Аннотация
В представленной курсовой работе рассматриваются проблемы и подходы к проектированию многомерных баз данных. В работе освещена технология многомерного анализа данных OLAP, рассматриваются концепции хранилищ данных, требования к многомерным базам данных и OLAP-средствам, логическую организацию OLAP-данных, применение OLAP технологий, а также основные термины и понятия, применяемые при обсуждении многомерного анализа.
Содержание
| стр. | |
| Аннотация | 2 |
| Содержание | 3 |
| Введение | 4 |
| 1. Постановка задачи | 5 |
| 2. Краткие сведения | 6 |
| 3. Основы концепции OLAP | 8 |
| 4. Проектирование многомерных баз данных | 20 |
| 5. Пример создания многомерной базы данных с помощью Microsoft Analysis Services | 33 |
| 6. OLAP клиенты | 47 |
| 7. Применение OLAP технологий | 57 |
| Заключение | 60 |
| Литература | 61 |
Введение
На сегодняшний день многие организации пришли к пониманию того факта, что наличие своевременной и объективной информации о рынке, прогнозе его перспектив, оценки деятельности фирмы и взаимоотношений с партнерами, является ключевым фактором в конкурентной борьбе. Исходя из этого, все больше и больше внимания уделяется средствам реализации и построения систем аналитической обработки информации. В первую очередь это касается систем управления многомерными базами данных, которые рассмотрены в данной работе.
Постановка задачи
Исследование технологии OLAP, её возможностей и применения многомерных хранилищ данных. Рассматриваются основные подходы к проектированию и созданию хранилищ данных с помощью Oracle Express. В качестве практической части рассматривается создания OLAP-куба средствами Microsoft Analysis Services. Также рассмотрены возможности Microsoft Excel, как OLAP клиента.
Краткие сведения
В отличие от традиционных реляционных СУБД, концепция OLAP не так широко известна. OLAP - это не отдельно взятый программный продукт, не язык программирования и даже не конкретная технология. Если постараться охватить OLAP во всех его проявлениях, то это совокупность концепций, принципов и требований, лежащих в основе программных продуктов, облегчающих аналитикам доступ к данным. Термин "OLAP" неразрывно связан с термином "хранилище данных" (Data Warehouse). Назначение хранилищ данных - предоставление пользователям информации для статистического анализа и принятия управленческих решений.
Приведем определение, сформулированное основателем концепции хранилищ данных Биллом Инмоном: "Хранилище данных - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений". Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных, описывал хранилище данных как "место, где люди могут получить доступ к своим данным. Он же сформулировал и основные требования к хранилищам данных:
· поддержка высокой скорости получения данных из хранилища;
· поддержка внутренней непротиворечивости данных;
· возможность получения и сравнения так называемых срезов данных (slice and dice);
· наличие удобных утилит просмотра данных в хранилище;
· полнота и достоверность хранимых данных;
· поддержка качественного процесса пополнения данных.
Удовлетворять всем перечисленным требованиям в рамках одного и того же продукта зачастую не удается. Поэтому для реализации хранилищ данных обычно используется несколько продуктов, одни их которых представляют собой собственно средства хранения данных, другие — средства их извлечения и просмотра, третьи — средства их пополнения и т.д. Хранилища данных должны обеспечивать высокую скорость получения данных, возможность получения и сравнения так называемых срезов данных, а также непротиворечивость, полноту и достоверность данных.
Типичное хранилище данных, как правило, отличается от обычной реляционной базы данных. Во-первых, обычные базы данных предназначены для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены для принятия решений. Например, продажа товара и выписка счета производятся с использованием базы данных, предназначенной для обработки транзакций, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, — с помощью хранилища данных. Во-вторых, обычные базы данных подвержены постоянным изменениям в процессе работы пользователей, а хранилище данных относительно стабильно: данные в нем обычно обновляются согласно расписанию (например, еженедельно, ежедневно или ежечасно — в зависимости от потребностей).
