Рассмотрим создание многомерного OLAP-куба на основании хранилища данных Northwind_Mart, которое мы создали и заполнили в третьей главе. Напомним, что это хранилище содержит таблицу фактов Sales_Fact и таблицы измерений Employee_Dim, Customer_Dim, Product_Dim, Time_Dim, Shipper_Dim. Отметим, что в процессе создания куба нам придется несколько модифицировать наше хранилище данных, с тем чтобы оно позволяло производить некоторые специальные виды анализа данных. Для выполнения этого примера следует установить аналитические службы Microsoft SQL Server и запустить утилиту Analysis Manager, с помощью которой обычно и создаются многомерные базы данных.
Прежде чем создавать OLAP-кубы, необходимо описать источники исходных данных для них. В нашем примере таким источником является созданное ранее хранилище Northwind_Mart.
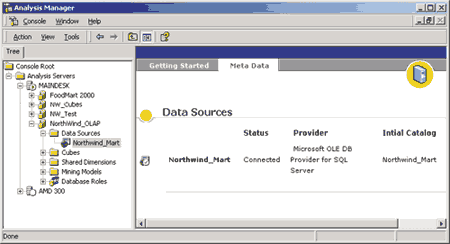
Рис. 5.1. Создание источника данных
Как мы уже знаем, у OLAP-куба должно быть как минимум одно измерение. В Microsoft SQL Server Analysis Services измерения делятся на коллективные (shared dimensions) и частные (private dimensions).
Коллективные измерения — это измерения, которые могут быть использованы одновременно в нескольких кубах. Их применение удобно в том случае, когда измерение основано на стандартных данных, применимых при анализе различных предметных областей. Типичным примером создания таких измерений может быть, например, список сотрудников компании. Коллективные измерения принадлежат самой многомерной базе данных и не зависят от того, какие кубы имеются в многомерной базе данных и есть ли они там вообще. Частные измерения принадлежат конкретному кубу и создаются вместе с ним. Они применяются в том случае, когда данное измерение имеет смысл только в одной конкретной предметной области. Создать как коллективное, так и частное измерение можно двумя способами: с помощью соответствующего мастера и с помощью редактора измерений.
В качестве примера создадим коллективное измерение, основанное на таблице хранилища данных Time_Dim, воспользовавшись мастером создания измерений (Dimension wizard). Запустить его можно с помощью команды New Dimension | Wizard из контекстного меню элемента Shared Dimensions. Затем необходимо ответить на вопросы мастера создания измерений. В первую очередь следует выбрать, на основании чего мы создаем измерение. Поскольку исходное хранилище данных основано на схеме «звезда», выберем в мастере создания измерений опцию Star Schema: a single dimension table, а затем — имя таблицы, служащей источником данных для создаваемого измерения:
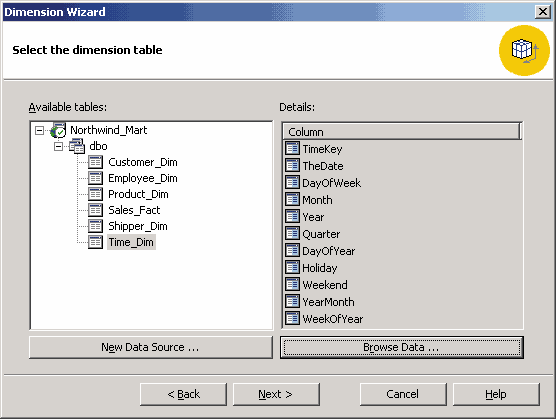
Рис. 5.2. Выбор таблицы для создания измерения
Иерархия данных в измерениях, основанных на данных типа «дата/время», подчиняется определенным стандартным правилам — ведь время измеряется в годах, месяцах, днях, часах, минутах независимо от того, какую предметную область мы анализируем. Поэтому измерения в OLAP-средствах обычно делятся на стандартные (не имеющие отношения ко времени) и временные. Поскольку наше измерение относится к последним, в диалоговой панели Select the dimension type выберем опцию Time Dimension и в качестве колонки, в которой содержатся данные типа «дата/время», укажем поле TheDate.
Теперь нам необходимо выбрать уровни иерархии измерений (например, решить, интересна ли нам информация о часах и минутах, нужны ли нам номера недель года и т.д.), а также определить, когда начинается год с точки зрения данного измерения. Это довольно важная возможность — ведь во многих странах начало финансового года не совпадает с началом года календарного. В нашем случае выберем уровни Year, Quarter, Month, Day и согласимся с тем, что год начинается 1 января.

