Семинар 4.
Тема: Технология MPI: Неблокирующий обмен данными
План:
· Введение
· Функции неблокирующего обмена данными между процессами. Пояснения и примеры.
· Задания
Введение
На предыдущих двух семинарах мы освоили 6 функций технологии MPI:
Функции общего назначения (4 штуки)
MPI_Init – инициализация работы с MPI
MPI_Finalize – завершение работы с MPI
MPI_Comm_rank – определение номера процесса
MPI_Comm_size – определение размера группы (количества процессов в группе)
Функции для обмена между отдельными процессами (2 штуки)
MPI_Send – блокирующая отправка данных процессу с заданным номером
MPI_Recv – блокирующий прием данных от процесса с заданным номером
Этот набор можно считать «прожиточным минимумом», поскольку с их помощью можно организовать распараллеливание практически любой задачи. Остальные функции библиотеки MPI (их более 200) облегчают этот процесс – упрощают написание программы и (или) оптимизируют ресурсозатраты на обмен между параллельными процессами.
Наша следующая задача – познакомиться с функциями неблокирующего (асинхронного) обмена.
Функции блокирующего обмена данными между отдельными процессами
Неблокирующая пересылка характеризуется тем, что процесс-отправитель и процесс-получатель сообщения осуществляют немедленный возврат из соответствующих MPI-функций и продолжают свою работу, не заботясь о том, отправлено ли (получено ли) сообщение. Таким образом, программа продолжает работу, в то время кА данные передаются своим чередом.
С одной стороны – экономится время на ожидание завершения передачи данных. С другой стороны – существует опасность некорректной работы программы.
Так, если в буфер, откуда отправляются данные, до завершения отправки будут записаны новые данные, т.е. произойдет искажение оправляемых данных – принимающий процесс получит не те данные, которые планировалось отправить.
Аналогично, если буфер, куда записываются поступающие данные, будет использован в расчетах до того, как данные реально приняты – это также приведет к ошибкам в работе программы.
Поэтому для проверки завершения приема-передачи данных существуют специальные тестовые функции.
Итак, чтобы воспользоваться неблокирующей пересылкой, процесс-отправитель должен вызвать функцию MPI_Isend. Она имеет вид:
int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request),
Параметры:
buf – адрес начала пересылаемых данных;
count – число пересылаемых элементов;
datatype – тип пересылаемых данных;
dest – номер процесса-получателя в группе, соответствующей коммуникатору comm;
tag – идентификатор сообщения;
comm – коммуникатор, связанный с группой процессов, в рамках которой идет пересылка;
request – «запрос обмена». Это выходной параметр, который должен быть инициирован до обращения к фукнции, тип данных MPI_Request.
Отметим: параметры MPI_Isend совпадают с параметрами функции блокирующей передачи MPI_Send, отличие лишь в дополнительном параметре request, по которому осуществляется проверка завершения передачи данных.
Для организации неблокирующего приема используется функция MPI_Irecv, которую вызывает процесс-адресат. Она имеет следующий вид:
int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request),
Параметры:
buf – адрес начала расположения принимаемых данных;
count – максимальное число принимаемых элементов;
datatype – тип принимаемых данных;
source – номер процесса-отправителя в группе, соответству-ющей коммуникатору comm;
tag – идентификатор сообщения;
comm – коммуникатор, связанный с группой процессов, в рам-ках которой идет пересылка;
request – «запрос обмена».
Отметим, что функции блокирующего и неблокирующего приема/передачи полностью совместимы между собой и с другими MPI-функциями обмена «точка-точка», т.е. можно осуществить отправку данных с помощью блокирующей функции MPI_Send, а прием организовать с помощью неблокирующей функции MPI_Irecv и наоборот.
Определить окончание приема\передачи можно с помощью функций MPI_Wait или MPI_Test с соответствующим параметром request.
Функция MPI_Wait блокирует дальнейшую работу вызвавшего ее процесса до успешного принятия\отправки данных, соответствующих параметру request. Процедура имеет следующий вид:
int MPI_Wait(MPI_Request *request, MPI_Status *status),
где request – «запрос обмена»; status – атрибут сообщения;
Функция MPI_Test выдает признак завершенности операции приема\передачи, соответствующей параметру request (flag=0, если процесс приема\передачи завершен, и flag=1, если не завершен). Процедура вызывается следующим образом:
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status),
где request – «запрос обмена»;
flag – признак завершенности проверяемой операции;
status – атрибут сообщения.
Пример
Рассмотрим использование неблокирующих функций приема/передачи на примере, рассмотренном на прошлом семинаре.
Итак, пусть в нашей программе, выполняемой группой процессов в количестве np, каждый из процессов объявляет целочисленную переменную а и присвоил ей значение 1. Далее, процесс с номером id=0 присваивает своей локальной переменной значение а=10 и пересылает это значение процессу id=1.
В итоге, в процессах с номерами 0 и 1 должны иметь а=10, а в остальных процессах группы по-прежнему будет а=1. Это должно быть видно на печати.
