Теперь рассмотрим удаление вершины из ДП. По сравнению с добавлением удаление реализуется более сложным алгоритмом, поскольку добавляемая вершина всегда является терминальной, а удаляться может ЛЮБАЯ, в том числе и нетерминальная. При этом может возникать несколько различных ситуаций.
Рассмотрим фрагмент ДП с целыми ключами.
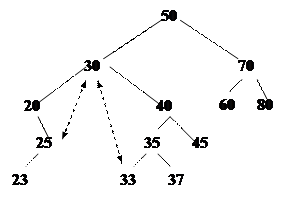 |
Ситуация 1. Удаляемая вершина не имеет ни одного потомка, т.е. является терминальной. Удаление реализуется очень легко обнулением соответствующего указателя у родителя. Например, для удаления вершины с ключом 23 достаточно установить 25.left = nil.
Ситуация 2. Удаляемая вершина имеет только одного потомка. В этом случае удаляемая вершина вместе со своим потомком и родителем образуют фрагмент линейного списка. Удаление реализуется простым изменением указателя у родительского элемента. Например, для удаления вершины с ключом 20 достаточно установить 30.left = 20.right = 25
Ситуация 3. Пусть удаляемая вершина имеет двух потомков. Этот случай наиболее сложен, поскольку нельзя просто в родительской вершине изменить соответствующее ссылочное поле на адрес одного из потомков удаляемой вершины. Это может нарушить структуру дерева поиска. Например, замена вершины 30 на одного из ее непосредственных потомков 20 или 40 сразу нарушает структуру дерева поиска.
Существует специальное правило для определения вершины, которая должна заменить удаляемую. Это правило состоит из двух взаимоисключающих действий:
· либо войти в левое поддерево удаляемой вершины и в этом поддереве спустится как можно глубже, придерживаясь только правых потомков; это позволяет найти в дереве ближайшую меньшую вершину (например, для вершины 30 это будет вершина 25)
· либо войти в правое поддерево удаляемой вершины и спустится в нем как можно глубже придерживаясь только левых потомков; это позволяет найти ближайшую бОльшую вершину (например, для той же вершины 30 это будет вершина 33).
Перейдем к программной реализации процедуры удаления. Поскольку при удалении могут изменяться связи между внутренними вершинами дерева, удобно (но, конечно же, не обязательно) использовать рекурсивную реализацию. Основная процедура DeleteNodeрекурсивно вызывает сама себя для поиска удаляемой вершины. После нахождения удаляемой вершины процедура DeleteNodeопределяет число ее потомков. Если потомков не более одного, выполняется само удаление. Если потомков два, то вызывается вспомогательная рекурсивная процедура Changer для поиска вершины-заменителя.
Procedure DeleteNode (var pCurrent: Tp);
Var pTemp: Tp;
Procedure Changer (var p: Tp);
begin
{реализация рассматривается ниже}
end;
begin
if pCurrent = nil then “удаляемой вершины нет, ничего не делаем”
Else
if x < pCcurrent^.inf then DeleteNode (pCcurrent^.left)
Else
if x > pCurrent^.inf then DeleteNode (pCurrent^.right)
else {удаляемая вершина найдена}
begin
pTemp:= pCurrent;
if pTemp^.right = nil then pCurrent:= pTemp^.left
Else
if pTemp^.left = nil then pCurrent:= pTemp^.right
else {два потомка, ищем заменитель}
Changer (pCurrent^.left); { а можно и pCurrent^.right }
Dispose (pTemp);
end;
end;
Схема процедуры Changer:
begin
if p^.right <> nil then Changer (p^.right)
else {правое поддерево пустое, заменитель найден, делаем обмен}
Begin
pTemp^.inf:= p^.inf; {заменяем информац. часть удаляемой вершины}
pTemp:= p; {pTemp теперь определяет вершину-заменитель}
p:= p^.left; {выходной параметр адресует левого потомка заменителя}
end;
end;
Дополнительный комментарий к процедурам. Подпрограмма Changer в качестве входного значения получает адрес левого (или правого) потомка удаляемой вершины и рекурсивно находит вершину-заменитель. После этого информационная часть удаляемой вершины заменяется содержимым вершины-заменителя, т.е. фактического удаления вершины не происходит. Это позволяет сохранить неизменными обе связи этой вершины с ее потомками. Удаление реализуется относительно вершины-заменителя, для чего ссылка pTemp после обмена устанавливается в адрес этой вершины. Кроме того, в самом конце процедуры Changer устанавливается новое значение выходного параметра p: оно равно адресу левого потомка вершины-заменителя. Это необходимо для правильного изменения адресной части вершины-родителя для вершины-заменителя. Само изменение происходит при отработке механизма возвратов из рекурсивных вызовов процедуры Changer. Когда все эти возвраты отработают, происходит возврат в основную процедуру DeleteNode, которая освобождает память, занимаемую вершиной-заменителем. Отметим, что приведенная выше реализация процедуры Changer ориентирована на поиск в левом поддереве удаляемой вершины и требует симметричного изменения для поиска заменителя в правом поддереве.
Для окончательного уяснения данного алгоритма настоятельно рекомендуем провести ручную пошаговую отработку его для небольшого примера, как это было сделано для значительно более простого алгоритма построения идеально сбалансированного дерева.
Практические задания
Задание 1. Построение и обработка двоичных деревьев поиска. Реализовать программу, выполняющую следующий набор операций с деревьями поиска:
· поиск вершины с заданным значением ключа с выводом счетчика числа появлений данного ключа
· добавление новой вершины в соответствии со значением ее ключа или увеличение счетчика числа появлений
· построчный вывод дерева в наглядном виде с помощью обратно-симметричного обхода
· вывод всех вершин в одну строку по порядку следования ключей с указанием для каждой вершины значения ее счетчика появлений
· удаление вершины с заданным значением ключа
Рекомендации:
· Объявить и реализовать подпрограмму поиска. Поиск начинается с корня дерева и в цикле для каждой вершины сравнивается ее ключ с заданным значением. При совпадении ключей поиска заканчивается с выводом значения счетчика числа появлений данного ключа. При несовпадении поиск продолжается в левом или правом поддереве текущей вершины
· Объявить и реализовать рекурсивную подпрограмму добавления новой вершины в дерево. Подпрограмма использует один параметр-переменную, определяющую адрес текущей вершины. Если при очередном вызове подпрограммы этот адрес равен nil, то производится добавление нового элемента с установкой всех необходимых полей. В противном случае продолжается поиск подходящего места для новой вершины за счет рекурсивного вызова подпрограммы с адресом левого или правого поддерева. При совпадении ключей надо просто увеличить значение счетчика появлений
· Объявить и реализовать не-рекурсивный вариант подпрограммы добавления новой вершины в дерево. Необходимы две ссылочные переменные – адрес текущей вершины и адрес ее родителя. Сначала в цикле ищется подходящее место за счет сравнения ключей и перехода влево или вправо. Поиск заканчивается либо по пустому значению текущего адреса, либо в случае совпадения ключей (здесь просто увеличивается счетчик числа появлений). После окончания поиска либо создается корневая вершина, либо добавляется новая вершина как левый или правый потомок родительской вершины.
· Объявить и реализовать рекурсивную подпрограмму для построчного вывода дерева в обратно-симметричном порядке. Эту подпрограмму без каких-либо изменений можно взять из предыдущей работы.
· Объявить и реализовать рекурсивную подпрограмму для вывода всех вершин в одну строку в соответствии с возрастанием их ключей. Основа – обход в симметричном порядке. Дополнительно рядом со значением ключа в скобках должно выводится значение счетчика повторений данного ключа. Например:
5(1) 11(2) 19(5) 33(1) 34(4).....
· Объявить и реализовать подпрограмму удаления вершины: запрашивается ключ вершины, организуется ее поиск, при отсутствии вершины выводится сообщение, при нахождении вершины проверяется число ее потомков и при необходимости выполняется поиск вершины-заменителя
Главная программа должна предоставлять следующие возможности:
· создание дерева с заданным числом вершин со случайными ключами
· добавление в дерево одной вершины с заданным пользователем значением ключа
· поиск в дереве вершины с заданным ключом
· построчный вывод дерева в наглядном виде
· вывод всех вершин в порядке возрастания их ключей
· удаление вершины с заданным ключом
Задание 2. Построение таблицы символических имен с помощью дерева поиска. Постановка задачи формулируется следующим образом.
Деревья поиска широко используются компиляторами при обработке текстов программ на языках высокого уровня. Одной из важнейших задач любого компилятора является выделение во входном тексте программы всех символических имен (ключевых слов, пользовательских идентификаторов для обозначения типов, переменных, подпрограмм) и построение их в виде таблицы с запоминанием номеров строк, где эти имена встречаются. Поскольку каждое выделенное из текста имя должно отыскиваться в этой таблице, а число повторений одного и того же имени в тексте программы может быть весьма большим, важным для скорости всего процесса компиляции становится скорость поиска в таблице имен. Поэтому очень часто подобные таблицы реализуются в виде дерева поиска. Ключом поиска в таких деревьях являются текстовые имена, которые добавляются в дерево поиска в соответствии с обычными правилами упорядочивания по алфавиту.
Необходимо реализовать программу, выполняющую следующие действия:
· запрос имени исходного файла с текстом анализируемой программы
· чтение очередной строки и выделение из нее всех символических имен (будем считать, что имя – любая непрерывная последовательность букв и цифр, начинающаяся с буквы и не превышающая по длине 255 символов)
· запоминание очередного имени в дереве поиска вместе с номером строки исходного текста, где это имя найдено; поскольку одно и то же имя в тексте может встречаться многократно в разных строках, приходится с каждым именем-вершиной связывать вспомогательный линейный список номеров строк
· вывод построенной таблицы имен по алфавиту с помощью процедуры обхода дерева в симметричном порядке
· построчный вывод построенного дерева в наглядном представлении с помощью процедуры обхода дерева в обратно-симметричном порядке
Для упрощения программной реализации будем считать, что обрабатываемая программа удовлетворяет следующим непринципиальным условиям:
· в именах используются только строчные (малые) буквы
· отсутствуют комментарии
· отсутствуют текстовые константы, задаваемые с помощью кавычек ‘’
Например, пусть исходная программа имеет следующий вид:
program test;
var x, y: integer;
str: string;
Begin
x:= 1;
y:= x + 2;
write(x, y);
End.
Тогда для нее должна быть построена следующая таблица имен и дерево поиска:
|
| begin |  4 4
|
| end | |
| integer |   2 2
|
| program |  1 1
|
| str | |
| string |   3 3
|
| test |  1 1
|
| var |  2 2
|
| write | |
| x |  2 5 6 7 2 5 6 7
|
| y |  2 6 7 2 6 7
|
Рекомендации:
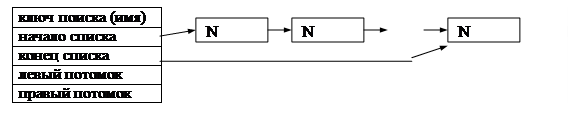
1. В разделе описания типов ввести два ссылочных типа данных для динамической реализации дерева поиска и вспомогательных линейных списков. Описать связанные с ними базовые типы, определяющие структуру вершин дерева и узлов списка. Вершина дерева должна содержать строковое ключевое поле, указатели на двух потомков и два указателя на начало и конец вспомогательного линейного списка.
 |
2. Объявить необходимые глобальные переменные, такие как номер обрабатываемой строки исходного текста и ее длина, номер обрабатываемого символа в строке (счетчик символов), сама текущая строка, текущее формируемое имя, имя исходного файла, файловая переменная, указатель на корень дерева
3. Объявить и реализовать рекурсивную подпрограмму добавления вершины в дерево поиска. За основу можно взять рассмотренную в предыдущей работе процедуру добавления, внеся в нее следующие небольшие дополнения:
· при вставке новой вершины создать первый (пока единственный!) узел вспомогательного линейного списка, заполнить его поля и поля созданной вершины дерева необходимыми значениями
· в случае совпадения текущего имени с ключом одной из вершин дерева добавить в конец вспомогательного списка новый узел с номером строки, где найдено данное имя
4. Объявить и реализовать рекурсивную подпрограмму для вывода построенной таблицы в порядке возрастания имен. Основа – обход дерева в симметричном порядке. Дополнительно для каждой вершины выводится список номеров строк, где используется данное имя. Для этого организуется проход по вспомогательному линейному списку от его начала до конца.
5. Объявить и реализовать рекурсивную подпрограмму для построчного вывода дерева в обратно-симметричном порядке. Эту подпрограмму без каких-либо изменений можно взять из предыдущей работы.
6. Реализовать главную программу, выполняющую основную работу по выделению имен из строк обрабатываемого текста. Формируемое имя объявляется как String, но обрабатывается как массив символов. Основной механизм формирования имени – посимвольная обработка текущей строки. Как только в строке после не-буквенных символов распознается буква, начинается выделение всех последующих буквенно-цифровых символов и формирование очередного имени. Обрабатываемая строка (тип String) рассматривается как массив символов. Удобно перед обработкой строки добавить в ее конце символ пробела. Номер текущего обрабатываемого символа задается переменной-счетчиком. Для отслеживания символов в формируемом имени также необходима переменная-счетчик.
Алгоритм работы главной программы:
· инициализация обработки исходного файла (запрос имени файла, открытие для чтения)
· цикл обработки строк исходного файла:
ü чтение очередной строки и определение ее длины
ü добавление в конец строки дополнительного символа пробела
ü инициализация счетчика символов
ü организация циклической обработки символов строки по следующему алгоритму:
a. если очередной символ есть буква, то:
Ø запомнить символ как первую букву имени
Ø организовать цикл просмотра следующих символов в строке, пока они являются буквами или цифрами, с добавлением этих символов к формируемому имени
Ø после окончания цикла установить длину сформированного имени (можно использовать нулевой элемент массива символов)
Ø вызвать подпрограмму для поиска сформированного имени в дереве
b. увеличить значение счетчика символов для перехода к анализу следующего символа
· вывод построенной таблицы в алфавитном порядке
· построчный вывод дерева поиска
6.5. Контрольные вопросы по теме
1. Какое дерево называется деревом поиска?
2. В чем состоит практическая важность использования деревьев поиска?
3. Какие преимущества имеет использование деревьев поиска для хранения упорядоченных данных по сравнению с массивами и списками?
4. Почему наивысшая эффективность поиска достигается у идеально сбалансированных деревьев?
5. Как находится максимально возможное число шагов при поиске в идеально сбалансированном дереве?
6. Приведите алгоритм поиска в дереве поиска.
7. Как программно реализуется поиск в дереве поиска?
8. Как выполняется добавление новой вершины в дерево поиска?
9. В чем смысл рекурсивной реализации алгоритма добавления вершины в дерево поиска?
10. Какой формальный параметр имеет рекурсивная процедура добавления вершины в дерево поиска и как он используется?
11. Приведите программную реализацию рекурсивной процедуры добавления вершины в дерево поиска.
12. Какие ссылочные переменные необходимы для нерекурсивной реализации процедуры добавления вершины в дерево поиска?
13. Как программно реализуется добавление нерекурсивная процедура добавления вершины в дерево поиска?
14. Какие ситуации могут возникать при удалении вершины из дерева поиска?
15. Что необходимо выполнить при удалении из дерева поиска вершины, имеющей двух потомков?
16. Какие правила существуют для определения вершины-заменителя при удалении из дерева поиска?
17. Опишите алгоритм удаления вершины из дерева поиска.
18. Приведите программную реализацию алгоритма удаления вершины из дерева поиска.
Тема 7. Дополнительные вопросы обработки деревьев. Графы.