Разобравшись в двух усовершенствованных методах сортировки, построенных на принципах включения и выбора, мы теперь коснемся третьего улучшенного метода, основанного на обмене. Если учесть, что пузырьковая сортировка в среднем была самой неэффективной из всех трех алгоритмов прямой (строгой) сортировки, то следует ожидать относительно существенного улучшения. И все же это выглядит как некий сюрприз: улучшение метода, основанного на обмене, о котором мы будем сейчас говорить, оказывается, приводит к самому лучшему из известных в данный момент методу сортировки для массивов. Его производительность столь впечатляюща, что изобретатель Ч. Хоар даже назвал метод быстрой сортировкой (Quicksort).
В Quicksort исходят из того соображения, что для достижения наилучшей эффективности сначала лучше производить перестановки на большие расстояния. Предположим, у нас есть n элементов, расположенных по ключам в обратном порядке. Их можно отсортировать за n /2 обменов, сначала поменять местами самый левый с самым правым, а затем последовательно двигаться с двух сторон. Конечно, это возможно только в том случае, когда мы знаем, что порядок действительно обратный. Но из этого примера можно извлечь и нечто действительно поучительное.
Давайте попытаемся воспользоваться таким алгоритмом: выберем наугад какой-либо элемент (назовем его x) и будем просматривать слева направо массив до тех пор, пока не обнаружим элемент a i > x, затем просмотрим его справа налево, пока не найдем элемент a j < x. Теперь поменяем местами эти два элемента и продолжим процесс «просмотра с обменом», пока два просмотра не встретятся где-то в середине массива. В результате массив разделится на две части: левую – с ключами, меньшими, чем x, и правую – с ключами большими х. Теперь этот процесс разделения представим в виде процедуры (программа 2.4).
Procedure partition;
Var w,x: item;
Begin i:=1; j:=n;
Случайно выбрать x;
Repeat
While a[i].key < x.key do i:=i + 1;
While x.key < a[j].key do j:=j - 1;
If i <= j then
Begin w:=a[i]; a[i]:=a[j]; a[j]:=w;
i:=i+1; j:=j-1
End
until i > j
end;
Программа 2.4. Сортировка с помощью разделения.
Обратите внимание, что вместо отношений > и < используются ≥ и ≤, а в заголовке цикла с WHILE — их отрицания < и >. При таких изменениях x выступает в роли барьера для того и другого просмотра. Если взять в качестве x для сравнения средний ключ 42, то в массиве ключей
44 55 12 42 94 06 18 67
для разделения понадобятся два обмена: 18 ó 44 и 6 ó 55
18 06 12 42 94 55 44 67
Последние значения индексов таковы: i = 5, a j = 3. Ключи a 1... a i-1 меньше или равны ключу х = 42, а ключи a j+1... а n больше или равны х. Следовательно, существует две части, а именно:
a k. key <= x. key для: k = 1, …, i -1,
(*)
a k. key >= x. key для: k = j +1, …, n.
И, следовательно,
a k. key = x. key k = j +1, …, I -1
Описанный алгоритм очень прост и эффективен, поскольку главные сравниваемые величины i, j и x можно хранить во время просмотра в быстрых регистрах машины. Однако он может оказаться и неудачным, что, например, происходит в случае n идентичных ключей: для разделения нужно n /2 обменов. Этих вовсе необязательных обменов можно избежать, если операторы просмотра заменить на такие:
While a [ i ]. key <= x.key do i: = i+1;
While x.key <= a[ j ]. key do j: = j -1
Однако в этом случае выбранный элемент x, находящийся среди компонент массива, уже не работает как барьер для двух разнонаправленных просмотров. В результате просмотры массива со всеми идентичными ключами приведут, если только не использовать более сложные условия их окончания, к переходу через границы массива. Простота условий, употребленных в программе 2.4, вполне оправдывает те дополнительные обмены, которые происходят в среднем относительно редко. Можно еще немного сэкономить, если изменить заголовок, управляющий самим обменом: от i <= j перейти к i < j. Однако это изменение не должно касаться двух операторов:
i: = i + 1; j: = j - 1.
Поэтому для них потребуется отдельный условный оператор. Необходимость условия i <= j можно проиллюстрировать следующим примером при x = 2:
1 1 1 2 1 1 1
Первый просмотр и обмен дают
1 1 1 1 1 1 2,
причем i = 5, j = 6. Второй просмотр не изменяет массив и заканчивается с i = 7 и j = 6. Если бы обмен не подчинялся условию i <= j, то произошел бы ошибочный обмен a 6 и a 7.
Убедиться в правильности алгоритма разделения можно, удостоверившись, что отношения (*) представляют собой инварианты оператора цикла с Repeat. Вначале при i = 1 и j = n их истинность тривиальна, а при выходе с i > j они дают как раз желаемый результат.
Теперь напомним, что наша цель — не только провести разделение на части исходного массива элементов, но и отсортировать его. Сортировку от разделения отделяет, однако, лишь небольшой шаг: нужно применить этот процесс к получившимся двум частям, затем — к частям частей, и так до тех пор, пока каждая из частей не будет состоять из одного-единственного элемента. Эти действия описываются листингом программы 2.5.
procedure QuickSort;
procedure sort(l,r:index);
var i,j:index; x,w:item;
Begin
i:=l; j:=r;
x:=a[(l+r) div 2];
Repeat
while a[i].key<x.key do i:=i+1;
while x.key<a[j].key do j:=j-1;
if i<=j then
begin w:=a[i]; a[i]:=a[j]; a[j]:=w;
i:=i+1; j:=j-1
End
until i>j;
if l<j then sort(l,j);
if l<r then sort(i,r)
end;
Begin
sort (1,n)
end;
Программа 2.5. Быстрая сортировка (Quicksort)
Анализ Quicksort. В благоприятных ситуациях каждый процесс разделения расщепляет массив на две половины и для сортировки требуется всего log n проходов. В результате общее число сравнений равно n*log n, а общее число обменов n* log(n)/6. Удивительный, однако, факт: средняя производительность Quicksort при случайном выборе границы отличается от упомянутого оптимального варианта лишь коэффициентом 2*ln (2).
Как бы то ни было, но Quicksort присущи и некоторые недостатки. Главный из них — недостаточно высокая производительность при небольших n, впрочем, этим грешат все усовершенствованные методы. Однако данный метод имеет то преимущество, что для обработки небольших частей в него можно легко включить какой-либо из прямых методов сортировки. Это особенно удобно делать в случае рекурсивной версии программы.
Остается все еще вопрос о самом плохом случае. Как тогда будет работать Quicksort? К несчастью, ответ неутешителен  и демонстрирует одно неприятное свойство Quicksort. Разберем, скажем, тот несчастный случай, когда каждый раз для сравнения выбирается наибольшее из всех значений в указанной части. Тогда на каждом этапе сегмент из n элементов будет расщепляться на левую часть, состоящую из n -1 элементов, и правую, состоящую из одного-единственного элемента. В результате потребуется n (а не log n) разделений и наихудшая производительность метода будет порядка n 2.
и демонстрирует одно неприятное свойство Quicksort. Разберем, скажем, тот несчастный случай, когда каждый раз для сравнения выбирается наибольшее из всех значений в указанной части. Тогда на каждом этапе сегмент из n элементов будет расщепляться на левую часть, состоящую из n -1 элементов, и правую, состоящую из одного-единственного элемента. В результате потребуется n (а не log n) разделений и наихудшая производительность метода будет порядка n 2.
Явно видно, что главное заключается в выборе элемента для сравнения - х. В нашей редакции им становится средний элемент. Заметим, однако, что почти с тем же успехом можно выбирать первый или последний. В этих случаях хуже всего будет, если массив окажется первоначально, уже упорядочен, ведь Quicksort определенно "не любит" такую тривиальную работу и предпочитает иметь дело с неупорядоченными массивами. Выбирая средний элемент, мы как бы затушевываем эту странную особенность Quicksort, поскольку в этом случае первоначально упорядоченный массив будет уже оптимальным вариантом. Таким образом, фактически средняя производительность при выборе среднего элемента чуточку улучшается. Сам Хоар предполагает, что x надо выбирать случайно. Такой разумный выбор мало влияет на среднюю производительность Quicksort, но зато значительно ее улучшает (в наихудших случаях). В некотором смысле быстрая сортировка напоминает азартную игру: всегда следует учитывать, сколько можно проиграть в случае невезения.
Заканчивая наш обзор усовершенствованных методов сортировки, мы попытаемся сравнить их эффективность. Как и раньше, n — число сортируемых элементов, а С и М — соответственно число необходимых сравнений ключей и число обменов. Для всех прямых методов сортировки можно дать точные аналитические формулы. Для усовершенствованных методов нет сколько-либо осмысленных, простых и точных формул. Существенно, однако, что в случае сортировки Шелла вычислительные затраты составляют с*n 1.2, а для HeapSort и Quicksort — с* n* log n, где с — соответствующие коэффициенты.
Эти формулы просто вводят грубую меру для производительности как функции n и позволяют разбить алгоритмы сортировки на примитивные, прямые методы (n 2) и на усложненные или "логарифмические" методы (n * log(n)).
Рассмотрев, несколько различных усложненных методов сортировки массивов нетрудно заметить главный недостаток – недостаточно высокая производительность при небольших n. Действительно эти сортировки не рекомендуется применять для небольшого числа элементов (для этого существуют простые методы сортировки). Хотя и это можно исправить, путем включения простых методов сортировки для небольших n.
Итак, сделаем вывод: выбор определенного метода сортировки зависит от структуры обрабатываемых данных, а также от количества элементов. При решении определенной задачи, выбранный метод сортировки должен быть наиболее эффективным.
Лекция № 3.
Тема: С ортировка последовательных файлов
Основные вопросы, рассматриваемые на лекции:
- Особенности сортировки последовательных файлов.
- Прямое слияние.
К сожалению, алгоритмы сортировки, рассмотренные в предыдущих лекциях, неприменимы, если сортируемые данные не помещаются в оперативной памяти, а, например, расположены на внешнем запоминающем устройстве с последовательным доступом, таком, как магнитная лента. В этом случае мы описываем данные как (последовательный) файл, который характеризуется тем, что в каждый момент имеется непосредственный доступ к одному и только одному элементу. Это — строгое ограничение по сравнению с возможностями, которые дает массив, и поэтому здесь приходится применять другие методы сортировки. Основной метод — это сортировка слиянием. Слияние означает объединение двух (или более) упорядоченных последовательностей в одну упорядоченную последовательность при помощи циклического выбора элементов, доступных в данный момент. Слияние — намного более простая операция, чем сортировка; она используется в качестве вспомогательной в более сложном процессе последовательной сортировки. Один из методов сортировки слиянием называется простым слиянием и состоит в следующем:
1. Последовательность а разбивается на две половины b и с.
2. Последовательности b и c сливаются при помощи объединения отдельных элементов в упорядоченные пары.
3. Полученной последовательности присваивается имя a, и повторяются шаги 1 и 2; на этот раз упорядоченные пары сливаются в упорядоченные четверки.
4. Предыдущие шаги повторяются; четверки сливаются в восьмерки, и весь процесс продолжается до тех пор, пока не будет упорядочена вся последовательность, ведь длины сливаемых последовательностей каждый раз удваиваются.