В идеале процесс пополнения представляет собой просто добавление новых данных за определенный период времени без изменения прежней информации, уже находящейся в хранилище. И, в-третьих, обычные базы данных чаще всего являются источником данных, попадающих в хранилище. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Системы поддержки принятия решений обычно обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции образуют многомерный (и, следовательно, нереляционный) набор данных (нередко называемый гиперкубом или метакубом), оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные - причем храниться такие данные могут и в реляционных таблицах, но в данном случае мы говорим о логической организации данных, а не о физической реализации их хранения). Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing). OLAP — это ключевой компонент организации хранилищ данных. Эта технология основана на построении многомерных наборов данных — OLAP-кубов, оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные. Концепция OLAP была описана в 1993 году Эдгаром Коддом, известным исследователем баз данных и автором реляционной модели данных.
В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information — быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
· предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
· возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
· многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
· многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это — ключевое требование OLAP);
· возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
Следует отметить, что OLAP-функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах. Приложения с OLAP-функциональностью должны предоставлять пользователю результаты анализа за приемлемое время, осуществлять логический и статистический анализ, поддерживать многопользовательский доступ к данным, осуществлять многомерное концептуальное представление данных и иметь возможность обращаться к любой нужной информации.
Основы концепции OLAP
Рассмотрим подробнее концепцию OLAP и многомерных кубов. В качестве примера реляционной базы данных, который мы будем использовать для иллюстрации принципов OLAP, воспользуемся базой данных Northwind, входящей в комплекты поставки Microsoft Access и представляющей собой типичную базу данных, хранящую сведения о торговых операциях компании, занимающейся оптовыми поставками продовольствия. К таким данным относятся сведения о поставщиках, клиентах, компаниях, осуществляющих доставку, список поставляемых товаров и их категорий, данные о заказах и заказанных товарах, список сотрудников компании. Подробное описание базы данных Northwind можно найти в справочных системах Microsoft SQL Server или Microsoft Access — здесь за недостатком места мы его не приводим.
Для рассмотрения концепции OLAP воспользуемся представлением Invoices и таблицами Products и Categories из базы данных Northwind, создав запрос, в результате которого получим подробные сведения о всех заказанных товарах и выписанных счетах:
SELECT dbo.Invoices.Country,
dbo.Invoices.City,
dbo.Invoices.CustomerName,
dbo.Invoices.Salesperson,
dbo.Invoices.OrderDate,
dbo.Categories.CategoryName,
dbo.Invoices.ProductName,
dbo.Invoices.ShipperName,
dbo.Invoices.ExtendedPrice
FROM dbo.Products INNER JOIN
dbo.Categories ON dbo.Products.CategoryID = dbo.Categories.CategoryID INNER JOIN
dbo.Invoices ON dbo.Products.ProductID = dbo.Invoices.ProductID
В Access 2000 аналогичный запрос имеет вид:
SELECT Invoices.Country, Invoices.City,
Invoices.Customers.CompanyName AS
CustomerName, Invoices.Salesperson,
Invoices.OrderDate, Categories.CategoryName,
Invoices.ProductName,
Invoices.Shippers.CompanyName AS
ShipperName, Invoices.ExtendedPrice
FROM Categories INNER JOIN (Invoices INNER
JOIN Products ON Invoices.ProductID =
Products.ProductID) ON Categories.CategoryID =
Products.CategoryID;
Этот запрос обращается к представлению Invoices, содержащему сведения обо всех выписанных счетах, а также к таблицам Categories и Products, содержащим сведения о категориях продуктов, которые заказывались, и о самих продуктах соответственно. В результате этого запроса мы получим набор данных о заказах, включающий категорию и наименование заказанного товара, дату размещения заказа, имя сотрудника, выписавшего счет, город, страну и название компании-заказчика, а также наименование компании, отвечающей за доставку. Для удобства сохраним этот запрос в виде представления, назвав его Invoices1.

Рис. 3.1. Результат обращения к представлению Invoices1
Какие агрегатные данные мы можем получить на основе этого представления? Обычно это ответы на вопросы типа:
· Какова суммарная стоимость заказов, сделанных клиентами из Франции?
· Какова суммарная стоимость заказов, сделанных клиентами из Франции и доставленных компанией Speedy Express?
· Какова суммарная стоимость заказов, сделанных клиентами из Франции в 1997 году и доставленных компанией Speedy Express?
Переведем эти вопросы в запросы на языке SQL.
| Вопрос | SQL-запрос |
| Какова суммарная стоимость заказов, сделанных клиентами из Франции? | SELECT SUM (ExtendedPrice) FROM invoices1 WHERE Country=’France’ |
| Какова суммарная стоимость заказов, сделанных клиентами из Франции и доставленных компанией Speedy Express? | SELECT SUM (ExtendedPrice) FROM invoices1 WHERE Country=’France’ AND ShipperName=’Speedy Express’ |
| Какова суммарная стоимость заказов, сделанных клиентами из Франции в 1996 году и доставленных компанией Speedy Express? | SELECT SUM (ExtendedPrice) FROM Ord_pmt WHERE CompanyName=’Speedy Express’ AND OrderDate BETWEEN ‘December 31, 1995’ AND ‘April 1, 1996’ AND ShipperName=’Speedy Express’ |
Результатом любого из перечисленных выше запросов является число. Если в первом из запросов заменить параметр ‘France’ на ‘Austria’ или на название иной страны, можно снова выполнить этот запрос и получить другое число. Выполнив эту процедуру со всеми странами, мы получим следующий набор данных (ниже показан фрагмент):
| Country | SUM (ExtendedPrice) |
| Argentina | 7327.3 |
| Austria | 110788.4 |
| Belgium | 28491.65 |
| Brazil | 97407.74 |
| Canada | 46190.1 |
| France | 69185.48 |
| Germany | 209373.6 |
| … | … |
Полученный набор агрегатных значений (в данном случае — сумм) может быть интерпретирован как одномерный набор данных. Этот же набор данных можно получить и в результате запроса с предложением GROUP BY следующего вида:
SELECT Country, SUM (ExtendedPrice) FROM invoices1
GROUP BY Country
Теперь обратимся ко второму из приведенных выше запросов, который содержит два условия в предложении WHERE. Если выполнять этот запрос, подставляя в него все возможные значения параметров Country и ShipperName, мы получим двухмерный набор данных следующего вида (ниже показан фрагмент):
| ShipperName | |||
| Country | Federal Shipping | Speedy Express | United Package |
| Argentina | 1 210.30 | 1 816.20 | 5 092.60 |
| Austria | 40 870.77 | 41 004.13 | 46 128.93 |
| Belgium | 11 393.30 | 4 717.56 | 17 713.99 |
| Brazil | 16 514.56 | 35 398.14 | 55 013.08 |
| Canada | 19 598.78 | 5 440.42 | 25 157.08 |
| Denmark | 18 295.30 | 6 573.97 | 7 791.74 |
| Finland | 4 889.84 | 5 966.21 | 7 954.00 |
| France | 28 737.23 | 21 140.18 | 31 480.90 |
| Germany | 53 474.88 | 94 847.12 | 81 962.58 |
| … | … | … | … |
Такой набор данных называется сводной таблицей (pivot table) или кросс-таблицей (cross table, crosstab). Создавать подобные таблицы позволяют многие электронные таблицы и настольные СУБД — от Paradox для DOS до Microsoft Excel 2000. Вот так, например, выглядит подобный запрос в Microsoft Access 2000:
TRANSFORM Sum(Invoices1.ExtendedPrice) AS SumOfExtendedPrice
SELECT Invoices1.Country
FROM Invoices1
GROUP BY Invoices1.Country
PIVOT Invoices1.ShipperName;
Агрегатные данные для подобной сводной таблицы можно получить и с помощью обычного запроса GROUP BY:
SELECT Country,ShipperName, SUM (ExtendedPrice) FROM invoices1
GROUP BY COUNTRY,ShipperName
Отметим, однако, что результатом этого запроса будет не сама сводная таблица, а лишь набор агрегатных данных для ее построения (ниже показан фрагмент):
| Country | ShipperName | SUM (ExtendedPrice) |
| Argentina | Federal Shipping | 845.5 |
| Austria | Federal Shipping | 35696.78 |
| Belgium | Federal Shipping | 8747.3 |
| Brazil | Federal Shipping | 13998.26 |
| … | … | … |
Третий из рассмотренных выше запросов имеет уже три параметра в условии WHERE. Варьируя их, мы получим трехмерный набор данных.
