Министерство науки и высшего образования Российской Федерации
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ АВТОНОМНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«Национальный исследовательский университет ИТМО»
(Университет ИТМО)
Факультет Факультет цифровых трансформаций
Образовательная программа09.04.02 Информационные системы и технологии
Направление подготовки(специальность)Стратегии и технологии цифровой трансформации
О Т Ч Е Т
о практике (указывается наименование практики)
Тема задания: как в индивидуальном задании
Обучающийся Шайбеков АланJ4141
Согласовано:
Руководитель практики от профильной организации: Ф.И.О., должность и место работы
Руководитель практики от университета: Ф.И.О., должность, наименование структурного подразделения
Практика пройдена с оценкой ____
Дата ____
Санкт-Петербург
20 22
Exploringmachinelearning:
A Bibliometric analysis of the Literature
Tableofcontents
INTRODUCTION............................................................................................ 3
DESIGN AND METHODOLOGY................................................................... 5
FINDINGS FOR TOPIC “MACHINE LEARNING”........................................ 7
1.1. The volume of Published Articles on Food and Innovation.............. 7
1.2. The languages and document type of Published Articles.................. 8
1.3. Publishing Countries......................................................................... 9
1.4. Research areas of Published Articles............................................... 12
1.5. Journals Analysis andFunding agencies.......................................... 13
1.6. Influential Authors in the topic “machine learning”........................ 16
1.7. The knowledge distribution structure.............................................. 21
1.8. The trending topic in machine learning........................................... 24
2. DATA PREPROCESSING IN MACHINE LEARNING............................ 26
2.1. The knowledge distribution structure for topic “machine learning” and “data preprocessing”....................................................................................... 26
2.2. The trending topic in data preprocessing........................................ 29
CONCLUSION............................................................................................... 31
BIBLIOGRAPHY........................................................................................... 35
Appendix........................................................................................................ 36
Introduction
The research is directed towards a bibliometric review of the literature and a visualization analysis of the topic “machine learning”. The main objective is to empirically analyze the main research directions, the volume, and directions based on VOSViewer software and the scientific databases Web of Science (WoS).
We considered a high quality of literature for the study, so we chose the ISI Web of Science (WOS). We used the WOS Core Database and WOS Russian Science Citation Index to create a sample dataset for our further analysis.
This study is the first in this direction. It is unique in that we identified the main goal to define common aspects, global trends, and future interdisciplinary points on the topic of standard machine learning tasks.
More specifically the present study addressed the following research questions:
1. What is the volume of published articles on the topic “machine learning”?
2. Which journals, authors, and academic articles are the most influential in this particular area of research?
3. What is the knowledge distribution structure in this topic?
4. Which kind of research topics have been addressed most frequently so far?
The bibliometric review has been chosen from a descriptive point of view. We use the information on the most cited authors and articles by topic “machine learning”. We used bibliometric methods to investigate empirically the published volume, intelligent structure, and potential directions of research in the field “machine learning”. For the analysis, we used VosViewer software [1 https://www.vosviewer.com/], which combines text mining and visualization of the results.
Design and methodology
The initial search based on the general topic “machine learning” indicated a large number of published articles (175,214 papers). The first publication “A Learning Machine: Part I” by R. M. Friedberg published in IBM Journal of Research and Development (Volume: 2, Issue: 1, Jan. 1958).
Considering the large volume of published articles, we redefined topics as two keywords at the same time: “machine learning” AND “graph”. We entered filters on document type and publication years. In order to answer the research questions of our study, we have developed a table with specified criteria for the selection of literature.
Table 1 – Search criteria and filters.
| Filters | SearchCriteria | Nb. ofArticles |
| Database | Web of Science Core databases | |
| Topic | (TS=(machine)) AND TS=(learning) | 164,886 |
| PublicationYears | 2012–2021 | 146,651 |
| Documenttype | article | 130,840 |
| WOS ResearchAres | ComputerScience | 44,706 |
| OpenAccess | AllOpenAccess | 19,041 |
Extractiondate 17.01.2022
To begin with, we identified the main keywords for analysis: "machine AND learning". The query search by Topic showed us 164,886 papers and the preliminary analysis demonstrated many papers which don’t connect to our main request. The search by Topic in WOS means searches by title, abstract, author keywords, and Keywords Plus. To make sure that we have high-quality publications for bibliometric analysis we set the filter for Document Type as Articles. We also limited WOS research areas to Computer Science only. As we will do screening of some articles we also set the filter on Open Access to make sure that we will have articles open to read and review.
We also decided to check the WOS Core database. We applied the same criteria and filters to this database.
Table 2 – Search criteria and filters.
| Filters | SearchCriteria | Nb. ofArticles |
| Database | Web of Science Core databases | |
| Topic | (TS=(machine learning)) AND TS=(data preprocessing) | 2,407 |
| PublicationYears | 2012–2021 | 2,193 |
| Documenttype | article | 2,092 |
| WOS ResearchAres | ComputerScience | |
| OpenAccess | AllOpenAccess |
We also created a thesaurus file “to perform data cleaning when creating a map based on bibliographic data” [https://www.vosviewer.com/documentation/Manual_VOSviewer_1.6.8.pdf]. In total, labels were identified with alternative labels, “indicating that the label is to be replaced by the alternative label” [https://www.vosviewer.com/documentation/Manual_VOSviewer_1.6.8.pdf].
