Являясь незаменимым приёмом получения информации, интервью даёт возможность исследовать лишь субъективный мир людей, их склонности, мотивы деятельности, мнения. Важнейшую роль в данном виде опроса играет личность интервьюера. Фальсификация, недобросовестность, исключительная навязчивость, принуждение респондентов к участию в опросе, как правило, меняют не только детали, но и общее представление об итогах исследования.
Метод интервью, не будучи свободен от недостатков, тем не менее, весьма привлекателен для исследователей, так как является несомненно лучшим источником знания о внутренних побуждениях людей, который при соблюдении надлежащих предосторожностей, позволяет получить надёжную информацию о событиях прошлого или настоящего, о результатах человеческой деятельности.
Часто исследовательские ситуации связаны с практикой прогнозирования изменения социальных процессов, и самооценка людей в этом случае может оказаться недостаточной, либо искаженной. Такая информация может быть получена только от особо компетентных лиц - экспертов. И в этих ситуациях используют другую разновидность опроса - экспертный.
При подготовке исследования с применением метода экспертного опроса, прежде всего возникает задача формирования группы экспертов. На самом первом этапе формирования экспертов в качестве критериев их отбора целесообразно использовать род занятий и стаж работы по интересующему профилю. При необходимости учитывают также уровень и характер образования, возраст. Первоначальный список экспертов может быть достаточно обширным, затем он может сужаться, так как не каждый человек способен выступить в качестве эксперта.
|
|
Центральный критерий отбора экспертов – их компетентность. Для ее определения применимы два метода – самооценка экспертов и коллективная оценка их авторитетности. Наиболее простая и коллективная форма самооценки – совокупный индекс, рассчитанный на основании оценки экспертами своих знаний, опыта и способностей по ранговой шкале с позициями "высокий", "средний", "низкий". При этом первой позиции приписывается числовое значение "1", второй - "0,5", третьей - "0".
2. Особое место занимают в прикладной политологии статистические методы. В процессе анализа данных осуществляются следующие операции: расчет одномерного распределения признаков, построение группировок признаков, выявление зависимостей между признаками. При обработке данных прежде всего выявляют одномерные распределения признаков (частоты появления различных значений этих признаков в полученном массиве данных). На основе изучения этого распределения можно получить лишь предварительную информацию об отношении к правительству, к проводимой им политике. Для всесторонней его оценки важно выяснить специфику распределения ответов на указанный вопрос у представителей различных социальных групп, включенных в выборку исследования: руководителей, специалистов, предпринимателей, военнослужащих, рабочих, учащихся, студентов, пенсионеров, безработных. Первым шагом на этом пути служит построение таблиц сопряженности (двумерных распределений) признаков. Анализ этих распределений обнаруживает, что руководители и служащие управленческого аппарата сильнее доверяют правительству, чем, например, рабочие, а среди последних преобладают люди, однозначно не доверяющие правительству. Это уже более точная характеристика отношения населения к правительству. На основе двумерных распределений признаков можно строить различные группировки опрошенных в соответствии с их социальными характеристиками (профессия, квалификация, доход, образование и пр.). В итоге получаются простые и комбинированные таблицы данных, а также графики, диаграммы, гистограммы и др.
|
|
Однако все эти процедуры на самом деле представляют собой лишь подготовку к настоящему анализу данных. Главное в этом анализе — выявление зависимостей между признаками. Основными методами изучения зависимостей являются анализ статистических таблиц, корреляционный, факторный, кластерный анализ и многомерное шкалирование.
Анализ статистических таблиц основан на оценке отсутствия/наличия взаимосвязи признаков по критерию хи-квадрат и вычислении стандартизованных остатков (величин, которые указывают на степень отклонения наблюдаемых частот от ожидаемых)[50]. Вычисление критерия хи-квадрат и стандартизованных остатков осуществляется с помощью пакета SPSS (опции: statistics\crosstabs). Показателем наличия взаимосвязи признаков служит значение критерия хи-квадрат, превышающее табличное[51] для соответствующего числа степеней свободы — df значение выдается SPSS в результатах (output) вместе со значением хи-квадрат) и уровня значимости. Принимаются во внимание абсолютные значения остатков, превышающие 1,65. Это служит индикатором существования значимой статистической зависимости между изучаемыми признаками. Знак "плюс" в стандартизованных остатках свидетельствует о том, что реальное количество наблюдений больше ожидаемого, знак "минус" — о том, что оно меньше ожидаемого. Следует учитывать, что величина стандартизованных остатков указывает лишь на вероятность наличия линейной зависимости между изучаемыми переменными, но не на направление и интенсивность этой зависимости.
|
|
Результаты анализа статистических таблиц дают возможность сформулировать гипотезы относительно взаимосвязи признаков изучаемого явления, нуждающихся в дополнительной проверке с помощью статистических методов, о которых пойдет речь далее.
Корреляционный анализ основан на расчете отклонения значений изучаемого признака от линии регрессии (от лат. regressio — возврат, в данном случае — возврат к средней) — условной линии, к которой эти значения тяготеют. Чем больше разброс значений, тем слабее связь двух интересующих нас признаков. Чем меньше разброс значений, тем сильнее связь (рис.1).

Рис. 1. Варианты рассеяния значений
Корреляция (от лат. cotrelatio — соотношение) — это статистическая взаимозависимость между признаками изучаемого явления. Корреляционный анализ представляет собой математическую процедуру, с помощью которой изучается эта взаимозависимость. Он заключается в вычислении коэффициентов корреляции — чисел, знак и величина которых характеризуют направление (прямая/обратная) и интенсивность/тесноту (строгая, сильная, умеренная, нулевая) взаимозависимости. Показателем интенсивности связи служит значение коэффициента. Считается, что если он равен 1, то взаимозависимость признаков является строгой (полной); если его значение находится в интервале от 1 до 0,8, то это свидетельствует о сильной их взаимозависимости; если в интервале от 0,7 до 0,3 — об умеренной (неярко выраженной) взаимозависимости, а если же оно лежит в интервале от 0,2 до 0,0, то мы имеем дело со слабой или нулевой взаимозависимостью[52]. Есть мнение, что в социологических исследованиях значения коэффициентов корреляции выше 0,5 встречаются не очень часто, поэтому можно принимать во внимание те из них, которые равны или превышают 0,3[53], т. е. характеризуют умеренную взаимосвязь признаков.
Следует отметить, что коэффициенты корреляции выражают не причинную (обусловленность одного признака другим), а функциональную (взаимная согласованность изменения признаков) зависимость между признаками[54]. Различают парную (между двумя признаками) и множественную (между несколькими признаками) корреляции.
Для изучения взаимосвязи признаков, измеренных с помощью различных типов шкал, используются разные коэффициенты корреляции. На порядковом уровне измерения признаков наиболее широко применяется коэффициент ранговой корреляции Спирмена, на интервальном уровне обычно используется коэффициент корреляции Пирсона. Коэффициент Спирмена равен +1, когда два ряда проранжированы строго в одном порядке, - 1, когда два ряда проранжированы в строго обратном порядке, и равен нулю при полном взаимном беспорядочном расположении рангов.
Коэффициент корреляции Пирсона равен +1 при строгой (полной) прямой взаимозависимости двух признаков (увеличение/уменьшение значений одного признака сопровождается увеличением/уменьшением значений второго признака). Он равен - 1 при строгой (полной) обратной взаимозависимости (увеличение/уменьшение значений одного признака сопровождается уменьшением/увеличением значений второго признака). Наконец, величина этого коэффициента равна нулю при отсутствии взаимозависимости признаков. Об интерпретации значений коэффициентов корреляции, отличных от 1 и 0, говорилось в начале этого параграфа.
Высокие значения (больше 0,4) коэффициента корреляции свидетельствуют о наличии линейной связи между голосованием за сравниваемые партии и блоки. Знак "минус" означает, что чем больше голосов определенная группа избирателей отдает за одну из сравниваемых партий, тем меньше она отдает голосов за другую. Знак "плюс" означает, что чем больше голосов группа избирателей отдает одной партии, тем больше она отдает голосов и другой сравниваемой партии. Значения r < 0,4 свидетельствуют лишь о слабой выраженности линейной связи между голосованием за разные партии, но это не исключает наличия другой формы связи (нелинейной). Сам факт положительной или отрицательной корреляции говорит только о возможном механизме перераспределения голосов избирателей между партиями и блоками, а не о сходстве или различии их политических позиций.
Как правило, на признаки изучаемого явления влияет множество причин, поэтому для выявления полной картины недостаточно только анализа парных корреляций, нужна группировка этих корреляций и выявление на этой основе комплексов скрытых (латентных) переменных, которые называются факторами (рис. 2).
Необходимость факторного анализа обусловлена тем, что мы не можем воспринимать большое число сопоставляемых пар признаков и вынуждены прибегать к помощи вычислительной техники. Факторный анализ основан на измерении доли влияния каждого из выделенных нами комплексов (независимых) переменных на изменение изучаемых признаков явления (зависимых переменных) и обнаружении причинной обусловленности этих изменений. Факторы выражают внутренние (скрытые) свойства системы переменных, характеризующих изучаемое явление.

Рис. 2. Графическая структура факторного анализа
Исходной информацией факторного анализа служит матрица (система чисел, размещенных в прямоугольной таблице в виде п столбцов и т строк) парных коэффициентов корреляции всех отобранных нами переменных. На основе матрицы выявляются скопления переменных, тесно связанных друг с другом и слабо связанных с переменными, входящими в другие скопления. Эти скопления переменных образуют факторы (рис. 3).

Рис. 3. Группировка переменных в пространстве двух факторов
Первый фактор (горизонтальная ось графика) образуют переменные, характеризующие ориентации на коммунизм или либерализм. Второй фактор (вертикальная ось графика) образуют ориентации на власть или оппозицию. Следует учесть, что данная структура существовала в сознании населения Санкт-Петербурга на момент опроса (ноябрь 2000 г.). Со временем эта конфигурация переменных может измениться.
Целью факторного анализа служит выявление так называемой простой структуры. В каждой строке факторной матрицы должно быть хотя бы одно нулевое значение (нулевыми считаются также значения, первый разряд которых начинается с 1).
В каждом столбце факторной матрицы число нулевых значений должно быть не меньше числа факторов.
В каждой паре столбцов должно быть несколько переменных, которые имеют значения, равные нулю в одном из столбцов и не равные нулю — в другом.
В каждой паре столбцов имеется мало переменных, значения которых в обоих из них отличны от нуля.
Переменные для факторного анализа отбираются в соответствии с определенными критериями. Считается, что эти переменные должны быть измерены с помощью интервальной шкалы[55]. Для порядковых переменных не существует факторных моделей, поскольку операции сложения для них невозможны. Надо иметь в виду, что в данном случае "допускается лишь эвристическое использование таких моделей без статистической интерпретации результатов". Это значит, что можно подвергать факторному анализу переменные, измеренные с помощью порядковых шкал, однако в данном случае нельзя оперировать собственными значениями факторов и определять более и менее значимые факторы.
На порядковом уровне с помощью факторного анализа можно лишь устанавливать кластерную структуру переменных. Часто предполагается, что порядковым переменным можно присваивать числовые значения, не нарушая их внутренних свойств. Например, можно присвоить числовые значения 5, 4, 3, 2, 1 позициям порядковой шкалы: целиком согласен, согласен, безразличен, не согласен, полностью не согласен. "Если искажения корреляций, вносимые при шкалировании порядковых переменных, не слишком велики, вполне законно использовать эти переменные в качестве числовых"[56]. В отечественной социологии такие случаи встречаются довольно часто. Считается, что если основой факторного анализа служит матрица корреляций, а данные, полученные на порядковых шкалах, позволяют подсчитывать коэффициенты корреляции, то это дает право использовать факторный анализ, но с учетом отмеченного выше ограничения — недопустимости статистической интерпретации собственных значений выделенных факторов. Здесь приходится ограничиваться лишь выявлением распределения переменных по скоплениям (кластерам).
Существует множество методов факторного анализа. Наиболее часто используется метод главных компонент. В нем факторы являются линейными функциями от наблюдаемых переменных. Задача в данном случае заключается не в объяснении корреляций между переменными, а в объяснении доли каждого скопления независимых переменных в дисперсии (отклонении от средней) интересующей нас зависимой переменной. В процессе факторного анализа определенная последовательность наблюдаемых переменных преобразуется в другую последовательность. Сначала вычисляются парные коэффициенты корреляции между переменными и строится корреляционная матрица, которая образует основу факторного анализа. Затем последовательно строится матрица компонент. При двухфакторном анализе первая компонента определяется таким образом, чтобы в ней содержалась максимальная доля дисперсии изучаемой переменной. Вторая компонента определяется аналогичным образом, но ее ось должна располагаться перпендикулярно первой. Выделенные компоненты должны объяснять не менее 50% суммарной дисперсии изучаемой переменной (например, мотивации голосования за определенного кандидата в президенты). При трехфакторном анализе принцип определения главных компонент тот же самый, что и при двухфакторном: ось второй компоненты располагается перпендикулярно первой, ось третьей компоненты — перпендикулярно двум первым (рис. 4). Число переменных, отобранных для факторного анализа, должно превышать число факторов не менее, чем в два раза. В каждом факторе должно быть не менее трех переменных с максимальными значениями коэффициентов[57].

Рис. 4. Группировка переменных в пространстве трех факторов (приверженность взглядам и голосование за избирательные объединения)
На первом этапе анализа определяется минимальное число факторов, адекватно воспроизводящих наблюдаемые корреляции. После этого осуществляется процедура вращения, с помощью которой устанавливаются легко интерпретируемые факторы. Графический способ вращения заключается в проведении новых осей, которые обеспечивают воспроизводство вышеупомянутой простой структуры. Если после вращения обнаруживаются скопления точек (значений переменных), явно отделенных друг от друга, то это означает, что нам удалось провести оси через эти скопления.
Аналитический способ вращения осуществляется на основе определенного объективного критерия. Этот способ включает два вида вращения: ортогональное и косоугольное. Наиболее часто используется ортогональное вращение с помощью метода варимакс (поиск максимальных значений 1-го фактора). Метод основан на упрощении описания столбцов факторной матрицы, в результате чего достигается лучшее разделение факторов (четче выделяется главный фактор). Целью любого способа вращения является получение наиболее простой факторной структуры, которая легче поддается содержательной интерпретации. Число факторов определяется с помощью различных критериев.
Критерий собственных чисел: отбираются факторы с собственными числами, превышающими 1, остальные не принимаются во внимание.
Критерий воспроизводимой дисперсии: обычно отбирают факторы, объясняющие 50 — 60% общей дисперсии изучаемой переменной.
Критерий отсеивания: на графическом изображении собственных чисел корреляционной матрицы заканчивают отбор на том факторе, после которого кривая принимает вид, близкий к горизонтальному (рис. 5).

Рис. 5. Распределение весовых значений компонент
Интерпретация результатов факторного анализа означает перевод с одного языка на другой, в данном случае с языка цифр на язык слов, с языка статистики на язык социологии. Следует помнить, что факторный анализ — это не конец описания и объяснения результатов социологического исследования, а основа дляформулирования гипотез, которые подлежат проверке, в том числе и путем повторного факторного анализа.
Выявив перечни переменных, относящихся к каждому фактору, мы должны проанализировать их содержание, подобрать обобщающее название для этого фактора. Подбор названия фактора означает поиск среди известных социологу понятий того понятия, которое в наибольшей степени соответствует конфигурации переменных в их скоплении. Следует учитывать, что "матрица корреляций может быть факторизована бесчисленным количеством способов"[58]. Отбор наиболее подходящего способа осуществляется на основе содержательных критериев (концепции, гипотез, целей и задач исследования, сформулированных в его программе). Поэтому чисто статистическая процедура всегда должна сопровождаться качественным анализом полученных результатов.
Знаки "плюс" и "минус" факторных значений интерпретируются как увеличение или уменьшение значения переменной, т.е. просто как разные направления. "Знак факторных нагрузок сам по себе не имеет внутреннего содержания и не несет информации о зависимости между переменной и фактором. Однако стоит сопоставлять знаки разных переменных при одном факторе"[59]. Факторные нагрузки меньше 0,3 считаются несущественными[60]. Интерпретация факторов сводится к анализу величины и знаков нагрузок. Рассмотрим эту процедуру на примере приведенного выше двухфакторного решения (см. рис. 3). Два выделенных фактора объясняют 61% дисперсии и включают переменные, указанные в табл. 5.
Кластерный анализ (от англ. cluster — пучок, группа) — это процедура, позволяющая классифицировать различные объекты. С его помощью можно разбить респондентов на группы, сходные по ряду признаков. На дендрограмме "дерева признаков" признаки соединяются линиями, образуя отдельные пучки ("ветви"), связанные с другими пучками ("ветвями"). Эти пучки и называют кластерами. Чем короче линия, связывающая переменные, тем ближе они находятся в пространстве признаков. В процессе кластеризации происходит объединение сходных объектов во все более сложные группы ("разветвление"). Кластерный анализ представляет собой разновидность многомерной статистической процедуры, упорядочивающей объекты в относительно однородные группы. Переменные для кластерного анализа выбираются в соответствии с теорией (концепции, гипотезы), которая лежит в основе классификации[61]. Перед началом анализа они должны быть преобразованы в биноминальные, принимающие значение "1" при наличии признака и "0" при его отсутствии. Кроме того, из анализа следует исключить альтернативы: "затрудняюсь ответить" "другое" и пр.
Важную роль в кластерном анализе играют "меры сходства" Наиболее часто в качестве такой меры употребляется коэффициент корреляции Пирсона, первоначально использовавшийся для определения зависимости переменных. Кластеры обладают рядом свойств, среди которых наиболее важными являются плотность, дисперсия, форма, отдельность. Плотность — это близость отдельных точек скопления, позволяющая отличать его от других областей многомерного пространства, содержащих либо мало точек, либо не содержащих их совсем. Дисперсия характеризует степень рассеяния точек в пространстве относительно центра кластера. Отдельность характеризует взаимное расположение скоплений точек в пространстве[62]. Кластеры можно рассматривать как "непрерывные области пространства с относительно высокой плотностью точек, отделенные от других таких же областей областями с относительно низкой плотностью точек"[63].
Наиболее известными методами кластерного анализы являются методы одиночной, полной и средней связи, а также метод Уорда[64]. Метод Уорда (Ward's method) позволяет создавать кластеры приблизительно равных размеров[65]. Он сначала объединяет самые близкие объекты, затем к уже образованным кластерам присоединяются сходные с ними объекты. Мерой сходства в данном случае является 1 — коэффициент корреляции Пирсона.
На основе анализа содержания переменных, входящих в отдельные кластеры, строится группировка респондентов по признакам, включенным в процесс кластеризации.
Кластерный анализ основных альтернатив ответа на вопрос о том, за кого намерены голосовать респонденты и вопрос о мотивах предстоящего голосования позволили, например, обнаружить особые структуры мотивации электорального выбора у сторонников отдельных кандидатов в Президенты России.
Многомерное шкалирование представляет собой процедуру, с помощью которой оценивается степень сходства/различия между переменными. С его помощью мы можем представить набор изучаемых переменных в виде скоплений точек (каждой переменной соответствует одна точка). Этот метод позволяет находить в массиве данных комплексы сходных друг с другом и отличающихся друг от друга переменных. В геометрическом пространстве сходные переменные (тесно связанные между собой в сознании респондентов) располагаются близко друг от друга и образуют скопления точек, отделенные пустым пространством от других скоплений сходных переменных. Чем больше сходства зафиксировано у изучаемых переменных, тем ближе находятся обозначающие их точки на графике. Чем меньше сходства наблюдается у включенных в анализ переменных, тем дальше друг от друга располагаются соответствующие им точки на графике.
Данный метод дает возможность наглядно (на графике) представить множество переменных и увидеть особенности их конфигурации в геометрическом пространстве (чаще всего в двумерном). Подобная процедура используется при сопоставлении значительного числа переменных, которое трудно анализировать без визуализации. Перед началом многомерного шкалирования осуществляется процедура преобразования переменных в биноминальные, как и в кластерном анализе.
Рассмотрим пример такой визуализации на основе набора переменных, характеризующих идентификацию респондентов с различными взглядами
На графике рис. 7 видны четыре группы точек, отделенных друг от друга пустым пространством. Эти группы располагаются в рамках двух измерений. Первое измерение основано на противопоставлении власти и общественности, второе — на противопоставлении коммунизма и либерализма.
Специфическим методом обработки информации является вторичный анализ данных. Он применяется для получения дополнительной информации по уже прошедшему первичную обработку массиву данных. Обычно вторичный анализ используют при повторной обработке результатов "чужих" или собственных исследований. Можно выделить два типа вторичного анализа: монографический и сравнительный. В первом случае осуществляется повторный анализ одного массива первичных данных, во втором — сопоставляются несколько массивов первичных данных (например, электронные таблицы данных в системе SPSS), полученные отдельными социологическими центрами в разное время, на разных выборках и по различным программам. Разнотипность исследований и используемых в них переменных порождает необходимость их стандартизации как условия сопоставимости результатов исследований.
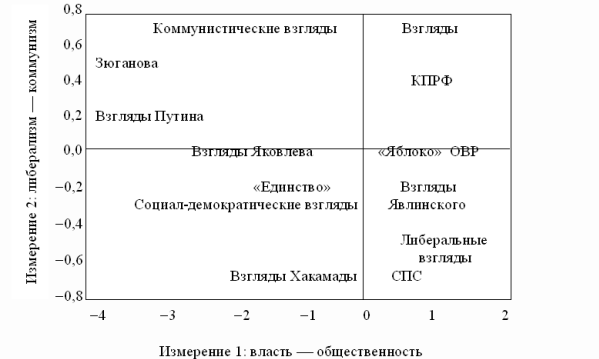
Рис. 7. Конфигурация переменных в пространстве двух измерений (политическая идентификация и партийные предпочтения на выборах)
Сопоставлять можно лишь однородные переменные, но для обеспечения этой однородности нужно, чтобы сравниваемые первичные данные по этим переменным были получены на однотипных выборках, одинаковыми методами и с помощью однотипных шкал. Если у нас нет информации о том, кого и как репрезентирует выборка, какие методы были использованы для сбора и анализа данных, как были сформулированы вопросы и какие альтернативы предлагались респондентам для ответа на них, то вторичный анализ становится невозможным.
Нельзя в строгом смысле слова назвать вторичным анализом часто используемое сопоставление частотных распределений внешне сходных переменных, взятых из отчетов по итогам массовых опросов населения, опубликованных в научных изданиях или газетах. Как правило, в этом случае авторы не выясняют степень однородности сравниваемых массивов информации, а между тем за каждым числовым значением признака стоит определенное качество. Не выяснив, насколько однородна качественная определенность переменных, отобранных из разных массивов данных, мы не можем их сопоставлять.
Для проведения вторичного анализа необходимо изучить описание выполненных исследовательских проектов, по которым имеется первичная информация в существующих отечественных и зарубежных архивах данных[66]. В архивах нужно отобрать необходимые массивы данных, получить разрешение на их использование от руководства соответствующих центров и, сделав с них копии файлов, провести вторичный анализ.
Можно выделить несколько видов сравнительного вторичного анализа: сравнительно-типологический (синхронный), или анализ первичных данных исследований, проведенных в одно и то же время; сравнительно-генетический (диахронный), или анализ результатов исследований, проведенных в разное время. В любом случае предварительное изучение переменных с целью определения степени их однородности и пригодности для сравнения представляет собой обязательное условие вторичного анализа. Важно отметить и то, что в процессе вторичного анализа мы, по существу, мысленно воспроизводим все этапы сопоставляемых исследований и одновременно осуществляем самостоятельное исследование, в ходе которого концептуализируем изучаемую проблему, выдвигаем собственные гипотезы, операционализируем понятия и т.д. Вторичный анализ означает новое, дополнительное исследование старых массивов первичных данных.
Технологии сбора и обработки данных, основанные на использовании количественных (основанных на измерении параметров политического действия) и качественных (основанных на понимании смысла явлений политического действия) методов существенно отличаются
Политические прогнозы – научно обоснованные суждения о вероятностных состояниях политической системы или отдельных ее субъектов в будущем и вероятных путях и сроках их достижения, которые имеют четко обозначенный период упреждения и тесно связаны с возможностью оперативной реакции на них в виде политических решений
Говоря о классификации прогнозов, выделим по целевому критерию поисковый и нормативный прогнозы Основной целью поискового является определение возможного состояния объекта в будущем, речь идет об условном продолжении существующих в настоящих момент тенденций. Задача нормативного определить пути и сроки достижения желательных результатов на основе заранее заданных ресурсных и прочих ограничений.
Также различают активные и пассивные прогнозы. Первые оказываю существенное влияние на процесс, который прогнозируют, а вторые на него не влияют.
С точки зрения воздействия прогнозов на объект прогнозирования различают самосбывающиеся и самоопровергающиеся прогнозы. В первом случае прогноз имеет настолько сильное воздействие, что сбывается, несмотря на отсутствие реальных предпосылок для этого. Наоборот, самоопровергающиеся прогнозы не реализуются на практике, хотя именно в этом и состоит их задача. Для них важно показать негативные последствия осуществления возможных вариантов развития политической ситуации, для того, чтобы лица, принимающие решения, могли сосредоточить на данной проблеме повышенное внимание и предотвратить нежелательные последствия.
Существует различная классификация методов прогнозирования методы можно разделить на 2 основные группы: основанные на логических суждениях и использующие известную статистическую информацию. Основанные на логических суждениях подразделяются на ролевые (если принимаются решения экспертами без чьей – либо помощи) и неролевые.
Если процесс, в отношении которого выносятся прогнозные суждения не зависит от участия экспертов, то применяемые методы подразделяются на неструктурированные и структурированные. Неструктурированные используют независимые логические суждения. К структурированным относятся метод Дельфи, метод структурированных аналогий, методы теории игр, методы деком позиции, использование экспертных систем.
Методы, использующие известную статистическую информацию, подразделяются на одновариантные и многовариантные. Одновариантные используют технологии эксраполяции. Многовариантные основываются на имеющихся данных и их смысловом анализе или теориях.
Часто используются методы сценарного прогноза и форсайт. Сценарный прогноз предусматривает расчленение политической ситуации на различные составляющие для определения альтернатив ее развития. Форсайт. использовался впервые в Японии еще в 70 гг. для построения долгосрочного прогноза. Включал несколько тысяч экспертов.
В прогнозировании наиболее наглядно проявляется отличие экспертной оценки от информации, получаемой в результате массового опроса. Оно заключается в стремлении к согласованности, единообразию суждений, оценок, высказываемых экспертами. Например, возможно ли использовать мнение 30 экспертов, если ими представлено, скажем 5-7 взаимоисключающих прогностических оценок. Также достоверность данных при массовом опросе тем выше, чем больше совокупность опрошенных. В экспертном опросе в связи с высокой компетентностью лиц мнение даже одного эксперта, а тем более группы экспертов может оказаться обоснованным и достоверным.
Прогностическая оценка экспертов может применяться для прогноза любых социальных явлений. Но прогностическая оценка может касаться не только общественных проблем макроуровня. В каждом коллективе эксперты могут оценивать проблемы организационного уровня. В отличие от массового опроса программа прогнозного опроса экспертов не настолько детализирована и носит концептуальный характер. В ней однозначно формулируется явление, которое прогнозируют, предусматриваются вариант его развития в виде гипотез.
В анкету для экспертов включаются различные виды вопросов. Если исследователь располагает информацией только о возможных вариантах исхода прогнозируемого явления и затрудняется однозначно сформулировать их причины, лучше в анкете эксперта использовать открытые вопросы с полной свободой выбора формы ответа.
Опрос экспертов может быть очным и заочным (почтовый опрос, телефонное интервью). Одна из наиболее простых форм экспертного опроса – обмен мнениями. Он может проходить в форме заседания "круглого стола", где происходит выявление позиций экспертов.
Возможен и другой способ организации дискуссии экспертов – ролевая игра. В группу экспертов можно включить подгруппу “генераторов идей”, активно выдвигающих различные предположения о социальном явлении или процессах; "регуляторов", следящих за тем, чтобы полемика не приобрела хаотичный характер, проходила в рамках объективного обсуждения и не переходила во взаимную оценку компетентности друг друга; подгруппу "селекторов", оценивающих и отбирающих наиболее значимые идеи, выдвигаемые "генераторами идей", подгруппу "стимуляторов" путем формулировки все новых предположений "стимулирующих и генераторов идей" к выработке различных оценок и "президента круглого стола", удерживающего внимание экспертов. Примерное число экспертов-20-25 человек.
Достаточно часто применяется метод "дельфийской техники". Она заключается в выработке согласованных мнений путем многократного повторения опроса одних и тех же экспертов. После первого опроса и обобщения результатов, его итоги сообщаются участникам экспертной группы. Затем проводиться повторный опрос, в ходе которого либо подтверждается, либо опровергается точка зрения экспертов, либо изменяется оценка в соответствии с мнением большинства. Так повторяется 3-4 раза. Затем вырабатывается согласованная оценка, при этом исследователь, конечно, не должен игнорировать мнение тех, кто после неоднократных опросов остался на своей позиции.
Метод мозгового штурма (брейнстоуминг) предполагает выдвижение любых, даже самых невероятных вариантов решения проблемы. При этом на первом этапе совершенно исключается критика суждений. На втором этапе каждая идея подвергается критике с точки зрения ее жизнеспособности. Метод предусматривает включение специалистов различного профиля
Интерес представляет метод синектики, который представлен У. Гордоном. Строго метод нельзя относить к экспертным оценкам. Согласно У. Гордону наиболее верные решения могут принимать не специалисты, а дилетанты. Эксперты - ученые всегда стремятся придерживаться рамок своей науки, что не позволяет им разглядеть принципиально новые аспекты. Они не могут посмотреть на проблему с неожиданной стороны. (В крайних проявлениях – это профессиональный кретинизм.) Дилетантов же надо вооружить определенными приемами, с помощью которых они будут продуцировать нестандартные решения.
Роль экспертов сводится к постовому, регулирующему уличное движение. Он проверяет с научной точки зрения каждую идею на подлинность. То есть основная функция – профессиональная оценка предложений. Эксперты должны сделать незнакомое понятным для членов группы, а члены группы должны сделать для экспертов знакомое непонятным. Однако эти приемы использовались исключительно в технической сфере. Политика отличается уникальностью, постоянно обновляющимися задачами, поэтому применять мнения неспециалистов становится проблематичным.
Процесс синектики о многом напоминает брейнстоуминг. В начале вырабатывается как можно больше возможных решений, но взаимоисключающих Синектика – соединение абсолютно различных элементов. Ходом дискуссии управляют синекторы. Большое значение имеют психологические приемы. Согласно У. Гордону значительную роль играют суждения по аналогии
У. Гордон выделяет 4 вида суждений.
Личностная аналогии отождествление принимаемо решения с кем- то. на место противника или лица, ответственного за принятие управленческого решения. Полезно прогнозировать последствия решений
Прямая