Теоретические сведения
Эта программа способна выполнять сканирование и распознавание текстов на разных языках, в том числе и смешанных двуязычных текстов. С ее помощью можно выполнять пакетную обработку многостраничных документов, а также настраивать режим распознавания для улучшения соответствия электронного документа бумажному оригиналу при плохом качестве последнего или использовании в нем шрифтов, далеких от стандартных.
Процесс преобразования текста из бумажного вида в электронный состоит из нескольких частей.
Основные операции обработки бумажного документа в программе FineReader выполняются с помощью панели инструментов Scan&Read. С точки зрения этой программы, процесс обработки документа состоит из пяти этапов:
· сканирование документа (кнопка Сканировать);
· сегментация документа (кнопка Сегментировать);
· распознавание документа (кнопка Распознать);
· редактирование и проверка результата (кнопка Проверить);
· сохранение документа (кнопка Сохранить).
Первый этап – это сканирование документа. Однако если превращение бумажной картинки в электронную завершается на этапе сканирования, то превращение текста в электронный на этом этапе только начинается. В результате сканирования и фотографии, и текста будет получен графический файл.
На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки.
Если вы захотите изменить полученный текст либо использовать только его часть, сделать это будет очень сложно. Дело в том, что графический файл представляет собой набор точек разных цветов, а текстовый файл – это набор символов. Чтобы в процессе сканирования получить текстовый документ, состоящий из символов, графический файл необходимо каким-то образом преобразовать в текстовый. Сделать это можно с помощью специальных приложений, называемых OCR-программами (OCR расшифровывается как Optical Character Recognition – оптическое распознавание символов).
Современные OCR-системы умеют распознавать печатный, а в некоторых случаях и рукописный текст на многих языках, могут сохранять полученный результат в удобном формате (например, в формате Word), исправлять погрешности сканирования, а также отделять текст от изображения. Наиболее популярными на сегодняшний день OCR-системами являются FineReader (https:// www.abbyy.com) и Cunei Form
Системы распознавания текстов у опытных пользователей компьютеров ассоциируются в первую очередь с названием FineReader. Действительно, продукт фирмы ABBYY Software удобен, обеспечивает высокое качество распознавания, «понимает» около 200 языков и умеет различать даже листинги программ, написанные на некоторых языках программирования (например, Basic, C/C++, Java, Pascal).
Рассмотрим, как можно превратить бумажный текст в электронный с помощью программы FineReader (рис. 1.1).
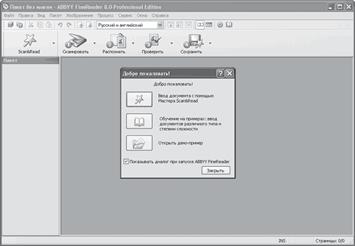
Рис. 1.1. Окно программы FineReader
Процесс сканирования в FineReader осуществляется двумя способами. Вы можете воспользоваться услугами Мастера Scan&Read, с помощью которого пройдете все пять этапов преобразования документа бумажного вида в электронный (сканирование, сегментация, распознавание, проверка и сохранение). Второй вариант – вручную пройти все эти шаги, выбирая соответствующие пункты меню либо используя кнопки панели инструментов.
После запуска FineReader и выбора режима работы программы (с помощью мастера или вручную) необходимо установить в сканер печатный документ. Для запуска процесса сканирования нажмите кнопку Сканировать либо выполните команду Файл > Сканировать изображение.
В программе FineReader сканирование может производиться как через драйвер TWAIN, так и в обход его. Первый способ используют, когда требуется точная настройка параметров сканирования, когда документ включает цветные иллюстрации, которые необходимо сохранить, а также когда разные страницы многостраничного документа сильно различаются по качеству. Второй вариант обеспечивает максимальную скорость и удобство сканирования. Выбор используемого варианта осуществляется при помощи флажка Показывать диалог TWAIN-драйвера сканера (Сервис > Опции > Сканирование).
После выбора способа сканирования откроется окно, в котором можно выполнить предварительный просмотр и установить необходимые параметры (рис. 1.2). Это окно для разных типов сканера имеет разный вид, но все же основные его параметры одинаковы. Расскажу о наиболее общих параметрах сканирования на примере использования сканера Mustek 1200 UB Plus.
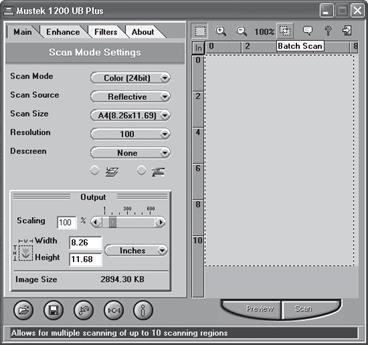
Рис. 1.2. Настройка параметров сканирования
Обратите внимание на то, как вы размещаете источник в сканере. Постарайтесь добиться, чтобы книга или журнал лежали как можно ровнее, ведь если текст расположить неровно, он будет распознан неправильно и вам придется вручную исправлять много ошибок.
После того как вы указали параметры сканирования, можно выполнить предварительный просмотр страницы. Для этого необходимо нажать кнопку Preview (Предварительный просмотр). На этом этапе вы сможете увидеть, верно ли установлена страница в сканер, захватывает ли область сканирования весь текст или какая-то его часть остается за пределами. Затем вы можете поправить страницу в сканирующем устройстве, только потом не забудьте повторно предварительно ее просмотреть.
В левой части окна сканирования размещены вкладки и поля для настройки параметров. В списке Scan Mode (Режим сканирования) можно выбрать режим сканирования. Существует три варианта: цветной режим (Color (24 bit)), в оттенках серого (Gray) или сканирование текста (Lineart). Если вы собираетесь сканировать фотографии или изображение, советую выбрать первый или второй режим. Третий вариант идеально подходит для сканирования текста. Безусловно, вы можете задать цветной режим и при сканировании книги, но следует знать, что в этом случае результирующий файл будет занимать гораздо больше места, чем при сканировании в других режимах.
В списке Scan Size (Размер сканирования) вы можете установить размер окна сканирования. По умолчанию предлагается значение Custom (Обычный), то есть совпадающий с размером листа в сканере. Однако, чтобы ускорить процедуру сканирования, особенно для тех документов, которые сравнительно невелики, вы можете выбрать другие значения этого параметра, например А4 (размер стандартного листа бумаги), В5 или Letter (Письмо).
Следующий параметр – Resolution (Разрешение) – очень важен для результата сканирования. Разрешение измеряется в dpi (dots per inch, точек на дюйм). Эта величина характеризует, насколько качественным будет результат сканирования – полученное изображение. Чем выше разрешение, тем лучше будет выглядеть картинка. В то же время большие значения этого параметра говорят также о том, что полученный графический файл будет очень большой. Поэтому разрешение нужно выбирать рационально.
В параметрах сканирования можно выбрать различные значения dpi – от самого маленького (50) до огромного (19200). Существуют некоторые правила выбора dpi, руководствуясь которыми, вы получите наиболее оптимальный результат. Для сканирования текстов со средним размером шрифта установите 300 dpi. Для текстов, набранных мелким шрифтом (менее 9 пт), лучше использовать 400–600 dpi. Картинки, отсканированные с разрешением меньше 600 dpi, могут получиться недостаточно четкими.
Собственно, это разрешение подойдет для черно-белых изображений. Если вы хотите получить качественный цветной рисунок, в этом случае величину разрешения стоит увеличить хотя бы до 900 dpi.
Область Output (Вывод) позволяет настроить параметры вывода сканирования, то есть параметры отображения результата сканирования на листе бумаги. Например, в поле Scaling (Масштабирование) указывают масштаб готового документа. Изменить установленное по умолчанию значение вы можете двумя способами: ввести вручную необходимую величину в поле Scaling (Масштабирование) или переместить бегунок рядом с ним.
В полях Width (Ширина) и Height (Высота) можно указать размеры полученного изображения – ширину и высоту соответственно. Список рядом позволяет задать единицы измерения: Inches (Дюймы), СМ (Сантиметры) или Pixels (точки). Обратите внимание: в области Image Size (Размер изображения) указано, каков будет размер полученного изображения в килобайтах.
В этом же окне вы можете сохранить настройки в INI-файле, для этого предназначена кнопка Save (Сохранить). Если у вас раньше были сохранены настройки, открыть их можно с помощью кнопки Load (Загрузить).
Возможно, в некоторых случаях вам нужно будет отсканировать не всю страницу, а только часть. Для этого выделите нужную область сканирования. Воспользуйтесь кнопкой Cropping Tool (Обрезка), после чего измените размеры прямоугольника таким образом, чтобы был выделен только нужный вам фрагмент.
После того как вы убедились, что страница расположена верно и все параметры установлены, можно начинать процедуру сканирования. Для этого нажмите кнопку Scan (Сканировать) (рис. 1.3).
При работе с рисунками после сканирования следует сохранить изображение в графическом формате. Для этого выполните команду Файл > Сохранить пакет как и укажите имя и тип сохраняемого файла.
Создав графический файл, вы всегда сможете обработать его в графическом редакторе, например в Paint или Photoshop: обрезать лишние блоки, добавить надписи, подкорректировать рисунок.
Если вы имеете дело с текстом, следующим этапом вашей работы будет распознавание. Задача распознавания состоит в том, чтобы превратить отсканированное изображение в текст, сохранив при этом оформление страницы.

Рис. 1.3. Результат сканирования
Если при сканировании вы сохранили результат в виде графического файла, его можно открыть для последующей обработки, выполнив команду Файл > Открыть PDF-изображение.
По умолчанию в окне программы FineReader отображаются одновременно два окна – Изображение и Текст. Вы можете управлять отображением этих окон на экране с помощью специальных кнопок панели инструментов FineReader: кнопка Показывать оба окна означает исходное состояние размещения окон, можно нажать кнопку Показывать окно Изображение или Показывать окно Текст и представить таким образом только одно из окон. Кроме этого, в полях Масштаб каждого из окна можно задать масштаб исходного изображения. Дополнительные настройки внешнего вида окна доступны в меню Вид.
Если ваша страница содержит только сплошной текст, вы можете смело переходить сразу к распознаванию. Однако если на странице есть изображения, схемы или таблицы, перед запуском процедуры распознавания следует провести анализ макета страницы (сегментирование). Анализ макета страницы позволяет разбить страницу на блоки, указав тем самым, какие именно участки полученного изображения следует распознать, а какие можно будет проигнорировать.
Анализ макета страницы можно проводить автоматически или вручную. Автоматическое сегментирование FineReader осуществляет, если сразу после сканирования запустить процесс распознавания. Для этого вам нужно нажать кнопку Распознать на панели инструментов. Вручную выделять блоки есть смысл, если вы хотите распознать не весь отсканированный документ, а лишь его часть, либо в результате автоматического сегментирования блоки были выделены неверно.
Для анализа макета страницы необходимо выполнить команду Процесс>Распознать>Анализ макета страницы. FineReader произведет автоматическое разбиение страницы на блоки (рис. 1.4). Для выделения или редактирования блока следует воспользоваться командой Изображение > Изменить тип блока и в появившемся меню выбрать нужный тип. Например, если у вас в тексте встречаются иллюстрации, пометьте их с помощью типа блока Картинка – выбрав пункт меню, вам следует выделить в окне Изображение нужный фрагмент. Точно так же помечаются текст и таблица.
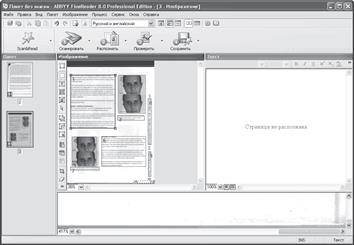
Рис. 1.4. Анализ макета страницы означает выделение на ней блоков разного типа
При обработке изображения, полученного в результате сканирования, FineReader выделяет блоки нескольких типов. Блок Зона распознавания используется для распознавания и автоматического анализа. В результате обработки он будет разделен на блоки других типов. Для корректного распознавания таблицы существует специальный блок Таблица, для распознавания текста – Текст, для изображений используются Картинка и Штрих-код.
Следующим этапом обработки изображения является установка параметров сканирования – вы должны задать язык распознавания, тип печати, ориентацию текста. Язык распознавания устанавливается на панели Стандартная, причем FineReader умеет распознавать не только одноязычный, но и многоязычный текст, например содержащий элементы на русском и английском. Этот параметр очень важен, и если в вашем тексте встречаются английские термины, обязательно выберите пункт Русский и английский, иначе большинство английских слов будут распознаны неверно.
Тип печати обычно определяется автоматически. Однако в некоторых случаях, особенно для текстов, напечатанных в черновом варианте или на матричном принтере, тип печати необходимо устанавливать вручную. Для этого выполните команду Сервис > Опции, перейдите на вкладку Общие и нажмите кнопку Дополнительные опции. В появившемся окне (рис. 1.5) выберите нужное значение с помощью переключателя Тип печати. По умолчанию здесь установлен переключатель Авто, но вы можете выбрать другой – например, Пишущая машинка или Матричный принтер.
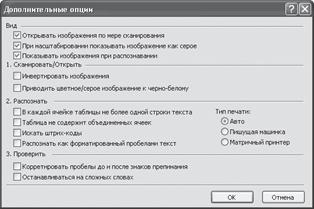
Рис. 1.5. Настройка параметров распознавания текста
После установки параметров можно начинать распознавание.
Результат распознавания будет отображаться в окне Текст, встроенном редакторе программы FineReader.
Иногда программа по умолчанию неверно распознает блоки с вертикальным текстом. Для изменения ориентации текста щелкните правой кнопкой мыши на блоке с вертикальным текстом, выберите пункт Свойства и в открывшемся окне укажите нужный вариант в списке Направление текста. После этого еще раз распознайте этот блок.
Для проверки текста нажмите кнопку Проверить. На экране отобразится окно Проверка (рис. 1.6). В верхней его части система будет по очереди выделять найденные ошибки. Вы можете исправлять их непосредственно в этом окне. После исправления не забудьте нажать кнопку Подтвердить. В некоторых случаях программа FineReader будет предлагать варианты замены слова с ошибкой. Используя предложенные варианты исправления текста либо задав изменения вручную, можно исправить неверно распознанные слова.
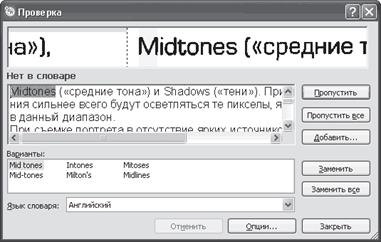
Рис. 1.6. После распознавания текст необходимо проверить
Во время проверки текста вы можете добавлять исправленные слова в словарь. Это позволит повысить качество распознавания, так как при распознавании система сверяется со словарем, в котором может не быть некоторых слов, особенно терминов или сокращений.
После завершения проверки закройте окно. Все исправления будут сохранены в распознанном тексте документа.
Получив готовый текст, вы можете его отформатировать – для этого предназначена панель инструментов Форматирование. На ней размещены инструменты для изменения шрифта и способа выравнивания текста.
После распознавания и исправления результаты работы можно сохранить в отдельном файле, скопировать в буфер обмена либо передать во внешнее приложение.
Один из способов сохранения результатов работы в FineReader – использование мастера сохранения результатов. Для его запуска нажмите кнопку Сохранить.
В окне мастера предлагается выбрать приложение для передачи текста либо одну из возможностей: Сохранить страницы, Отправить страницы по электронной почте, Копировать в буфер обмена (рис. 1.7). В этом же окне можно задать параметры сохранения оформления распознанного текста и возможность сохранения картинок.
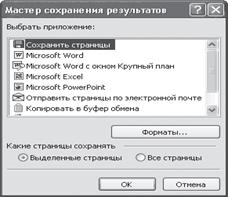
Рис. 1.7. Мастер сохранения результатов
Выбрав пункт Microsoft Word, вы таким образом отобразите распознанный текст в окне текстового редактора Word.
После этого можно продолжить работу с документом.
Программа FineReader завоевывает все больше поклонников, так как ее возможности позволяют превратить текст или изображения даже самого плохого качества в электронный документ с наименьшими потерями. После освоения основных функций программы вам не составит большого труда преобразовать в электронный вид десятки бумажных страниц.