобы оценить нашу регрессию в Excel в качестве регрессанта выберем переменную Y – объем продаж, а в качестве регрессора выберем переменную X – расходы на рекламу, укажем «галочку» в опции Метки, чтобы трактовать первую строку данных как названия переменных (рис.9).

Рис. 9. Окно параметров регрессии с введенными значениями в Excel
Далее, нажав на кнопку Ок, получаем результаты (рис.10).

Рис.10. Вывод результатов оценивания регрессии в Excel
Более подробно рассмотрим результаты, переведя их в обычные таблицы.
| Регрессионная статистика | ||||||||
| Множественный R | 0,64592 | |||||||
| R-квадрат | 0,417211 | |||||||
| Нормированный R-квадрат | 0,375583 | |||||||
| Стандартная ошибка | 81,28408 | |||||||
| Наблюдения | ||||||||
| Дисперсионный анализ | ||||||||
| df | SS | MS | F | Значимость F | ||||
| Регрессия | 10,0224 | 0,006872 | ||||||
| Остаток | 92499,43 | 6607,102 | ||||||
| Итого | 158718,4 | |||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |||
| Y-пересечение | 181,1232 | 44,60038 | 4,061023 | 0,001168 | 85,46486 | 276,7815 | ||
| X | 13,52407 | 4,271905 | 3,165817 | 0,006872 | 4,361745 | 22,6864 | ||
В подтаблице «Регрессионная статистика» Множественный R – это коэффициент корреляции между регрессантом и регрессором. Строкой ниже Excel выдает значение R2, равное 0,42. Чуть ниже можно увидеть значение нормированного (или, по-другому, скорректированного (adjusted) R2. Еще ниже указано значение Стандартной ошибки регрессии (MSE) – квадратного корня из остаточной дисперсии (пересечение столбца MS и строки Остаток по второй подтаблице), равное 81,28. В конце подтаблицы дано значение количества Наблюдений, равное 16.
В подтаблице «Дисперсионный анализ» во втором столбце df даны числа степеней свободы, в третьем столбце даны значения ESS, RSS и TSS (соответственно 66219; 92499,43; 158718,4). Четвертый столбик содержит отношения ESS/dfESS, RSS/dfRSS соответственно. F – это значение F-статистики теста Фишера для проверки значимости регрессии. В самом правом столбце дано значение p-value для этой статистики. Значение p-value позволяет провести тест (в данном случае тест Фишера), не пользуясь критическими значениями статистики. Если p-value для статистики меньше, чем α =0,1, то нулевая гипотеза отвергается с вероятностью 90%. Если p-value для статистики меньше, чем α =0,05, то нулевая гипотеза отвергается с вероятностью 95%. Если p-value для статистики меньше, чем α =0,01, то нулевая гипотеза отвергается с вероятностью 99%. В нашем случае p-value для статистики Фишера составило 0,007, что меньше, чем α =0,01. Это означает, что с вероятностью 99% отвергается нулевая гипотеза о незначимости уравнения регрессии. Согласно тесту Фишера регрессия адекватна, между переменными X и Y существует значимая линейная связь.
В нижней подтаблице в столбце «Коэффициенты» содержатся коэффициент регрессии, равный 13,52, а также свободный коэффициент, равный 181,12 на пересечении со строкой «Y-пересечение». В третьем столбце указаны стандартные ошибки коэффициентов, далее – значение t-статистики теста Стьюдента, затем дано значение p-value для этой статистики. В нашем случае p-value для статистики Стьюдента для коэффициента регрессии составило 0,007, что меньше, чем α =0,01. Это означает, что коэффициент регрессии β является значимым, между переменными X (расходы на рекламу) и Y (объем продаж) существует значимая линейная связь. Также p-value для статистики Стьюдента для свободного коэффициента составило 0,001, что меньше, чем α =0,01. Это означает, что свободный коэффициент α является значимым. В двух самых правых столбцах даны доверительные границы коэффициентов. В нашем случае, границы значение «ноль» не включают, что еще раз подтверждает статистическую значимость (отличие от нуля) коэффициентов уравнения регрессии.
Чтобы спрогнозировать расходы на рекламу в 1 квартале следующего года, надо среднее значение X увеличить на 5 %: 9,29*1,05 = 9,75 тыс. руб.
22. Получим прогноз объема продаж в 1 квартале следующего года: Yp = 181,12+13,52*9,75=312,94 тыс.руб.
23. Чтобы построить 95% -й интервал прогноза объема продаж в 1 квартале следующего года, необходимо использовать ссылки на необходимые ячейки согласно формуле:

В данной формуле  - стандартная ошибка прогноза. Ее можно определить для среднего прогнозного значения и для индивидуального прогнозного значения:
- стандартная ошибка прогноза. Ее можно определить для среднего прогнозного значения и для индивидуального прогнозного значения:
a) для среднего прогнозного значения:

Тогда доверительный интервал прогноза среднего объема продаж с вероятностью 95% составит:

b) для индивидуального прогнозного значения:

Тогда доверительный интервал прогноза индивидуального объема продаж с вероятностью 95% составит: