КОДИРОВАНИЕ И ПОИСК ДАННЫХ
Лабораторный практикум
По дисциплине «Теоретические основы
Информационных процессов»
Уфа 2012
Составители: С.Г. Газетдинова, Ю.Б. Головкин, Л.А. Кромина,
Р.А. Ярцев
УДК 681.3.06 (07)
ББК 32.973-018.2 (я7)
Кодирование и поиск данных: лабораторный практикум по дисциплине "Теоретические основы информационных процессов" для направления подготовки бакалавров 080800 – Прикладная информатика / Уфимск. гос. авиац. техн. ун-т; Сост.: С.Г.Газетдинова, Ю.Б.Головкин, Л.А.Кромина, Р.А.Ярцев. – Уфа, 2010. – 23 с.
Рассматриваются основные методы экономного и помехоустойчивого кодирования передаваемых сообщений, а также методы поиска данных в памяти ЭВМ, основанные на сравнении ключей. В приложении приведены варианты заданий на лабораторные работы.
Предназначено для бакалавров направления 080800 «Прикладная информатика» в целях овладения навыками программной реализации методов кодирования и поиска данных на основе знаний, полученных в ходе изучения курса «Теоретические основы информационных процессов».
Табл. 1. Библиогр.: 8 назв.
Рецензенты: д-р техн. наук, проф. В. В. Миронов,
канд. техн. наук, доц. Д. А. Ризванов
© Уфимский государственный
авиационный технический университет, 2010
СОДЕРЖАНИЕ
| Введение | |
| Лабораторная работа 1. Экономное кодирование сообщений | |
| 1. Цель работы | |
| 2. Задачи | |
| 3. Теоретическая часть | |
| 4. Порядок выполнения работы | |
| 5. Контрольные вопросы | |
| 6. Содержание и оформление отчета | |
| Лабораторная работа 2. Помехоустойчивое кодирование сообщений | |
| 1. Цель работы | |
| 2. Задачи | |
| 3. Теоретическая часть | |
| 4. Порядок выполнения работы | |
| 5. Контрольные вопросы | |
| 6. Содержание и оформление отчета | |
| Лабораторная работа 3. Поиск данных на основе сравнения ключей | |
| 1. Цель работы | |
| 2. Задачи | |
| 3. Теоретическая часть | |
| 4. Порядок выполнения работы | |
| 5. Контрольные вопросы | |
| 6. Содержание и оформление отчета | |
| Приложение | |
| Список литературы |
ВВЕДЕНИЕ
В 1948 году вышла в свет работа Клода Шеннона «Математическая теория связи», в которой развивались идеи помехоустойчивого кодирования при передаче сообщений по каналам связи с шумами. Данный труд лег в основу научного направления, получившего название «теория информации». В рамках теории информации был получен ряд значительных результатов, связанных с различными вопросами кодирования передаваемой информации: построение оптимальных кодов, декодирование избыточных кодов, получение границ вероятности ошибки и различных информационных пределов избыточности. Многие из этих результатов были использованы на практике, например, при решении задач выбора комплекса технических средств АСУ и обеспечения его оптимального функционирования.
Однако, с развитием вычислительной техники - появлением персональных ЭВМ и их сетей – наиболее актуальными оказались не проблемы оптимального кодирования, а проблемы оптимального хранения и поиска данных в искусственной памяти, а также другие вопросы, связанные с обработкой данных. Поэтому в восьмидесятые годы прошлого столетия на основе классической теории информации сформировалась новая наука с более широкой предметной областью – теоретическая информатика, куда теория информации была включена в качестве одного из разделов.
Курс «Теоретические основы информационных процессов» включает два раздела, отражающих соответствующие направления теоретической информатики: в первом из них рассматриваются вопросы кодирования сообщений, а во втором – вопросы поиска данных. При этом в первом разделе изучаются два основных вида кодирования – это экономное кодирование, имеющее своей целью сжатие данных, и помехоустойчивое кодирование, которое производится в целях защиты передаваемых сообщений от действия помех.
Лабораторный практикум по данному курсу разработан в соответствии со структурой теоретического материала. Он включает три работы, имеющие своей целью изучение практических методов кодирования и сжатия данных. Каждая из работ предусматривает создание программы на языке высокого уровня, реализующей конкретный практический метод согласно заданию, полученному у преподавателя. Образцы вариантов заданий приведены в приложении.
ЛАБОРАТОРНАЯ РАБОТА 1.
ЭКОНОМНОЕ КОДИРОВАНИЕ СООБЩЕНИЙ
Цель работы
Целью работы является изучение прикладных методов экономного кодирования сообщений для повышения эффективности их хранения и передачи через канал связи.
Задачи
Задачами лабораторной работы являются задачи овладения навыками программной реализации методов экономного кодирования на языке высокого уровня и применения разработанных программ для кодирования конкретных типов сообщений.
Теоретическая часть
Проблема сжатия данных. Объемы данных, передаваемых и обрабатываемых в автоматизированных информационных системах (АИС) велики, поэтому во многих случаях важно обеспечить такое их кодирование, которое характеризовалось бы наименьшей длиной получающихся сообщений. Существуют два основных принципа сжатия данных: на основе смыслового содержания и на основе статистических свойств.
Сжатие на основе смыслового содержания. Пусть имеется алфавит A из n знаков (символов) и по каналу связи нужно передать m сообщений, закодировав их двоичными кодовыми словами минимальной длины. При этом каждое сообщение имеет длину lj, т.е. составляется из lj знаков алфавита A. Выясним минимальное количество разрядов R, достаточное для осуществления такого кодирования. При этом возможны два подхода к кодированию.
Первый из них основан на кодировании целых сообщений, когда их двоичные коды не зависят от конкретных символов алфавита А, использованных при составлении сообщений. При этом справедлива формула (1):
(1) 
Здесь […] – целая часть числа.
Второй подход основан на посимвольном кодировании сообщений, когда двоичное кодовое слово формируется путем объединения кодов, соответствующих каждому из символов передаваемого сообщения. При этом справедлива формула (2):
(2) 
Здесь 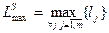 - максимальная длина сообщений.
- максимальная длина сообщений.
Выбор наиболее экономного способа кодирования зависит от сравнения RI и RII: при небольшом числе длинных сообщений предпочтителен первый подход, если же имеется много коротких сообщений, составленных из небольшого количества знаков, то предпочтительнее второй подход. Если количество сообщений заранее неизвестно, то нужно производить посимвольное кодирование.
При посимвольном кодировании можно уменьшить количество знаков в передаваемых сообщениях путем сжатия последних по контексту (на основе смыслового содержания). Этот путь лежит в основе большого количества практических методов сжатия данных (см. далее).
Переход от «естественных» обозначений к «компактным». Многие данные обычно имеют вид, удобный для их чтения человеком. При этом они содержат больше символов, чем это необходимо для адекватного восприятия передаваемой информации. Наличие такой избыточности позволяет перекодировать информацию более компактно, поступаясь наглядностью ее представления в интересах эффективности передачи и хранения данных.
Например, различные даты можно хранить не в обычном формате, а путем указания их порядкового номера в некотором диапазоне. Зная дату начала диапазона и порядковый номер кодируемой даты в нем, в дальнейшем можно будет осуществить декодирование и восстановить закодированную дату в обычном представлении.
Подавление повторяющихся символов. Избыточность данных, содержащих повторяющиеся подряд символы, можно уменьшить, если вместо последовательности вида  кодировать эквивалентную ей последовательность вида pka, в которой р – признак повторения (специальный символ или слово), k – число повторений символа a.
кодировать эквивалентную ей последовательность вида pka, в которой р – признак повторения (специальный символ или слово), k – число повторений символа a.
Эффективность метода определяется значением величины Е:

Здесь n – размерность алфавита А ( ), R(p) и R(k) – фиксированное число битов для кодирования признака р и числа повторений k соответственно.
), R(p) и R(k) – фиксированное число битов для кодирования признака р и числа повторений k соответственно.
При Е≤0 от использования данного метода следует отказаться.
Кодирование часто используемых данных. Многие сообщения и файлы данных содержат текстовые фрагменты из различных областей знаний. В таких текстах можно выделить множество наиболее употребительных слов, например, терминов, экономно их закодировать и использовать полученные коды вместо обычного представления.
Сжатие данных на основе сравнения. В упорядоченных наборах данных часто совпадают начальные символы или даже последовательности начальных символов записей. Поэтому можно кодировать данные на основе их сравнения с предыдущими. В этом случае сжимаемым элементам данных может предшествовать специальный признак, указывающий на то, что элемент данных:
• совпадает с предыдущим;
• имеет следующее по порядку значение;
• совпадает с предыдущим кроме m последних символов;
• не имеет связи с предыдущим.
При использовании подобных признаков закодированные данные содержат только отличия текущих элементов от предыдущих.
Сжатие на основе статистических свойств данных и неравномерные коды. Методы такого сжатия предполагают использование кодовых слов переменной длины. Здесь возникает проблема выделения кодовых слов из последовательности символов в целях декодирования соответствующих сообщений. Для ее решения, помимо кодов-разделителей, может быть использовано условие префиксности: ни одно кодовое слово не является началом другого. Теперь каждое отдельное слово может быть получено считыванием символов последовательности тех пор, пока считанная комбинация не совпадет с одним из имеющихся кодов. Если, например, префиксный код состоит из пяти слов 00, 01, 101, 110 и 1000, то последовательность 101110010100 разбивается на декодируемые слова однозначно.
Префиксный код называется примитивным, если его нельзя сократить, т.е. при вычеркивании любого знака хотя бы в одном кодовом слове условие префиксности нарушается. Так, префиксный код, приведенный в качестве примера, является примитивным.
Кодирование словами переменной длины. Пусть имеется множество сообщений S ={sj}, i=1,…,m, причем известны вероятности их появления pj ( ). Пусть также каждое сообщение sj кодируется двоичным словом kj из множества K ={kj}, имеющим длину lj. Тогда в качестве меры эффективности кодирования выступает средняя длина кодового слова λkS, такая, что:
). Пусть также каждое сообщение sj кодируется двоичным словом kj из множества K ={kj}, имеющим длину lj. Тогда в качестве меры эффективности кодирования выступает средняя длина кодового слова λkS, такая, что:
(3) 
Кодирование последовательностей символов. Пусть сообщения формируются из символов алфавита A={a,b}, появляющихся независимо с вероятностями p1=0,7 и p2=0,3. Закодировав каждое из них символом 0 или 1, по формуле 3 получим: λkA =1 (бит/символ). Однако более экономным является кодирование последовательностей из двух символов алфавита A (см. таблицу 1).
Таблица 1
Пример кодирования двухсимвольных последовательностей
| Последовательность символов aiaj | Вероятность pij | Кодовое слово kij | Средняя длина кодового слова λkA |
| aa | 0,49 | 0,905 бит/символ | |
| ab | 0,21 | ||
| ba | 0,21 | ||
| bb | 0,09 |
При увеличении размерности кодируемых комбинаций λkA уменьшается, стремясь к пределу, приблизительно равному 0,881 бит/символ. Это связано с особенностями применения процедур экономного кодирования.
Порядок выполнения работы
Для выполнения работы необходимо:
1. Повторить правила техники безопасности при работе с вычислительной техникой.
2. Изучить часть раздела «Кодирование сообщений» лекционного курса «Теоретические основы информационных процессов», посвященную экономному кодированию, а также теоретическую часть лабораторной работы 1 в настоящих методических указаниях.
3. Получить у преподавателя вариант задания (образцы заданий приведены в приложении).
4. В соответствии с заданием разработать алгоритм предложенного метода экономного кодирования и написать программу на языке высокого уровня, реализующую разработанный алгоритм.
5. Ввести программу в ЭВМ, отладить и результаты выполнения на конкретных примерах показать преподавателю.
6. В соответствии с требованиями раздела 6 оформить отчет по работе.
7. Защитить лабораторную работу, продемонстрировав знание методов экономного кодирования и умение решать аналогичные задачи.
5. Контрольные вопросы
1. Что такое экономное кодирование?
2. Какие методы экономного кодирования Вы знаете?
3. Как определяется число разрядов, необходимое для двоичного кодирования?
4. Какие коды называются неравномерными?
5. Какая проблема возникает в связи с использованием неравномерных кодов?
6. Каково условие префиксности кода? Для чего оно применяется?
7. Что характеризует средняя длина кодового слова и как она рассчитывается?
Содержание и оформление отчета
Отчет должен содержать:
● титульный лист, название и цель работы;
● вариант задания;
● листинг программного кода;
● выводы по работе.
ЛАБОРАТОРНАЯ РАБОТА 2.