Номер процесса id=0id=1 … id=np-1
1й шаг (старт) int a=1; int a=1; … int a=1;
2й шаг a=10; a=1; … a=1;
3й шаг (пересылка)
4й шаг (итог) a=10; a=10; … a=1;
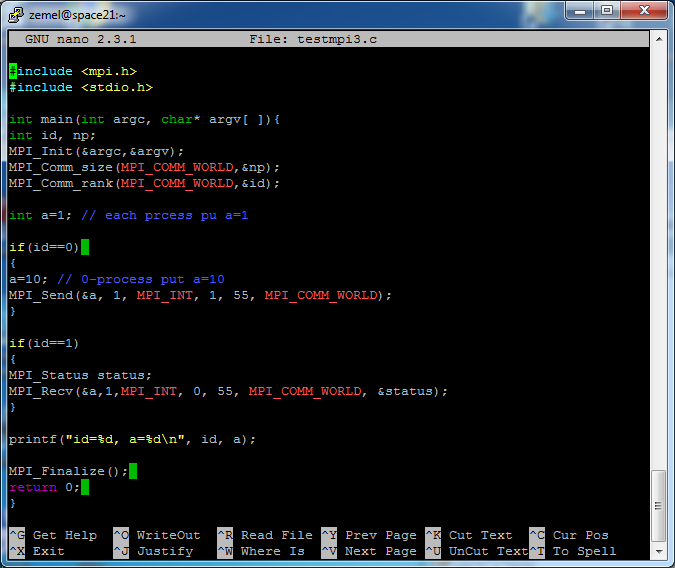
Для начала просто заменим функции MPI_Send, MPI_Recv на MPI_Isend, MPI_Irecv. Также необходимо объявить параметр request.
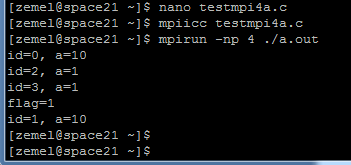
Результат запуска программы для 4 процессов:
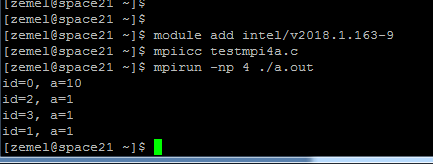
Видно, что только в процессе с номером 0 а=10. Процесс с номером 1 имеет а=1, поскольку прием происходит с помощью неблокирующей функции с немедленным возвратом в вызвавшую ее программу, т.е. печать переменной а произошла до того, как по этому адресу пришло новое значение 10.
Чтобы добиться корректной работы программы (т.е. печати нового значения а=10 в 1м процессе), необходимо использовать функции тестирования. Сделаем это следующим образом: 1й процесс вызывает функцию MPI_Test и выводит на экран значение флага. Если флаг равен 1, т.е. прием не завершен – вызывается функция MPI_Wait, обеспечивающая ожидание завершения обмена.
Отметим, что в принципе в данном случае достаточно было бы использовать только функцию MPI_Wait.
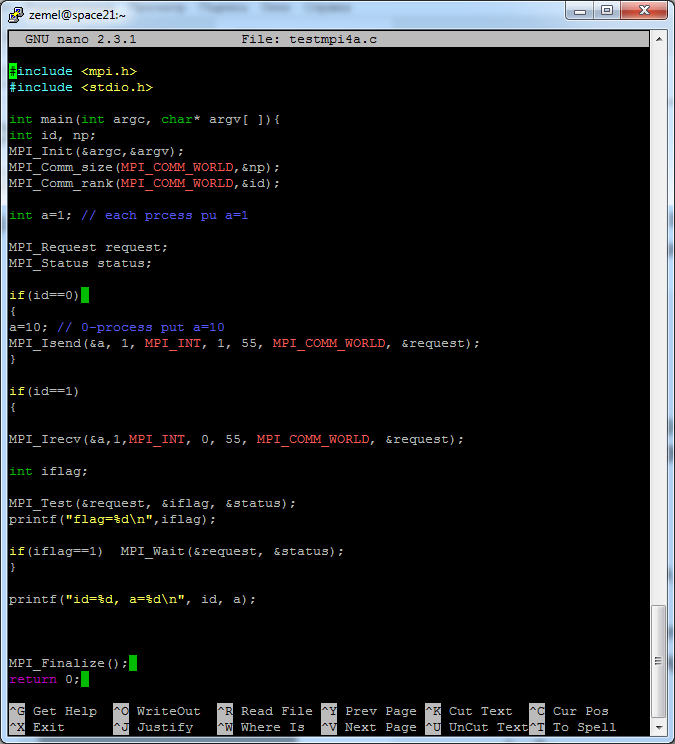
Видим, что после возврата из MPI_Irecv флаг равен 1, т.е. прием не завершен, но поскольку мы вызвали функцию MPI_Wait ожидания завершения обмена, то печать значений а происходит после завершения приема, так что процесс номер 1 выводит на печать а=10.
Задания:
1. Изучить в учебном пособии по MPI раздел 2.4.2 Главы 2.
2. Воспроизвести и запустить на кластере HybriLIT рассмотренный пример.
3. Модифицировать программу в рассмотренном примере так, чтобы отправка а=10 из 0-процесса осуществлялась с помощью блокирующей функции MPI_Send.
4. Разобрать и воспроизвести на кластере пример из раздела 2.4.2 с печатью результата пересылки.