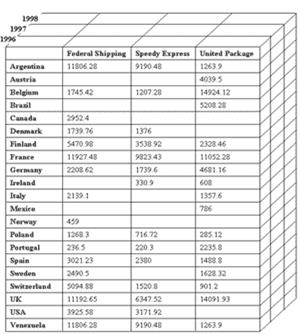
Рис. 3.2. Трехмерный набор агрегатных данных
Ячейки куба, содержат агрегатные данные, соответствующие находящимся на осях куба значениям параметров запроса в предложении WHERE. Можно получить набор двухмерных таблиц с помощью сечения куба плоскостями, параллельными его граням (для их обозначения используют термины cross-sections и slices). Очевидно, что данные, содержащиеся в ячейках куба, можно получить и с помощью соответствующего запроса с предложением GROUP BY. Кроме того, некоторые электронные таблицы (в частности, Microsoft Excel 2000) также позволяют построить трехмерный набор данных и просматривать различные сечения куба, параллельные его грани, изображенной на листе рабочей книги (workbook). Если в предложении WHERE содержится четыре или более параметров, результирующий набор значений (также называемый OLAP-кубом) может быть 4-мерным, 5-мерным и т.д. Наряду с суммами в ячейках OLAP-куба могут содержаться результаты выполнения иных агрегатных функций языка SQL, таких как MIN, MAX, AVG, COUNT, а в некоторых случаях — и других (дисперсии, среднеквадратичного отклонения и т.д.). Для описания значений данных в ячейках используется термин summary (в общем случае в одном кубе их может быть несколько), для обозначения исходных данных, на основе которых они вычисляются, — термин measure, а для обозначения параметров запросов — термин dimension (переводимый на русский язык обычно как "измерение", когда речь идет об OLAP-кубах, и как "размерность", когда речь идет о хранилищах данных). Значения, откладываемые на осях, называются членами измерений (members).
Говоря об измерениях, следует упомянуть о том, что значения, наносимые на оси, могут иметь различные уровни детализации. Например, нас может интересовать суммарная стоимость заказов, сделанных клиентами в разных странах, либо суммарная стоимость заказов, сделанных иногородними клиентами или даже отдельными клиентами. Естественно, результирующий набор агрегатных данных во втором и третьем случаях будет более детальным, чем в первом. Заметим, что возможность получения агрегатных данных с различной степенью детализации соответствует одному из требований, предъявляемых к хранилищам данных, — требованию доступности различных срезов данных для сравнения и анализа.
Поскольку в рассмотренном примере в общем случае в каждой стране может быть несколько городов, а в городе — несколько клиентов, можно говорить об иерархиях значений в измерениях. В этом случае на первом уровне иерархии располагаются страны, на втором — города, а на третьем — клиенты.

Рис. 3.3. Иерархия в измерении, связанном с географическим положением клиентов
Отметим, что иерархии могут быть сбалансированными (balanced), как, например, иерархии, основанные на данных типа "дата—время", и несбалансированными (unbalanced). Типичный пример несбалансированной иерархии — иерархия типа "начальник—подчиненный" (ее можно построить, например, используя значения поля Salesperson исходного набора данных из рассмотренного выше примера):

Рис. 3.4. Несбалансированная иерархия
Иногда для таких иерархий используется термин Parent-child hierarchy. Существуют также иерархии, занимающие промежуточное положение между сбалансированными и несбалансированными (они обозначаются термином ragged — "неровный"). Обычно они содержат такие члены, логические "родители" которых находятся не на непосредственно вышестоящем уровне (например, в географической иерархии есть уровни Country, City и State, но при этом в наборе данных имеются страны, не имеющие штатов или регионов между уровнями Country и City;

Рис. 3.5. "Неровная" иерархия
Отметим, что несбалансированные и "неровные" иерархии поддерживаются далеко не всеми OLAP-средствами. Например, в Microsoft Analysis Services 2000 поддерживаются оба типа иерархии, а в Microsoft OLAP Services 7.0 — только сбалансированные. Различным в разных OLAP-средствах может быть и число уровней иерархии, и максимально допустимое число членов одного уровня, и максимально возможное число самих измерений.
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
· Многомерное представление данных - средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
· Многомерная обработка - средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
· Многомерное хранение - средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД. Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services). Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы. OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных - и в обычном, и в многомерном - наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью - ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой - аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим - в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз. Степень "разбухания" данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества "отцов" и "детей" на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов. Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид - смешанный. Применяются следующие термины:
· MOLAP (Multidimensional OLAP) - и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
· ROLAP (Relational OLAP) - детальные данные остаются там, где они "жили" изначально - в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
· HOLAP (Hybrid OLAP) - детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий - объема данных, мощности реляционной СУБД и т. д. При хранении данных в многомерных структурах возникает потенциальная проблема "разбухания" за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то бо/льшая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Рассмотрим типичную структуру хранилищ данных, поговорим о том, что представляет собой OLAP на клиенте и на сервере, а также обсудим некоторые технические аспекты многомерного хранения данных. Как мы уже знаем, конечной целью использования OLAP является анализ данных и представление результатов этого анализа в виде, удобном для восприятия и принятия решений. Основная идея OLAP заключается в построении многомерных кубов, которые будут доступны для пользовательских запросов. Однако исходные данные для построения OLAP-кубов обычно хранятся в реляционных базах данных. Нередко это специализированные реляционные базы данных, называемые также хранилищами данных (Data Warehouse). В отличие от так называемых оперативных баз данных, с которыми работают приложения, модифицирующие данные, хранилища данных предназначены исключительно для обработки и анализа информации, поэтому проектируются они таким образом, чтобы время выполнения запросов к ним было минимальным. Обычно данные копируются в хранилище из оперативных баз данных согласно определенному расписанию. Типичная структура хранилища данных существенно отличается от структуры обычной реляционной СУБД. Как правило, эта структура денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных. Для дальнейших примеров мы снова воспользуемся базой данных Northwind, входящей в комплекты поставки Microsoft SQL Server и Microsoft Access.

Рис. 3.6. Структура базы данных Northwind
Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables).
Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся:
· факты, связанные с транзакциями (Transaction facts). Они основаны на отдельных событиях (типичными примерами которых являются телефонный звонок или снятие денег со счета с помощью банкомата);
· факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за день или дневная выручка;
· факты, связанные с элементами документа (Line-item facts). Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки);
· факты, связанные с событиями или состоянием объекта (Event or state facts). Представляют возникновение события без подробностей о нем (например, просто факт продажи или факт отсутствия таковой без иных подробностей).
Для примера рассмотрим факты, связанные с элементами документа (в данном случае счета, выставленного за товар). Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно — лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые неключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.


Рис. 3.6. Пример таблицы фактов
В данном примере измерениям будущего куба соответствуют первые шесть полей, а агрегатным данным — последние четыре.
Отметим, что для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные (то есть соответствующие членам нижних уровней иерархии соответствующих измерений). В данном случае предпочтительнее взять за основу факты продажи товаров отдельным заказчикам, а не суммы продаж для разных стран — последние все равно будут вычислены OLAP-средством. Исключение можно сделать, пожалуй, только для клиентских OLAP-средств (о них мы поговорим чуть позже), поскольку в силу ряда ограничений они не могут манипулировать большими объемами данных. Заметим, что в таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных. Например, в ней есть идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой категории относится данный продукт или в каком городе находится данный клиент. Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Нередко (но не всегда) таблица измерений может содержать и поля, указывающие на «прародителей», и иных «предков» в данной иерархии (это обычно характерно для сбалансированных иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов. Отметим, что скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее.


Рис. 3.7. Пример таблицы измерений
Одно измерение куба может содержаться как в одной таблице (в том числе и при наличии нескольких уровней иерархии), так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении. Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда» (star schema).

Рис. 3.8. Пример схемы «звезда»
Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка» (snowflake schema). Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами (outrigger table).