В качестве примера рассмотрим последовательность
44 55 12 42 94 18 06 67
На первом шаге разбиение дает последовательности
44 55 12 42
94 18 06 67
Слияние отдельных компонент (которые являются упорядоченными последовательностями длины 1) в упорядоченные пары дает
44 94 ' 18 55 ' 06 12 ' 42 67
Повое разбиение пополам и слияние упорядоченных пар дают
06 12 44 94 ' 18 42 55 67
Третье разбиение и слияние приводят, наконец, к нужному результату:
06 12 18 42 44 55 67 94
Операция, которая однократно обрабатывает все множество данных, называется фазой, а наименьший подпроцесс, который, повторяясь, образует процесс сортировки, называется проходом или этапом. В приведенном выше примере сортировка производится за три прохода, каждый проход состоит из фазы разбиения и фазы слияния. Для выполнения сортировки требуются три магнитные ленты, поэтому процесс называется трехленточным слиянием.
Собственно говоря, фазы разбиения не относятся к сортировке, поскольку они никак не переставляют элементы; в каком-то смысле они непродуктивны, хотя и составляют половину всех операций переписи. Их можно удалить, объединив фазы разбиения и слияния. Вместо того чтобы сливать элементы в одну последовательность, результат слияния сразу распределяют на две ленты, которые на следующем проходе будут входными. В отличие от двухфазного слияния этот метод называется однофазным или сбалансированным слиянием. Оно имеет явные преимущества, так как требует вдвое меньше операций переписи, но это достигается ценой использования четвертой ленты.
Разберем программу слияния подробно; предположим сначала, что данные расположены в виде массива, который, однако, можно просматривать только строго последовательно.
Вместо двух файлов можно легко использовать один массив, если рассматривать его как последовательность с двумя концами. Вместо того чтобы сливать элементы из двух исходных файлов, мы можем брать их с двух концов массива. Таким образом, общий вид объединенной фазы слияния-разбиения можно изобразить, как показано на рис. 3.1.
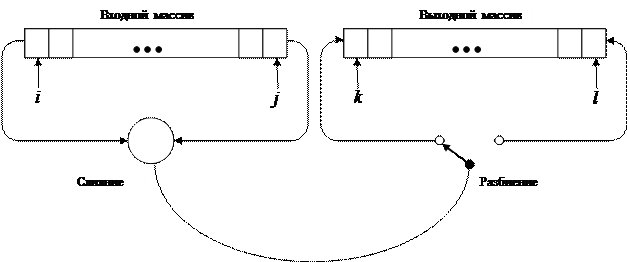
Рис. 3.1. Сортировка двух массивов методом слияния
Направление пересылки сливаемых элементов меняется (переключается) после каждой упорядоченной пары на первом проходе, после каждой упорядоченной четверки на втором проходе и т. д.; таким образом равномерно заполняются две выходные последовательности, представленные двумя концами одного массива (выходного). После каждого прохода два массива меняются ролями: входной становится выходным и наоборот. Программу можно еще больше упростить, объединив два концептуально различных массива в один массив двойной длины. Итак, данные будут представлены следующим образом:
a: array [l..2* n ] of item
Пусть индексы i и j указывают два исходных элемента, тогда как k и l обозначают два места пересылки (см. рис. 3.1). Исходные данные — это, разумеется, элементы а 1,..., а n. Очевидно, что нужна булевская переменная up для указания направления пересылки данных; up = true будет означать, что на текущем проходе компоненты а 1,..., а n будут пересылаться «вверх» — в переменные аn+ 1,..., а2 n, тогда как up — false будет указывать, что аn+ 1,..., а2 n должны переписываться «вниз» —в а 1,..., а n. Значение up строго чередуется между двумя последовательными проходами. И наконец, вводится переменная р для обозначения длины сливаемых подпоследовательностей (р -наборов). Ее начальное значение равно 1, и оно удваивается перед каждым очередным проходом. Для простоты мы будем считать, что n — всегда степень двойки. Итак, первая версия программы простого слияния имеет такой вид:
procedure mergesort;
var i,j,k,l: index;
up: Boolean; p: integer;
begin up:== true; p: = 1;
repeat { инициация индексов}
if up then
begin i:= 1; j:= n; k:= n + 1; l:= 2* n
end else
begin k:=1; l:= n; i:= n + 1; j:= 2* n end;
«слияние р-наборов последовательностей i и j
в последовательности k и l »;
uр:= - up; p:= 2 *р
until р = п
End
На следующем этапе мы уточняем действие, описанное на естественном языке (внутри кавычек). Ясно, что этот проход, обрабатывающий n элементов, состоит из последовательных слияний р -наборов. После каждого отдельного слияния направление пересылки переключается из нижнего в верхний конец выходного массива или наоборот, чтобы обеспечить одинаковое распределение в обоих направлениях. Если сливаемые элементы посылаются в нижний конец массива, то индексом пересылки служит k и k увеличивается на 1 после каждой пересылки элемента. Если же они пересылаются в верхний конец массива, то индексом пересылки является l и l после каждой пересылки уменьшается на 1. Чтобы упростить операцию слияния, мы будем считать, что место пересылки всегда обозначается через k, и будем менять местами значения k и l после слияния каждого р -набора, а приращение индекса обозначим через h, где h равно либо 1, либо -1. Уточнив таким образом «конструкцию», мы получаем
h:= 1; m:= n; { m-номера сливаемых элементов }
repeat q: = р; r: = р; т:= т-2*р;
«слияние q элементов из i и r элементов из j,
индекс засылки есть k с приращением h »;
h:= - h;
обмен значениями k и l
until m = 0
На следующем этапе уточнения нужно сформулировать саму операцию слияния. Здесь следует учесть, что остаток подпоследовательности, которая остается непустой после слияния, добавляется к выходной последовательности при помощи простого копирования.
while (q<>0) and (r<>0) do
begin {выбор элемента из i uли j}
if a[i].key < a[j].key then
begin «пересылка элемента из i в k,
увеличение i и k»; q:= q -1
End else
begin «пересылка элемента из j в k,
увеличение j и k »; r:=r - 1
End
end;
«копирование остатка последовательности i »;
«копирование остатка последовательности j »
После уточнения операций копирования остатков программа будет ясна во всех деталях. Перед тем как записать ее полностью, мы хотим устранить ограничение, в соответствии с которым n должно быть степенью двойки. На какую часть алгоритма это повлияет? Легко убедиться в том, что в более общей ситуации лучше всего использовать прежний метод до тех пор, пока это возможно. В данном случае это означает, что мы продолжаем слияние р-наборов, пока длина остатков входных последовательностей не станет меньше p. Это влияет только на ту часть, где определяются значения q и r — длины последовательностей, которые предстоит слить. Вместо трех операторов
q:= р; r:= p; m:= m - 2 *р
используются следующие четыре оператора, и, как может убедиться читатель, здесь эффективно применяется описанная выше стратегия; заметим, что m обозначает общее число элементов в двух входных последовательностях, которые осталось слить:
if т >= р then q:= p else q:= m; m:= m - q;
if т >= р then r:= p else r:= m; m:= m - r;
И наконец, чтобы обеспечить окончание работы программы, нужно заменить условие р = n, управляющее внешним циклом, на р >= n. После этих модификаций мы можем попытаться описать весь алгоритм в виде законченной программы (см. программу 3.1).
procedure mergesort;
var i,j,k,l,t: index;
h,m,p,q,r:integer; up:boolean;
begin up:=true; p:=1;
repeat h:=1; m:=n;
if up then
begin i:=1; j:=n; k:=n+1; l:=2*n;
end else
begin k:=1; l:=n; i:=n+1; j:=2*n
end;
repeat
if m>=p then q:=p else q:=m; m:=m-q;
if m>=p then r:=p else r:=m; m:=m-r;
while (q<>0) and (r<>0) do
begin
if a[i].key < a[j]. key then
begin a[k]:=a[i]; k:=k+h; i:=i+1; q:=q-1;
end else
begin a[k]:=a[j]; k:=k+h; j:=j-1; r:=r-1
end
end;
while r<>0 do
begin a[k]:=a[j]; k:=k+h; j:=j-1; r:=r-1
end;
while q<>0 do
begin a[k]:=a[i]; k:=k+h; i:=i+1; q:=q-1
end;
h:=-h; t:=k; k:=l; l:=t
until m=0;
up:= not up; p:=2*p
until p>=n;
if not up then
for i:=1 to n do a[i]:=a[i+n]
end;
Программа 3.1.
Анализ сортировки слиянием. Поскольку на каждом проходе р удваивается и сортировка заканчивается, как только р >= n, она требует [log2 n ] проходов. По определению при каждом проходе все множество из n элементов копируется ровно один раз. Следовательно, общее число пересылок равно
М = п [log2 n ]
Число С сравнений по ключу еще меньше, чем М, так как при копировании остатка последовательности сравнения не производятся. Но, поскольку сортировка слиянием обычно применяется при работе с внешними запоминающими устройствами, стоимость операций пересылки часто на несколько порядков превышает стоимость сравнений. Поэтому подробный анализ числа сравнений не представляет особого практического интереса.
Алгоритм сортировки слиянием выдерживает сравнение даже с усовершенствованными методами сортировки, которые обсуждались в предыдущей лекции. Но затраты на управление индексами довольно высоки, кроме того, существенным недостатком является использование памяти размером 2 n элементов. Поэтому сортировка слиянием редко применяется при работе с массивами, т. е. данными, расположенными в оперативной памяти.
Лекция № 4.
Тема: Введение в рекурсию. Когда не нужно использовать рекурсию.
Основные вопросы, рассматриваемые на лекции:
- Рекурсия, терминология.
- Примеры задач, когда не нужно использовать рекурсию.
Содержание лекционного материала
Есть тема, которую часто опускают во вводных курсах программирования, хотя она и играет важную концептуальную роль во многих алгоритмах, – это рекурсия. Поэтому эта декция посвящена рекурсивным решениям. В ней показано, что рекурсия – обобщение понятия повторения (итерации), и как таковая она представляет собой важную и мощную концепцию программирования. К несчастью, во многих курсах программирования рекурсия используется в примерах, где достаточно простой итерации. Вместо этого хотелось бы обратить внимание на особенно интересный раздел программирования – это задачи из области «искусственного интеллекта». Здесь нужно строить алгоритмы, которые находят решение определенной задачи не по фиксированным правилам вычисления, а методом проб и ошибок (алгоритмы с возвратом).
Выясним, что такое рекурсия? Во всех языках программирования можно описать функцию, как подпрограмму с параметром, и вызывать ее при необходимости. Однако не вовсех языках программирования функция может вызывать сама себя (например, в Фортране). Если же функция в процессе выполнения вызывает сама себя, то такой прием называется рекурсией. Итак, рекурсия — это такой способ организации вспомогательного алгоритма (подпрограммы), при котором эта подпрограмма (процедура или функция) в ходе выполнения ее операторов обращается сама к себе. Вообще, рекурсивным называется любой объект, который частично определяется через себя.
Тут нужно задуматься – что значит, функция вызывает сама себя? Обычно конструкции языков программирования можно более или менее представить и проиллюстрировать примерами из реальной жизни. А как же представить наглядно функцию, вызывающую самою себя? Лучшей моделью, на мой взгляд, служит английский стишок «Дом, который построил Джек», а еще лучшей – пародия на него, стишок одной команды КВН из книжки «КВН раскрывает секреты» вышедшей в 1967 году (М. Молодая гвардия).
Вот стенд, который построил студент,
А вот космическая частица,
Которая с бешеной скоростью мчится
В стенде, который построил студент.
А вот инженер молодой, бледнолицый,
Который клянет и судьбу, и частицу,
Которая с бешеной скоростью мчится
В стенде, который построил студент.
А вот кандидат, горделивый не в меру,
Который блистательно сделал карьеру,
Совместно работая с тем инженером,
Который клянет и судьбу и частицу,
Которая с бешеной скоростью мчится
В стенде, который построил студент.
А вот начальник, на вид простоватый,
Который был шефом того кандидата,
Который блистательно сделал карьеру,
Совместно работая с тем инженером,
Который клянет и судьбу и частицу,
Которая с бешеной скоростью мчится
В стенде, который построил студент.
А вот консультант от академии,
С которым встречался время от времени
Тот самый начальник, на вид простоватый,
Который был шефом того кандидата,
Который блистательно сделал карьеру,
Совместно работая с тем инженером,
Который клянет и судьбу и частицу,
Которая с бешеной скоростью мчится
В стенде, который построил студент.
А вот отчетов горы бумажные,
В которых копалась комиссия важная,
Которая выдала крупную премию,
Тому консультанту из академии,
Начальнику дали за вид простоватый,
Кусок уделили тому кандидату,
Который блистательно сделал карьеру,
Остатки вручили тому инженеру,
Который уже не ругает частицу,
Которая с бешеной скоростью мчится
В стенде, который построил
СТУДЕНТ
А кто не видел рекламной картинки, которая содержит свое собственное изображение?

Рекурсия является особенно мощным средством в математических определениях. Известны примеры рекурсивных определений натуральных чисел, некоторых функций:
Натуральные числа:
(a) 1 есть натуральное число;
(b) целое число, следующее за натуральным, есть натуральное число.
Функция факториал n! для неотрицательных целых чисел:
(a) 0! = 1,
(b) если n > 0, то n! = n × (n - 1)!
Вот еще одно рекурсивное определение.
(a) 3 коровы – это стадо коров.
(b) Стадо из n коров – это стадо из n –1 коровы и еще одна корова.
Попробуем применить это определение для проверки, является ли стадом группа из пяти коров (обозначим ее К5). Объект К5 не удовлетворяет первому пункту определения, поскольку пять коров – это не три коровы. Согласно второму пункту К5 – стадо, если там есть одна корова, а остальная часть К5, назовем ее К4, – тоже стадо коров. Решение относительно объекта К5 откладывается, пока не будет принято решение относительно К4. Объект К4 снова не подходит под первый пункт, а второй пункт гласит, что К4 – стадо, если объект К3, полученный из К4 путем отделения одной коровы, тоже стадо. Решение о К4 тоже откладывается. Наконец, объект К3 удовлетворяет первому пункту определения, и мы можем смело утверждать, что К3– стадо коров. Теперь и о К4 можно утверждать, что это стадо, а значит, и К5 является стадом коров.
Любое рекурсивное определение состоит из двух частей. Эти части принято называть базовой и рекурсивной частями. Базовая часть является нерекурсивной и задает определение для некоторой фиксированной части объектов. Рекурсивная часть определяет понятие через него же и записывается так, чтобы при цепочке повторных применений она редуцировалась бы к базе.
Очевидно, что мощность рекурсии связана с тем, что она позволяет определить бесконечное множество объектов с помощью конечного высказывания. Точно так же бесконечные вычисления можно описать с помощью конечной рекурсивной программы, даже если эта программа не содержит явных циклов. Однако лучше всего использовать рекурсивные алгоритмы в тех случаях, когда решаемая задача, или вычисляемая функция, или обрабатываемая структура данных определены с помощью рекурсии. В общем виде рекурсивную программу Р можно изобразить как композицию R базовых операторов Si (не содержащих Р) и самой Р:
Рº R [Si, P ]. (4.1)
Необходимое и достаточное средство для рекурсивного представления программ – это описание процедур, или подпрограмм, так как оно позволяет присваивать какому-либо оператору имя, с помощью которого можно вызвать этот оператор. Если процедура Р содержит явное обращение к самой себе, то она называется прямо рекурсивной; если Р содержит обращение к процедуре Q, которая содержит (прямо или косвенно) обращение к Р, то Р называется косвенно рекурсивной. Поэтому использование рекурсии не всегда сразу видно из текста программы.
С процедурой возврата принято связывать некоторое множество локальных объектов, т.е. переменных, констант, типов и процедур, которые определены локально в этой процедуре, а вне ее не существуют или не имеют смысла. Каждый раз, когда такая процедура рекурсивно вызывается, для нее создается новое множество локальных переменных. Хотя они имеют те же имена, что и соответствующие элементы множества локальных переменных, созданного при предыдущем обращении к этой же процедуре, их значения различны. Следующее правило области действия идентификаторов позволяют исключить какой-либо конфликт при использовании имен: идентификаторы всегда ссылаются на множество переменных, созданное последним. То же правило относится к параметрам процедуры.
Подобно операторам цикла, рекурсивные процедуры могут привести к бесконечным вычислениям. Поэтому необходимо рассмотреть проблему окончания работы процедур ( определить граничное условие ). Очевидно, что для того, чтобы работа когда-либо завершилась, необходимо, чтобы рекурсивное обращение к процедуре Р подчинялось условию В, которое в какой-то момент перестает выполняться. Поэтому более точно схему рекурсивных алгоритмов можно представить так:
P º if B then R [Si, P], (4.2)
или
P º R [Si, if B then P] (4.3)
Основной способ доказать, что выполнение операторов цикла когда-либо заканчивается, – определить функцию f(x) (x – множество переменных программы), такую, что f(x)≤0 удовлетворяет условию окончания цикла (с предусловием или с постусловием), и доказать, что при каждом повторении f(x) уменьшается. Точно так же можно доказать, что выполнение рекурсивной процедуры Р когда-либо завершиться, показав, что каждое выполнение Р уменьшает f(x). Наиболее надежный способ обеспечить окончание процедуры – связать с Р параметр (значение), скажем п, и рекурсивно вызвать Р со значением этого параметра п – 1. Тогда замена условия В на п > 0 гарантирует окончание работы. Это можно изобразить следующими схемами программ:
P(n) º if n > 0 then R [Si, P(n-1], (4.4)
P(n) º R [Si, if n > 0 then P (n-1)] (4.5)
Итак, обращение к рекурсивной подпрограмме ничем не отличается от вызова любой другой подпрограммы. При этом при каждом новом рекурсивном обращении в памяти создаётся новая копия подпрограммы со всеми локальными переменными. Такие копии будут порождаться до выхода на граничное условие. Очевидно, в случае отсутствия граничного условия, неограниченный рост числа таких копий приведёт к аварийному завершению программы за счёт переполнения стека.
Порождение все новых копий рекурсивной подпрограммы до выхода на граничное условие называется рекурсивным спуском. Максимальное количество копий рекурсивной подпрограммы, которое одновременно может находиться в памяти компьютера, называется глубиной рекурсии. Завершение работы рекурсивных подпрограмм, вплоть до самой первой, инициировавшей рекурсивные вызовы, называется рекурсивным подъёмом.
Выполнение действий в рекурсивной подпрограмме может быть организовано одним из вариантов:
| Begin P; Операторы End; | Begin Операторы; P End; | Begin Операторы; P; Операторы End; |
| Рекурсивный подъем | Рекурсивный спуск | И рекурсивный спуск, и рекурсивный подъем |
Здесь P — рекурсивная подпрограмма. Как видно, действия могут выполняться либо на одном из этапов рекурсивного обращения, либо на обоих сразу.