Findings for topic “machine learning”
1.1. The volume of Published Articles on Food and Innovation
For a better scale of the literature in the machine learning fields of study, we generated a graph (Figure 1), in which can be seen the number of published articles related to the concept. The “machinelearning” conceptallowedustoretrieve 19,041 papers.
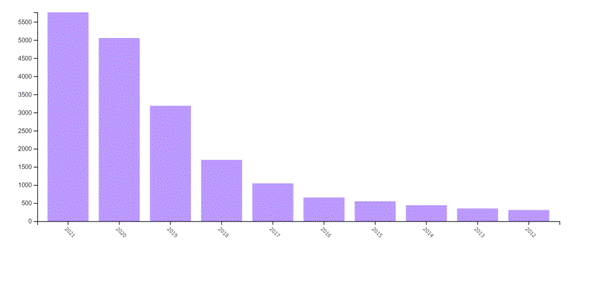
Figure 1 – The number of published articles in the period 2012–2021.
Figure 1 demonstrates that the number of publications has increased almost 19 times since 2011 from 309 to 5,765 publications in 2021. The extraction of the sample dataset was done on January 17, 2022, so publication years were set from January 01, 2012, to December 31, 2021. Over the past five years, we have seen a significant increase in the number of publications, so in 2017 there was an increase of almost 60% to 1043 articles compared to the previous year, the growth continued and in 2018 amounted to 62%, and in 2019 - 88% and in 2020 - 58%.
1.2. The languages and document type of Published Articles
The filter Document type was set as Article to have high-quality data for our analysis. Documents classified as proceedings papers, book chapters or data papers or undefined types of documents were excluded.
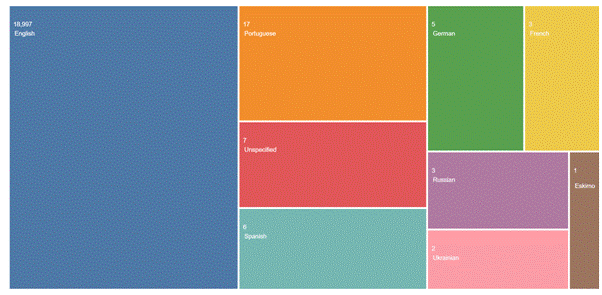
Figure 2 – The number of published articles by languages
The WOS Analytics retrieved 99.7% (18,997 out of 19,041) papers in English and only 3 papers in Russian.
1.3. Publishing Countries
The next research direction was to analyze the composition of the papers according to their publishing countries/regions. Figure 3 presents the top 10 countries according to the number of published articles. When we analyzed the total number of papers from the sample database, we identified that 56% of the total papers are published in the top 3 countries with the most published articles on the topic “machine learning”.
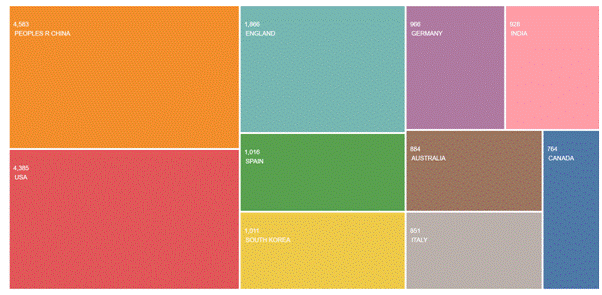
Figure 3 – Top 10 country/Region of publications papers
These countries are the People’s Republic of China (4583 articles), the USA (4385), and England (1866). The Top 10 countries also include Spain, South Korea, Germany, India, Australia, Italy, and Canada.
The country co-citation map was made based on 191 countries found in the 19,041 papers from the sample database. We established a limit of a minimum number of documents of a country 10 documents and a minimum number of citations of a country 20 citations to be included in the results, and a number of 85 countries met the threshold and all 85 were displayed.
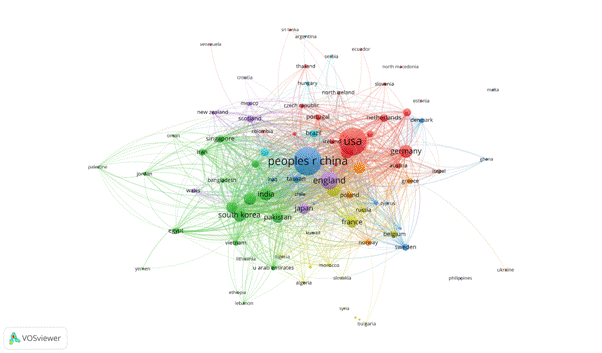
Figure 4 – Country co-citation map
The most cited country is the USA, having 4280 documents with 86765 citations and a total link strength of 9392. The second cited country is People’s Republic China, which has 4466 documents, 51001 citations and a total link strength of 9386. Another country that stands out is England with 1814 documents, 32748 citations and a total link strength of 5989.
Table 3 – Top 10 most cited countries publishing paper on “machine learning”
| Label | Cluster | Links | Totallinkstrength | Documents | Citations |
| usa | Red | ||||
| peoples r china | Blue | ||||
| england | Purple | ||||
| australia | Green | ||||
| canada | Orange | ||||
| germany | Red | ||||
| spain | Yellow | ||||
| italy | Red | ||||
| france | Yellow | ||||
| southkorea | Green |
Other countries with the highest number of citations are Australia (14354), Canada (13721), Germany (13611), Spain (13104), Italy (12837), France (12218) and South Korea (9397).