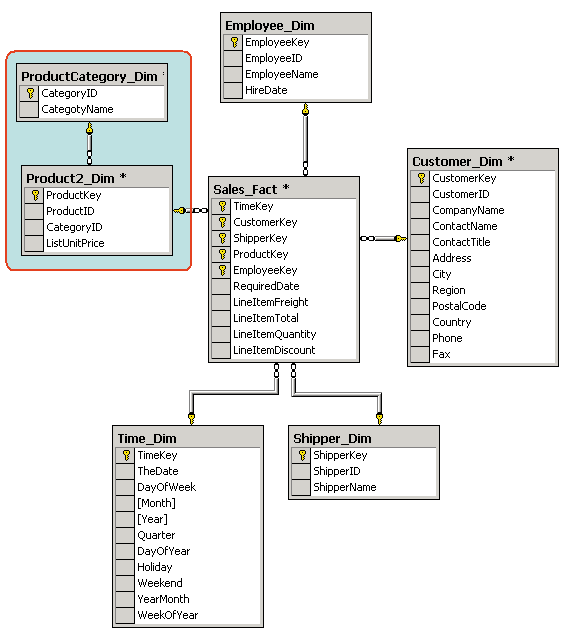
Рис. 3.9. Пример схемы «снежинка»
Отметим, что даже при наличии иерархических измерений с целью повышения скорости выполнения запросов к хранилищу данных нередко предпочтение отдается схеме «звезда». Однако не все хранилища данных проектируются по двум приведенным выше схемам. Так, довольно часто вместо ключевого поля для измерения, содержащего данные типа «дата», и соответствующей таблицы измерений сама таблица фактов может содержать ключевое поле типа «дата». В этом случае соответствующая таблица измерений просто отсутствует. В случае несбалансированной иерархии (например, такой, которая может быть основана на таблице Employees базы данных Northwind, имеющей поле EmployeeID, которое одновременно является и первичным, и внешним ключом и отражает подчиненность одних сотрудников другим в схему «снежинка» также следует вносить коррективы. В этом случае обычно в таблице измерений присутствует связь, аналогичная соответствующей связи в оперативной базе данных.
Еще один пример отступления от правил — наличие нескольких разных иерархий для одного и того же измерения. Типичные примеры таких иерархий — иерархии для календарного и финансового года (при условии, что финансовый год начинается не с 1 января), или с различными способами группировки членов измерения (например, группировать товары можно по категориям, а можно и по компаниям-поставщикам). В этом случае таблица измерений содержит поля для всех возможных иерархий с одними и теми же членами нижнего уровня, но с разными членами верхних уровней. Как мы уже отмечали выше, таблица измерений может содержать поля, не имеющие отношения к иерархиям и представляющие собой просто дополнительные атрибуты членов измерений (member properties). Иногда такие атрибуты могут быть использованы при анализе данных.Следует сказать, что для создания реляционных хранилищ данных нередко применяются специализированные СУБД, хранение данных в которых оптимизировано с точки зрения скорости выполнения запросов. Примером такого продукта является Sybase Adaptive Server IQ, реализующий нетрадиционный способ хранения данных в таблицах (не по строкам, а по столбцам). Однако создавать хранилища можно и в обычных реляционных СУБД. Итак, обсудив типичную структуру хранилища данных, на основе которых обычно строятся OLAP-кубы, вернемся к созданию OLAP-кубов и поговорим о том, какими бывают OLAP-инструменты. Многомерный анализ данных может быть произведен с помощью различных средств, которые условно можно разделить на клиентские и серверные OLAP-средства. Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в кэше внутри адресного пространства такого OLAP-средства. Если исходные данные содержатся в настольной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если же источник исходных данных — серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL-запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере. Как правило, OLAP-функциональность реализована в средствах статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний StatSoft и SPSS) и в некоторых электронных таблицах. В частности, неплохими средствами многомерного анализа обладает Microsoft Excel 2000. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух- или трехмерные сечения.
Многие средства разработки содержат библиотеки классов или компонентов, позволяющие создавать приложения, реализующие простейшую OLAP-функциональность (такие, например, как компоненты DecisionCube в Borland Delphi и Borland C++Builder). Помимо этого многие компании предлагают элементы управления ActiveX и другие библиотеки, реализующие подобную функциональность. Отметим, что клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров, — ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские