В выражении WHERE, кроме перечисленных предикатов, могут также использоваться выражения с оператором SELECT. Любое выражение, начинающееся с оператора SELECT, является запросом к базе данных. Если в выражении встречается еще хотя бы один оператор SELECT, то он задает запрос, вложенный в первый. Вложенные запросы также называют подзапросами.
Вложенный запрос является обычным запросом, таким же, как и рассмотренные ранее. Он возвращает таблицу (набор записей), которая, так или иначе, используется для формирования ответа на основной запрос. Так, например, подзапрос используется, когда для выборки данных в одной таблице необходимо выполнить проверки по другой таблице. Для этой цели подходят перечисленные далее специальные предикаты.
ALL, SOME, ANY
Предикаты ALL (все), SOME (некоторый), ANY (любой) в действительности представляют собой кванторы, известные в математической логике как кванторы всеобщности и существования. ALL — квантор всеобщности, a SOME и ANY, являющиеся синонимами в SQL, — кванторы существования. Заметим, что в переводе на русский слово ANY следовало бы понимать как квантор всеобщности ("любой" означает "все"), однако в английском языке есть различные варианты значений этого слова. Применение ключевого слова ALL следует понимать как "для всех" или "для каждого". Ключевые слова SOME и ANY следует понимать как "хотя бы какой-нибудь один". Как бы то ни было, в языке SQL ключевые слова SOME и ANY имеют одинаковый смысл, отличающийся от ALL.
Примечание. Выражения с ключевыми словами ALL, SOME (ANY) соответствуют логическим выражениям с кванторами и, как таковые, могут называться предикатами.
EXISTS
Обработка данных часто состоит из нескольких этапов. Так, сначала производится некоторая выборка данных, а затем выполняются какие-то манипуляции с ней. Однако, выполняя запрос на выборку, мы далеко не всегда можем быть уверенными, что ответ содержит хотя бы одну непустую строку. Если ответ на запрос пуст, то бессмысленно производить дальнейшую обработку данных. Таким образом, полезно знать, содержит ли ответ на запрос какие-либо данные. Для этого предназначен предикат EXISTS (существует). Он становится истинным только тогда, кода результатная таблица, полученная в ответ на запрос, содержит хотя бы одну запись.
UNIQUE
Предикат UNIQUE (уникальный) имеет такой же смысл, как и EXISTS, но при этом для его истинности требуется, чтобы все записи в результатной таблице не только существовали, но и были уникальны (т. е. не повторялись).
DISTINCT
Предикат DISTINCT (отличающийся, особый) почти такой же, как UNIQUE. Отличие этих предикатов обнаруживается применителъно к значениям NULL. Так, если в результатной таблице все записи уникальны (предикат UNIQUE истинен), то и предикат DISTINCT тоже истинен (т. е. если все записи уникальны, то они и отличающиеся). С другой стороны, если в результатной таблице имеются, хотя бы две неопределенные записи, то предикат DISTINCT ложен, хотя предикат UNIQUE истинен.
OVERLAPS
Предикат OVERLAPS (перекрывает) используется для определения, перекрываются ли два интервала времени. Интервал времени можно задать двумя способами: в виде начального и конечного моментов или в виде начального момента и длительности. Примеры задания интервала времени:
· (TIME '12:25:30', TIME '14:30:00') —интервал, заданный начальным и конечным моментами;
· (TIME '12:45:00', INTERVAL '2' HOUR)—интервал, заданный начальным моментом и длительностью в часах.
Выражение с предикатом OVERLAPS можно записать, например, так:
(TIME '12:25:30', TIME '14:30:00') OVERLAPS (TIME 42:45:00', INTERVAL '2' HOUR)
Поскольку временные интервалы в данном примере пересекаются, то предикат OVERLAPS возвращает значение true.
MATCH
Предикат MATCH применяется для проверки сохранения ссылочной целостности при модификации данных, т. е. при добавлении, изменении и удалении записей.
SIMILAR
Предикат SIMILAR (подобный) применяется для проверки частичного соответствия символьных строк. Эту же задачу можно ре шить и с помощью предиката LIKE, однако в ряде случаев SIMILAR более эффективен.
Предположим, что в некоторой таблице имеется столбец ОС, содержащий названия операционных систем. Нужно выбрать записи, соответствующие Windows NT, Windows XP и Windows 98. Тогда в выражении запроса можно использовать такой оператор WHERE:
WHERE ОС SIMILAR TO '(Windows (NT|XP|98))';
Оператор GROUP BY
Оператор GROUP BY (группировать по) служит для группировки записей по значениям одного или нескольких столбцов. Если в SQL-выражении используется оператор WHERE, задающий фильтр записей, то оператор GROUP BY находится и выполняется после него. Для определения, какие записи должны войти в группы, служит оператор HAVING, используемый совместно с GROUP BY. Если оператор HAVING не применяется, то группировке подлежат все записи, отфильтрованные оператором WHERE. Если WHERE не используется, то группируются все записи исходной таблицы.
Допустим, что на основе таблицы о клиентах требуется сгруппировать данные о суммах заказов клиентов по регионам. Для этого можно воспользоваться следующим SQL-выражением:
SELECT Регион, Сумма_заказа FROM Клиенты GROUP BY Регион;
На рис. 4 показана результатная таблица на фоне исходной таблицы Клиенты. Обратите внимание, что записи с одинаковыми названиями регионов расположены рядом друг с другом (в одной группе).

Рис. 4. Результат запроса сумм заказов с группировкой по регионам

Рис. 5. Результат запроса итоговых сумм заказов по регионам
Чтобы получить таблицу, в которой суммы заказов подытожены по регионам, потребуется использовать итоговую функцию SUM () и группировку по регионам:
SELECT Регион, SUM(Сумма_заказа) FROM Клиенты
GROUP BY Регион;
Здесь в выражении SELECT указаны обычный столбец таблицы Клиенты и итоговая функция SUM(), вычисляющая сумму значений столбца Сумма_заказа. Поскольку группировка задана по столбцу "Регион, то функция SUM (Сумма_заказа) вычисляет Суммы значений столбца Сумма_заказа для каждого значения столбца Регион. На рис. 5 показана результатная таблица на фоне исходной таблицы Клиенты. Обратите внимание, что в этой таблице названия регионов не повторяются.
Оператор GROUP BY собирает записи в группы и упорядочивает (сортирует) группы по алфавиту (точнее, по ASCII-кодам символов). Это обстоятельство следует иметь в виду перед тем, как принять решение об использовании оператора сортировки ORDER BY.
Оператор HAVING
Оператор HAVING (имеющие, при условии) обычно применяется совместно с оператором группировки GROUP BY и задает фильтр записей в группах. Правила его формирования такие же, что и для оператора WHERE.
Предположим, что из таблицы Клиенты требуется выбрать данные о регионах и суммах заказов, сгруппированные по регионам и такие, в которых сумма заказа превышает 500. Иначе говоря, требуется сгруппировать данные с ограничением записей, входящих в группы. Запрос, выполняющий это задание, имеет вид:
SELECT Регион, Сумма_заказа FROM Клиенты
GROUP BY Регион, Сумма_заказа
HAVING Сумма_заказа > 500;

Рис. 6. Результат запроса с группировкой по регионам
и ограничением по суммам заказов
Если в SQL-выражении оператора GROUP BY нет, то оператор HAVING применяется ко всем записям, возвращаемым оператором WHERE. Если же отсутствует и WHERE, то HAVING действует на все записи таблицы.
Оператор ORDER BY
Оператор ORDER BY (сортировать по) применяется для упорядочивания (сортировки) записей. Если он используется в запросе, то в самом конце запроса. Этот оператор сортирует строки всей таблицы или отдельных ее групп (в случае применения оператора GROUP BY). Если в выражении запроса оператора GROUP BY нет, то оператор ORDER BY рассматривает все записи таблицы как одну группу.
Вслед за ключевым словом ORDER BY указывается столбец, по значениям которого следует произвести сортировку. После имени столбца можно указать ключевое слово, задающее порядок (режим) сортировки:
· ASC — по возрастанию (ascending). Это значение принято по умолчанию, поэтому если необходима сортировка, например, в алфавитном порядке, то специально указывать порядок не требуется;
· DESC — по убыванию (descending).
Если в выражении ORDER BY указаны несколько столбцов сортировки, то сначала записи упорядочиваются по значениям первого столбца, затем для каждого значения первого столбца записи упорядочиваются по значениям второго столбца и т. д. Столбцы в списке разделяются, как обычно, запятыми. Таким образом, создается иерархическая система сортировки записей результатной таблицы.
В следующем примере данные исходной таблицы клиенты сортируются по регионам и по именам клиентов (рис. 7). При этом сортировка по именам клиентов производится по убыванию, т. е. в порядке, противоположном алфавитному.
SELECT * FROM Клиенты
ORDER BY Регион, Имя DESC;
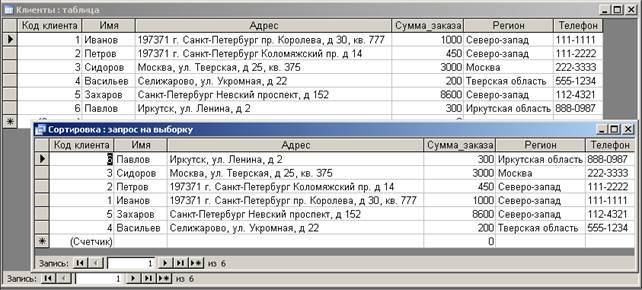
Рис. 7. Результат сортировки по регионам в алфавитном порядке
и по именам клиентов в обратном порядке
Логические операторы
Логические выражения в операторах WHERE и HAVING могут быть сложными, т. е. состоять из двух и более простых выражений, соединенных между собой логическими операторами (союзами) AND и/или OR. Оператор AND выполняет роль логического союза И, а оператор OR — союза ИЛИ. Так, если х и у — два логических выражения, то составное выражение х AND у принимает значение true (ИСТИНА) только тогда, когда х и у одновременно истинны; в противном случае выражение х and у принимает значение false (ЛОЖЬ). Выражение х OR у истинно, если хотя бы одно из выражений, х или у, истинно; если х и у одновременно ложны, то составное выражение х OR у ложно.
Логический оператор NOT применяется к одному выражению (возможно и к сложному), расположенному справа от него. Этот оператор меняет значение выражения на противоположное. Так, если выражение х имеет значение true, то выражение NOT х имеет значение false, и, наоборот, если х ложно, то NOT х истинно.
Предположим, из таблицы Клиенты (см. рис. 1) требуется выдать записи о клиентах из Москвы и Северо-запада. Соответствующий запрос имеет вид:
SELECT Регион, Имя, Сумма_заказа FROM Клиенты
WHERE Регион='Москва' OR Регион='Северо-запад';
Обратите внимание, что здесь используется логический оператор OR (ИЛИ), а не AND (И), поскольку нам нужны клиенты, проживающие или в Москве, или на Северо-Западе. Если бы вместо оператора OR мы применили AND, то получили бы пустую таблицу, т. к. в исходной таблице нет ни одной записи, в которой один и тот же столбец имел бы различные значения.
Внимание. Будьте внимательны при формулировке запроса на естественном языке и при его переводе на SQL.
Следующее SQL-выражение эквивалентно рассмотренному ранее. Оно основано на применении оператора IN:
SELECT Регион, Имя, Сумма_заказа FROM Клиенты
WHERE Регион IN ('Москва', 'Северо-запад');
Если требуется получить данные обо всех клиентах, которые не проживают ни в Москве, ни на Северо-западе, то можно использовать такое SQL-выражение:
SELECT Регион, Имя, Сумма_заказа FROM Клиенты
WHERE NOT (Регион='Москва' OR Регион='Северо-Запад');
Это выражение эквивалентно следующим двум:
SELECT Регион, Имя, Сумма_заказа FROM Клиенты
WHERE Регион < > 'Москва' AND Регион < > 'Северо-Запад';
и:
SELECT Регион, Имя, Сумма_заказа FROM Клиенты
WHERE Регион NOT IN ('Москва', 'Северо-Запад');
Задачи
Выберите в качестве исходной таблицу Клиенты, показанную на рис. 1. Вы можете не копировать ее содержимое в точности, а создать похожую таблицу самостоятельно. Важно, чтобы в таблице имелись символьные (текстовые) и числовые столбцы. Хорошо, если некоторые столбцы имели бы одинаковые значения, например, столбец Регион. В предлагаемых далее задачах требуется сформировать SQL-выражения, обеспечивающие некоторую выборку записей.
При формировании условий поиска (выборки) записей старайтесь абстрагироваться от конкретных данных в имеющейся таблице, поскольку пользователь может добавлять новые записи и модифицировать уже имеющиеся, делая это так, как ему хочется и как позволяют ограничения для данной таблицы. Например, столбец Адрес имеет символьный тип. Это означает, что он содержит произвольные символьные данные, структура которых поддерживается пользователем на семантическом уровне. В полях данного столбца может присутствовать или нет почтовый индекс, перед названием улицы может быть указано "ул." или "улица", или может быть ничего не указано, номер телефона может иметь различную значность, содержать или не содержать код региона, дефисы и т. п. При формулировании запроса в подобных ситуациях следует учесть как можно больше семантических нюансов.
Задача 1
Выберите записи, сгруппированные по регионам и исключающие Северо-Западный регион. Попробуйте сделать это по крайней мере двумя способами (с использованием WHERE и HAVING).
Задача 2
Выберите записи о клиентах, проживающих в городах, название которых оканчивается на "бург", а сумма заказа превышает 2000.
Задача 3
Выберите записи, в которых номера телефонов пятизначные. При этом следует предусмотреть, что номера телефонов могут содержать, а могут и не содержать дефисы, а сам номер может содержать или нет код региона, заключенный или не заключенный в круглые скобки.