1.4. Research areas of Published Articles
The WOS classified each paper for one or several research areas, so besides we applied the filter for Research Areas as Computer Science we see that papers could also belong to Engineering (8710) and/or Telecommunications, Medical Informatics, and Mathematics.
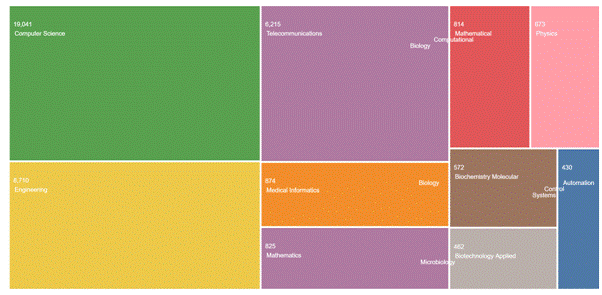
Figure 5 – Top 10 Research areas of the sample database.
1.5. Journals Analysis andFunding agencies
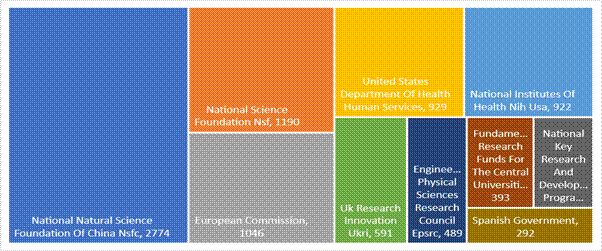
Figure 6 – The top 10 Funding agencies for the topic “machine learning”.
The topic “machine learning” is actively supported and funded by international agencies and scientific funds. While we see the People’s Republic of China published a total of 4583 papers and 2774 articles (60.5% out of 4583) were supported by the National Natural Science Foundation Of China (Nsfc). The second place belongs to the National Science Foundation (Nsf) based in the USA with 1190 articles where Nsf funded 45% out of 4385 articles published in the USA. In third place is the European Commission with 1046 articles. We see that number of published articles highly correlates with fundings of research activities and publications. Many agencies widely support authors and the positive dynamic in publications depends on them.
Bibliographic coupling occurs when two journals reference a common third journal in their bibliographies. It is an indication that a probability exists that the two journals treat a related subject matter. Two journals are bibliographically coupled if they both cite one or more documents in common.

Figure 7 – The bibliographic coupling of sources network
The generation of the bibliographic coupling map by sources was made based on 648 sources found in the 19,041 papers from the sample database. The network consists of 10 clusters. We established a limit of a minimum of 5 documents of the sources to be included in the results, and a number of 428 sources met the threshold. We could highlight 3 journals that stand out. The first from the top 3 is the IEEE Access which concludes with 5076 documents. The IEEE Access is a multidisciplinary, all-electronic archival journal, continuously presenting the results of original research or development across all IEEE’s fields of interest. We don’t observe the high score of average citations (7.3) with the weight of 427 links, high total link strength weight of 3,937,923, and high citation weight of 37,064. The second journal is Electronics an international, peer-reviewed, open-access journal on the science of electronics and its applications published semimonthly online by MDPI. The Electronics journal has a links weight of 426, a total link strength weight of 413,172, and a document weight of 529 but with the most recent score of average publication year 2020.34. The third-place belongs to Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Figure 7 demonstrates that the red cluster merged journals related to “machine learning” which is our area of interest.
Table 4 –Top 3 journals
| Label | Links | Totallinkstrength | Documents | Citations | Avg. pub. year | Avg. citations |
| ieeeaccess | 2019.8383 | 7.3018 | ||||
| electronics | 2020.3478 | 3.3308 | ||||
| bioinformatics | 2017.2734 | 25.5875 |
1.6. Influential Authors in the topic “machine learning”
The next direction is to find the most prominent papers in our sample database, we performed a citation analysis. The principle of the analysis is that the higher the number of citations for a paper, the higher is its influence in the research field. In Table 5 we presented the top 10 papers according to their number of citations. The number of citations is received from the interrogation of the WoS database. This reflects citations to source items indexed within the Web of Science Core Collection.
Table 5 – Top 10 most cited papers.
| R | ArticleTitle | Authors | Year | TC |
| Focal Loss for Dense Object Detection | Lin, TY; Goyal, P; Girshick, R; He, KM; Dollar, P | |||
| Selective Search for Object Recognition | Uijlings, JRR; van de Sande, KEA; Gevers, T; Smeulders, AWM | |||
| Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning | Shin, HC; Roth, HR; Gao, MC; Lu, L; Xu, ZY; Nogues, I; Yao, JH; Mollura, D; Summers, RM | |||
| LSTM: A Search Space Odyssey | Greff, K; Srivastava, RK; Koutnik, J; Steunebrink, BR; Schmidhuber, J | |||
| Brain tumor segmentation with Deep Neural Networks | Havaei, M; Davy, A; Warde-Farley, D; Biard, A; Courville, A; Bengio, Y; Pal, C; Jodoin, PM; Larochelle, H | |||
| Real-Time Human Pose Recognition in Parts from Single Depth Images | Shotton, J; Sharp, T; Kipman, A; Fitzgibbon, A; Finocchio, M; Blake, A; Cook, M; Moore, R | |||
| Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations | Raissi, M; Perdikaris, P; Karniadakis, GE | |||
| Places: A 10 Million Image Database for Scene Recognition | Zhou, BL; Lapedriza, A; Khosla, A; Oliva, A; Torralba, A | |||
| NetVLAD: CNN Architecture for Weakly Supervised Place Recognition | Arandjelovic, R; Gronat, P; Torii, A; Pajdla, T; Sivic, J | |||
| A Comprehensive Survey on Graph Neural Networks | Wu, ZH; Pan, SR; Chen, FW; Long, GD; Zhang, CQ; Yu, PS |
Abbreviations: R—rank; TC—total citations.
The data from Table 5 indicates that three papers demonstrated the highest number of total citations. The paper “Focal Loss for Dense Object Detection”, written by Lin, TY; Goyal, P; Girshick, R; He, KM; Dollar, P [https://openaccess.thecvf.com/content_ICCV_2017/papers/Lin_Focal_Loss_for_ICCV_2017_paper.pdf], is the most cited article in the WOS Category Computer Science and published in IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE Journal. The paper was published in 2020 and it has 3435 citations in the ISI Web of Science Core database. The authors of this paper argue that Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. Results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors.
The second most cited paper is “Selective Search for Object Recognition”, published in INTERNATIONAL JOURNAL OF COMPUTER VISION in 2013, written by Uijlings, JRR; van de Sande, KEA; Gevers, T; Smeulders, AWM [https://www.huppelen.nl/publications/selectiveSearchDraft.pdf], with 2732 citations on ISI Web on Category Computer Science. The paper addresses the problem of generating possible object locations for use in object recognition.
The third most cited paper is “Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning”, published in IEEE TRANSACTIONS ON MEDICAL IMAGING in 2016, written by Shin, HC; Roth, HR; Gao, MC; Lu, L; Xu, ZY; Nogues, I; Yao, JH; Mollura, D; Summers, RM [https://www.researchgate.net/publication/292996483_Deep_Convolutional_Neural_Networks_for_Computer-Aided_Detection_CNN_Architectures_Dataset_Characteristics_and_Transfer_Learning], with 2144 citations on ISI Web on Category Computer Science. The authors examine when and why transfer learning from pre-trained ImageNet (via fine-tuning) can be useful. They study two specific computer-aided detection (CADe) problems, namely thoracoabdominal lymph node (LN) detection and interstitial lung disease (ILD) classification.
One paper stands out, which was published in January 2021, “A Comprehensive Survey on Graph Neural Networks”, written by Wu, ZH; Pan, SR; Chen, FW; Long, GD; Zhang, CQ; Yu, PS [https://www.researchgate.net/publication/330132719_A_Comprehensive_Survey_on_Graph_Neural_Networks] with 691 total citations. The authors provide a comprehensive overview of graph neural networks(GNNs) in data mining and machine learning fields. They propose a new taxonomy to divide the state-of-the-art graph neural networks into four categories, namely recurrent graph neural networks, convolutional graph neural networks, graph autoencoders, and spatial-temporal graph neural networks.
From the author co-citation point of view, in Figure 8 we present the author's co-citation map, based on 60,477 authors, of which 167 authors met the threshold of having a minimum number of documents of on author 10 and a minimum number of citations of an author 20 citations. Figure 8 displays the 154 most frequently co-cited authors in a network map. The author's co-citation analysis groups authors into clusters on a network map based on the similarity of their co-citations.
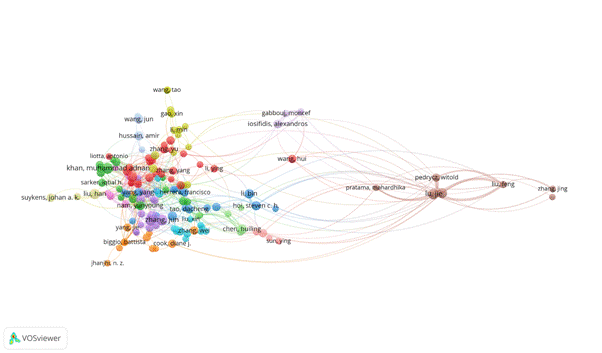
Figure 8 – The authors co-citation map.
In the author's co-citation map 14 clusters were identified.
Table 6 – Top 15 most cited authors
| Label | Cluster | Links | Totallinkstrength | Documents | Citations | Averagepublicationyear |
| yao, xin | LightRed | 2015.5294 | ||||
| tao, dacheng | Blue | 2017.1579 | ||||
| zhang, mengjie | LightRed | 2016.3333 | ||||
| lu, jie | Brown | 2018.4815 | ||||
| cook, diane j. | Orange | 2015.8235 | ||||
| zhang, guangquan | Brown | 2018.2917 | ||||
| herrera, francisco | Blue | 2018.1875 | ||||
| hoi, steven c. h. | Blue | 2015.2381 | ||||
| lu, zhiyong | LightBlue | 2015.8182 | ||||
| baldi, pierre | Red | 2015.9 | ||||
| niyato, dusit | Red | 2019.7143 | ||||
| mueller, klaus-robert | Red | 2018.8182 | ||||
| mirjalili, seyedali | Green | 2019.9412 | ||||
| hussain, amir | LightPurple | 2018.5714 | ||||
| hanzo, lajos | LightBlue | 2019.5455 |
The red cluster is the biggest one, having 27 authors, among which we can identify three highly-cited authors: Ph.D. Pierre Baldi Professor of School of Information and Computer Sciences (ICS) at the University of California, Irvine (UCI), and Associate Director Institute for Genomics and Bioinformatics (IGB); Dusit (Tao) Niyato, Ph.D., IEEE Fellow and Professor of the School of Computer Science and Engineering (SCSE) at Nanyang Technological University; Klaus-Robert Müller is Professor of computer science at Technische Universität Berlin.
We can identify in the light-red cluster, two authors that stands out, Xin Yao is a Chair Professor of Computer Science at the Southern University of Science and Technology, Shenzhen, China, having a total link strength of 33 and 1,598 direct citations. Xin Yao is also co-author of the third top paper (Table 5). The second author is Mengjie Zhang, Professor of Computer Science, Victoria University of Wellington, having a total link strength of 18 and 1,113 direct citations.
The blue cluster, contain 18 authors where three authors entered in the list of top 15 authors. One of the influential author is Dacheng Tao, Professor of Computer Science at the University of Sydney. Dacheng Tao has a total link strength of 5 and 1,167 direct citations. The other authors you could see on table 6.
1.7. The knowledge distribution structure
On the next step we created a keyword co-occurrence analysis map (Figure 10) to identify frequently appeared topics, and also to show relationships between them. By performing the keyword co-occurrence analysis, we can identify which combination of keywords is often used by authors; this can also indicate trends and patterns in the studied topics.
The generation of the keywords co-occurrence map was made based on 47,964 keywords found in the 19,041 papers from the sample database. We established a limit of a minimum of 20 occurrences of the keyword to be included in the results, and a number of 764 of keywords met the threshold and 764 were displayed. For a better overview of the emerging topics, we kept the keyword “machine learning”, as we want to see linkages between key topics. The main aspect visualized in the bibliometric networks visualization of keyword co-occurrence regards the occurrence of the keywords based on the prevalence of their popularity.
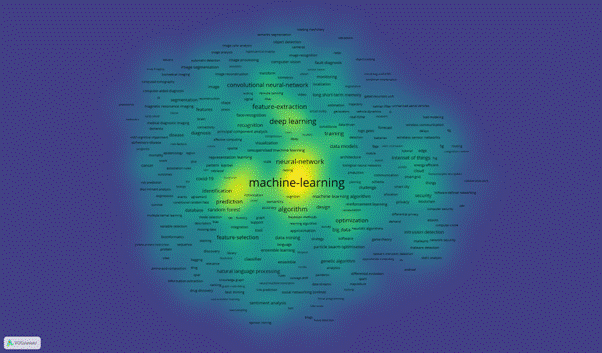
Figure 9 – Density visualization network
Figure 9 shows the density visualization where each point in the item density visualization has a color that indicates the density of items at that point. By default, colors range from blue to green to yellow. The larger the number of items (depth) in the neighborhood of a point and the higher the weights of the neighboring items, the closer the color of the point is to yellow. The other way around, the smaller the number of items in the neighborhood of a point and lower the weights of the neighboring items, the closer the color of the point is to blue. This chart uses kernel smoothing to plot values, allowing for smoother distributions by smoothing out the noise. As we expected, the keyword “machine learning” has the most concentrated yellow color. We could see more topics which have high concentration. We could articulate the semantic linkages between keywords as follows: deep learning, feature extraction, prediction, support vector machine, training, algorithm, data mining, optimization, internet of things.
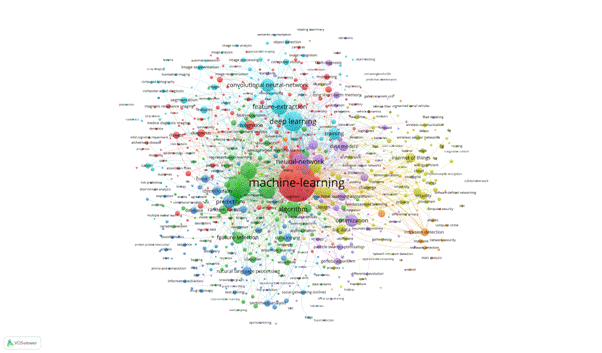
Figure 10 – Network visualization keywords co-occurrence
The VOSviewer generated seven clusters for the keyword occurrence analysis. The size of the clusters varies and demonstrates a big difference between the biggest cluster (155), the red one, and the smallest cluster (45), the orange one.
Table 7 – Top 8 most popular keywords
| Label | Cluster | Links | Totallinkstrength | Occurrences |
| machine-learning | Red | |||
| classification | Green | |||
| deeplearning | Lightblue | |||
| neural-network | Purple | |||
| supportvectormachine | Green | |||
| model | Green | |||
| algorithm | Green | |||
| feature-extraction | LightBlue |
The keyword with thehighest citation count appearing in the network is machine-learning, with 7,588 co-occurrence weight, followed by classification (3,006), deep learning (2,109), neural-network (1,644), support vector machine (1,423), model (1,336), algorithm (1,318), feature-extraction (1,291), system (980), convolutional neural-network (961), prediction (910), optimization (832), regression (797).
1.8. The trending topic in machine learning
The overlay visualization was made based on 47,962 keywords with established a limit of a minimum of 20 occurrences of the keyword to be included in the results, and a number of 762 of keywords met the threshold and 764 were displayed. The overlay network presented below provides the most frequent keywords co-occurrence, where the score of the item is the average time since publication.
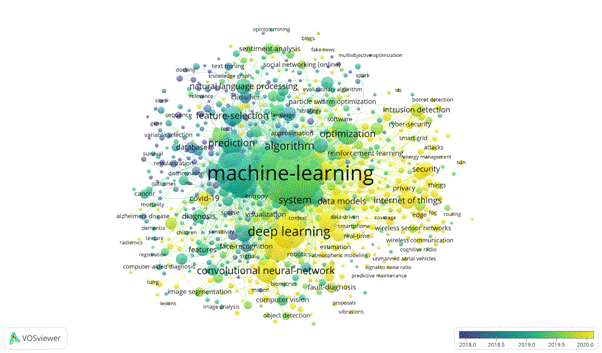
Figure 11 – Overlay visualization co-occurrence keywords network
In the overlay visualization, the color of a keyword indicates the average year in which the publications with this keyword appeared.
Table 8 – Top 8 most recent topics
| Label | Links | Totallinkstrength | Occurrences | Avg. pub. year |
| feature-extraction | 2020.1276 | |||
| predictivemodels | 2020.2495 | |||
| datamodels | 2020.5465 | |||
| internetofthings | 2020.1347 | |||
| machinelearningalgorithm | 2020.1571 | |||
| covid-19 | 2020.8147 | |||
| computationalmodeling | 2020.4308 |
Table 8 shows the most popular topics that were studied in recent times. Feature-extraction refers to the process of transforming raw data into numerical features that can be processed while preserving the information in the original data set. Average publication year is 2020.13 and occurence weight is 1291.
Predictive models are used to predict and forecast likely future outcomes with the aid of historical and existing data. Average publication year is 2020.25 and occurrence weight is 546.
Data models are visual representations of an enterprise's data elements and the connections between them. Average publication year is 2020.55 and occurence weight is 527.
Other important topics are internet of things (523), machine learning algorithm (388), covid-19 (353) and computational modeling (328).
2. Data preprocessing in machine learning
2.1. The knowledge distribution structure for topic “machine learning” and “data preprocessing”
On the next step we created a keyword co-occurrence analysis map (Figure 13) to identify frequently appeared topics, and also to show relationships between them. By performing the keyword co-occurrence analysis, we can identify which combination of keywords is often used by authors; this can also indicate trends and patterns in the studied topics.
The generation of the keywords co-occurrence map was made based on 47,964 keywords found in the 2,056 papers from the sample database. We established a limit of a minimum number of occurrences of a keyword 2 keywords to be included in the results, and a number of 354 keywords met the threshold and 353 were displayed as we excluded the main keyword “machine learning”. The main aspect visualized in the bibliometric networks visualization of keyword co-occurrence regards the occurrence of the keywords based on the prevalence of their popularity.
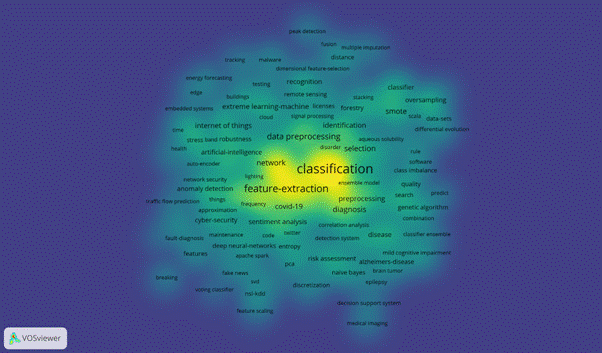
Figure 12 – Densityvisualizationnetwork
Figure 12 shows the density visualization where each point in the item density visualization has a color that indicates the density of items at that point. We could see more topics which have high concentration. We could articulate the semantic linkages between keywords as follows: classification, feature-extraction, support vector machine, training, algorithm, data mining, optimization, internet of things.
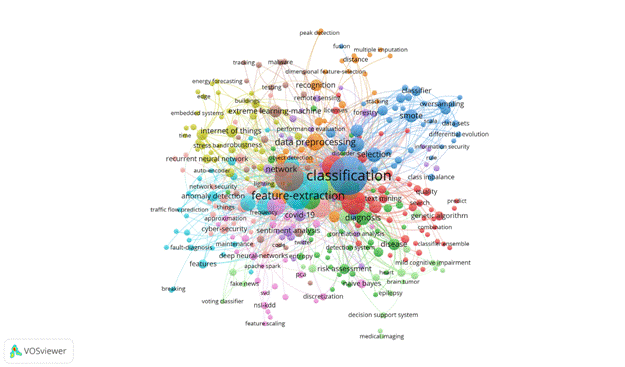
Figure 13 – Network visualization for topic “data preprocessing”
The VOSviewer generated twelve clusters for the keyword occurrence analysis. The size of the clusters varies and demonstrates a big difference between the biggest cluster (44), the red one, and the smallest cluster (2), the light-purple one.
Table 9 – Top 10 keywords for topic “data preprocessing”
| Label | Cluster | Links | Totallinkstrength | Occurrences |
| classification | Blue | |||
| deeplearning | Brown | |||
| feature-extraction | LightBlue | |||
| feature-selection | Red | |||
| supportvectormachine | LightBlue | |||
| algorithm | Red | |||
| convolutionalneural-network | LightGreen | |||
| neural-network | Green | |||
| prediction | LightRed | |||
| model | Green |
The keyword with thehighest citation count appearing in the network is classification with 107 occurrences, followed by deep learning (61), feature-extraction (50), feature-selection (43), support vector machine (37), algorithm (35), convolutional neural-network (32), neural-network (30), prediction (28) and model (26).
2.2. The trending topic in data preprocessing
The overlay network presented below provides the most frequent keywords co-occurrence, where the score of the item is the average time since publication.
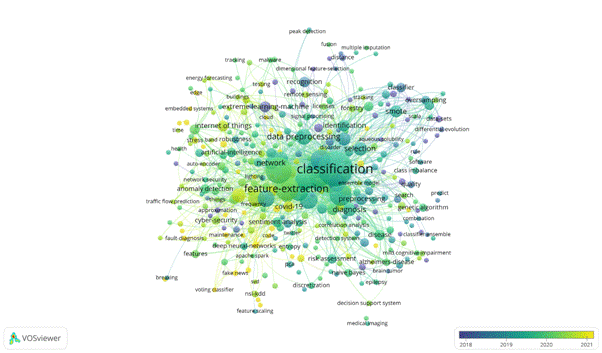
Figure 14 – Overlay visualization co-occurrence keywords network
In the overlay visualization, the color of a keyword indicates the average year in which the publications with this keyword appeared.
Table 10– Top 10 most recent topics for keyword “data preprocessing” for yellow cluster
| Label | Links | Totallinkstrength | Occurrences | Avg. pub. year |
| deeplearning | 2020.0333 | |||
| feature-extraction | 2020.16 | |||
| datamodels | 2020.52 | |||
| predictivemodels | 2020.3333 | |||
| optimization | ||||
| machinelearningalgorithm | 2020.25 | |||
| covid-19 | 2020.7778 | |||
| internetofthings | 2020.6364 | |||
| predictionalgorithms | 2020.1818 | |||
| taskanalysis | 2020.7 |
Table 10 shows recent popular topics that were studied recently. It can be seen that for keyword “data preprocessing” recent topics are almost the same as for keyword “machine-learning”. Except for deep learning, the occurrence weight is 61 and average publication year is 2020.03. And optimization with occurrence weight 19 and average publication year 2020.
Conclusion
The main purpose of the research was to identify common points and future interdisciplinary topics for directions “machine learning” and “data preprocessing”, by empirically documenting the intellectual structure, the volume, and the knowledge-development directions. For fulfilling these purposes we used a bibliometric analysis, and we analyzed 19,041 papers for “machine learning” and 390 papers for “data preprocessing” published in journals indexed in ISI WoS. In this section of the paper, we conclude the obtained results and offer the main limitations and future research directions.
The first research question addressed in this study is related to the identification of the evolution of the volume of published articles. The initial conclusions reveal similarities in the evolution of the number of articles in the case of the machine learning topic. In the last 10 years, from 2012 to 2021, the volume of the published papers increased substantially compared to the previous periods. In the case of machine learning, the number of publications has increased almost 19 times since 2011 from 309 to 5,765 publications in 2021.
This evolution can have different factors, one of them can be proficiency in in English. We see that the globalization of the economy forced organizations to apply more software in English. The sample database retrieved 99.7% (18,997 out of 19,041) papers in English and only 3 papers in Russian.
We analyzed the papers published in different countries, so the countries with most published articles are the People’s Republic of China (4583 articles), the USA (4385), and England (1866). The Top 10 countries also include Spain, South Korea, Germany, India, Australia, Italy, and Canada. The country co-citation map shows 191 countries found in the 19,041 papers from the sample database.
Having this first conclusion, we approach the second research question, in order to identify what are the most influential journals, authors and papers in the two research fields. In order to respond to this question, we performed a bibliometric analysis of the literature. In this case we needed to establish a sample database containing articles from both fields of research. Given the big number of published articles in the last 10 years, the filters used so far were not enough, and we decided to use another filter Open Access. The number of citations was received from the interrogation of the ISI WoS database; this reflects citations to source items indexed within Web of Science Core Collection.
By conducting the bibliometric analysis, we identified that from the journals point of view, the journals with the highest number of published papers is the journal IEEE Access which concludes with 5076 documents.The second journal is Electronics with a links weight of 426, a total link strength weight of 413,172, and a document weight of 529 but with the most recent score of average publication year 2020.34. The third is Bioinformatics journal. We analyzed also the journals from the influential point of view, and we generated a journal co-citation map. The journal citation analysis and document co-citation analysis together clearly demonstrate the multi-disciplinary nature of the articles included in the sample database. It can be also observed that, if we look at the journals with the most published articles in our database, and the most influential journals according to the co-citation map, they are the same.
As a final observation, judging from the journal analysis point of view, the topic “machine learning” is actively supported and funded by international agencies and scientific funds. While we see the People’s Republic of China published a total of 4583 papers and 2774 articles (60.5% out of 4583) were supported by the National Natural Science Foundation Of China (Nsfc). The second place belongs to the National Science Foundation (Nsf) based in the USA with 1190 articles where Nsf funded 45% out of 4385 articles published in the USA. In third place is the European Commission with 1046 articles. We see that number of published articles highly correlates with fundings of research activities and publications.
The intellectual structure, or the most cited works and authors in the studied field of the research, was the next direction that we focused our attention in. An important feature of science mapping is its ability to identify the top articles that have a significant role in the scientific literature. By analyzing their contribution to the research field, we can identify the origin of the field and reveal its theoretical foundation.The paper “Focal Loss for Dense Object Detection” is the most cited article. The paper was published in 2020 and it has 3435 citations in the ISI Web of Science Core database. The second most cited paper is “Selective Search for Object Recognition”, published in 2013. The third is “Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning”, published in 2016. One paper stands out, which was published in January 2021, “A Comprehensive Survey on Graph Neural Networks”, with 691 total citations.
For the most influential authors in the field, an author co-citation map was generated, identifying 14 clusters. The red cluster is the biggest cluster, having 27 authors, among which we can identify three highly-cited authors: Pierre Baldi, Dusit (Tao) Niyato, and Klaus-Robert Müller. We can identify in the light-red cluster, two authors that stand out, Xin Yao and Mengjie Zhang.
It is interesting to observe that the author co-citation map reveals 14 authors that are not present in the top 10 most cited papers. This can be explained by the methodology of generating the co-citation map and the process of selecting the top 10 most cited papers. In case of the most cited papers, the classification is done according to the results offered by the ISI WoS database, which summarizes all the citations to source items indexed within Web of Science Core Collection, while the co-citation map is created by analyzing the articles included in sample database. The condition to be included in the map is a minimum of 20 citations, but in this case the citations are gather from the total articles in our sample database, so it is possible that an article indicated as highly cited by the ISI WoS database is not so cited in our sample database.
The final part of our research addressed the most research topics in the studied field, and for this we performed a keyword co-occurrence analysis and generated a keyword co-occurrence maps for “machine learning” and “data preprocessing”. In order to have a better image of the emerging research topic for “data preprocessing”, we decided to eliminate from the map the most used keyword: machine learning. The first observation is that the size of the clusters is very similar, the difference being one keyword.
From the research topic “machine learning” we could articulate the semantic linkages between keywords as follows: deep learning, feature extraction, prediction, support vector machine, training, algorithm, data mining, optimization, internet of things. The most popular topics that were studied in recent times are feature-extraction, predictive models, data models, internet of things, machine learning algorithm, covid-19 and computational modeling.
The research topic “data preprocessing” demonstrate the semantic linkages between keywords as follows: classification, feature extraction, support vector machine, training, algorithm, data mining, optimization, internet of things.
As a general conclusion, we can say that the fields of machine learning and data preprocessing have a lot of similarities in their semantic linkages, as can be seen from the keyword co-occurrence analysis.
Bibliography
20 научных статей, с 2016 года публикации
1 https://www.vosviewer.com/]
[https://www.vosviewer.com/documentation/Manual_VOSviewer_1.6.8.pdf]
[https://openaccess.thecvf.com/content_ICCV_2017/papers/Lin_Focal_Loss_for_ICCV_2017_paper.pdf]
[https://www.huppelen.nl/publications/selectiveSearchDraft.pdf]
[https://www.researchgate.net/publication/292996483_Deep_Convolutional_Neural_Networks_for_Computer-Aided_Detection_CNN_Architectures_Dataset_Characteristics_and_Transfer_Learning],
[https://www.researchgate.net/publication/330132719_A_Comprehensive_Survey_on_Graph_Neural_Networks]
И все ли из этого мы сделали?
Введение
Актуальность, цели, задачи, планируемые результаты в соответствии с Индивидуальным зданием
Имеющийся задел к началу практики
Выполнение работы
Что было сделано за период практики
Какие методы/подходы/алгоритмы/информационные источники были использованы
Какие результаты получены
Что способствовало / помешало выполнению Индивидуального задания (трудности, которые возникли в результате выполнения задания, какими способами они преодолевались)
Результаты работы могут быть/находятся на этапе/успешно внедрены в рамках …
Выводы
Краткий перечень результатов
Заключение
В ходе практики были полностью/ частично выполнено Индивидуальное задание
Планируемые результаты практики достигнуты полностью/ частично
Список использованных источников
Библиографические ссылки
Ссылки на Интернет-ресурсы
Иные источники (указать при необходимости)
Appendix
Appendix 1. The most recent topics for 2021
| Label | Links | Totallinkstrength | Occurrences | Avg. pub. year |
| analyticalmodels | ||||
| benchmarktesting | ||||
| database | ||||
| monitoring | ||||
| fault-diagnosis | 2021.3333 | |||
| dataaugmentation | ||||
| fakenews | ||||
| image | ||||
| maintenance | ||||
| opinionmining | ||||
| wearablesensors | ||||
| autismspectrumdisorder | ||||
| channelestimation | ||||
| cloud | ||||
| code | ||||
| detection | ||||
| edge | ||||
| embeddedsystems | ||||
| featureengineering | ||||
| imageregistration | ||||
| lighting | ||||
| management | ||||
| multiobjectivefeature-selection | ||||
| network intrusion detection system (nids) | ||||
| objectdetection | ||||
| physicallayer | ||||
| robotics | ||||
| scadasystems | ||||
| scheme | ||||
| vibrations | ||||
| votingclassifier | ||||
| wi-fi | ||||
| xgboost |