Рис. 5.3. Создание измерения типа «дата/время»
Далее нам предстоит выбрать, является ли измерение изменяющимся (changing dimension). В изменяющихся измерениях (новинка в SQL Server 2000) можно перемещать члены измерений между уровнями без перерасчета данных измерения, что во многих случаях бывает удобно. Однако измерения типа Time, как правило, не делают изменяющимися — обычно никто не перемещает месяцы из одного года в другой. Поэтому в данном случае мы не будем выбирать эту опцию. В заключительной диалоговой панели мы должны ввести имя будущего измерения и, если есть необходимость, создать иерархию в измерении и задать ее имя. Дело в том, что при необходимости можно создать еще одно измерение, основанное на тех же данных, с тем же именем, но с другой иерархией, например Year, Week, Day; в этом случае мы имеем разное представление одних и тех же данных. Присвоим созданной иерархии имя YQMD.
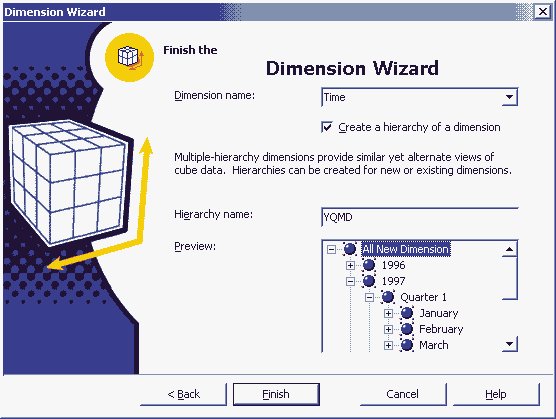
Рис. 5.4. Создание источника данных
Создание измерения заканчивается запуском редактора измерений — Dimension Editor. В нем при необходимости можно внести изменения в структуру измерения, например добавив дополнительные уровни или свойства членов измерения. Так, если мы планируем анализировать зависимость продаж от дня недели или сравнивать продажи в выходные, праздничные и будние дни, можно перенести в раздел Member Properties уровня Day поля Day of Week, Holiday и Weekend исходной таблицы Time_Dim.
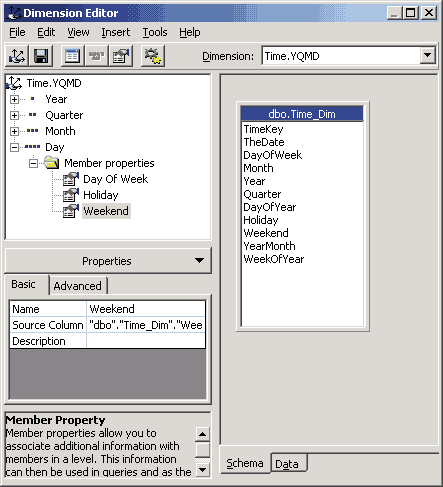
Рис. 5.5. Dimension Editor
Теперь можно сохранить созданное измерение, выбрав пункт меню File | Save, и закрыть редактор измерений. Повторим все указанные действия, выбрав при этом другую иерархию — Year, Week, Day, и назовем вновь созданное измерение Time.YWD.
Следующее коллективное измерение создадим с помощью редактора измерений. Запустить его можно с помощью команды New Dimension | Editor из контекстного меню элемента Shared Dimensions. Далее в диалоговой панели Select the dimension table выберем таблицу Product_Dim. В редакторе измерений создадим два уровня иерархии этого измерения — CategoryName и ProductName — и перенесем мышью соответствующие имена полей в левую часть редактора измерений. В качестве свойств членов измерения уровня ProductName выберем поля SupplierName и ListUnitPrice. Поскольку переносить продукты из одной категории в другую представляется более разумным, чем переносить месяцы из одного года в другой, сделаем это измерение изменяющимся — соответствующее свойство доступно на вкладке Advanced панели Properties в левой нижней части редактора измерений. Сохраним созданное измерение под именем Product.

Рис. 5.6. Создание регулярного измерения в Dimension Editor
Следующее измерение будет содержать географические сведения. Такие измерения являются типичными кандидатами для создания так называемых неровных (ragged) иерархий — частного случая несбалансированных (unbalanced) иерархий. Как известно, административно-территориальное деление в разных странах осуществляется по разным правилам: в некоторых странах есть регионы, штаты, административные округа, а в некоторых достаточно указать населенный пункт, и в этом случае сведения о штате или регионе могут отсутствовать.
Чтобы создать измерение с несбалансированной иерархией, добавим в хранилище данных представление, которое будет содержать исходные данные для создания этого измерения:
CREATE VIEW dbo.CustomerView_Dim
AS
SELECT
CustomerKey, CustomerID, CompanyName, ContactName, ContactTitle, Address, City,
Region,
REPLACE(Region, ‘Other’, Country) AS Region1,
PostalCode, Country, Phone, Fax
FROM dbo.Customer_Dim
Это представление содержит данные из таблицы Customer_Dim, а также вычисляемое поле Region1, содержащее название страны вместо строки «Other» в тех случаях, когда сведения о клиенте не содержат данных о регионе или штате. Это поле нам потребуется в дальнейшем для создания несбалансированной иерархии.
Теперь создадим измерение, основанное на вновь созданном представлении CustomerView_Dim хранилища данных. Последовательность действий в этом случае сходна с предыдущим примером. В качестве уровней иерархии этого измерения мы выберем поля Country, Region1, City, CompanyName. Добавим в раздел Member Properties уровня Company Name поля Contact Name и Contact Title.
Несбалансированные иерархии обычно базируются на сокрытии членов измерения, содержащих избыточные сведения. В данном случае таковым является уровень Region1. Выберем его в редакторе измерений и на странице Advanced раздела Properties установим свойство Hide Member If равным Parent’s name. В этом случае все члены уровня Region1, содержащие названия стран, будут скрыты.

Рис. 5.7. Несбалансированная иерархия
Именно для этого мы и создавали представление в хранилище данных — строка «Other», вполне устраивавшая нас при обращении к самому хранилищу данных, будучи именем члена измерения, не может выступать в качестве условия его скрытия.
Следующее измерение, которое мы создадим, будет основано на таблице Employee_Dim хранилища данных. Обычно измерения, содержащие сведения об административной подчиненности сотрудников, содержат еще один тип несбалансированных иерархий — иерархии типа «родитель-потомок» (parent-child). Такие иерархии нередко основаны на таблицах, где первичный ключ является одновременно и внешним ключом. Исходная таблица Employees базы данных Northwind действительно содержит сведения об административной подчиненности сотрудников (и имеет соответствующий внешний ключ), а таблица Employee_Dim — нет. Поэтому в первую очередь модифицируем ее, добавив к ней поле Reports_To:
ALTER TABLE dbo.Employee_Dim ADD Reports_To int
Затем с помощью DTS добавим в это поле данные из таблицы Employees.
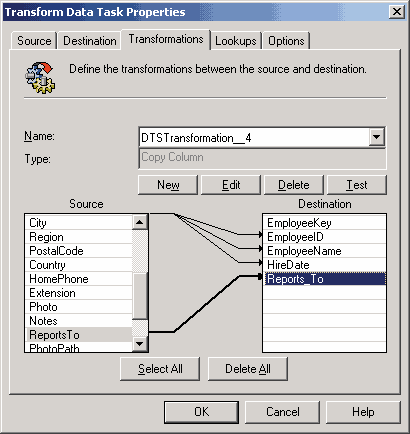
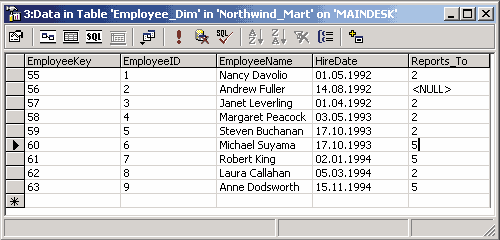
Рис. 5.8. Добавление данных в таблицу Employee_Dim
Теперь можно создать измерение на основе таблицы Employee_Dim с помощью Dimension Wizard. В его первой диалоговой панели выберем опцию Parent-Child: Two related columns in a single dimension table. Далее опишем связь между двумя полями таблицы Employee_Dim, указав имя поля EmployeeID в качестве свойства Member_Key создаваемого измерения, Reports_To — в качестве его свойства Parent_Key, EmployeeName — в качестве его свойства Member Name.

Рис. 5.9. Определение параметров иерархии «родитель-потомок»
В диалоговой панели Select advanced options следует выбрать опцию Members with data, а в панели Set members with data property — опции Nonleaf members have associated data и Data members are visible. Это позволит анализировать как собственные результаты работы сотрудников, имеющих подчиненных, так и результаты работы их подчиненных. Создадим иерархию в этом измерении, назвав ее Employee.PC, и укажем в качестве свойства члена измерения поле Hire Date. В результате мы получим иерархию:
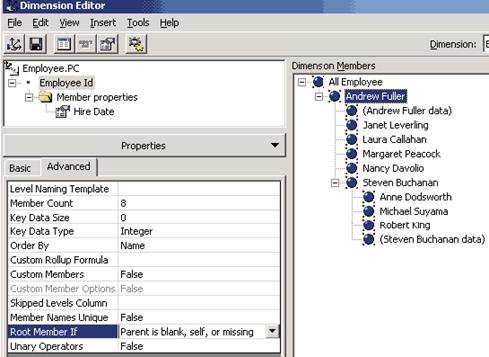
Рис. 5.10. Иерархия «родитель-потомок»
В качестве альтернативы создадим еще одну иерархию — Employee.Regular, содержащую один уровень Employee_Name; в качестве свойств члена этого уровня выберем поля Hire Date и Reports_To.
На этом мы закончим создание коллективных измерений и приступим к созданию куба.
Как и измерение, куб можно создать с помощью соответствующего мастера или непосредственно в редакторе кубов. В качестве примера создадим куб, основанный на нашем хранилище данных Northwind_Mart и использующий созданные выше измерения. Запустить мастер создания кубов можно командой New Cube | Wizard из контекстного меню элемента Cubes. Первое, что следует сделать после запуска мастера, — выбрать таблицу фактов для будущего куба. В нашем случае это таблица Sales_Fact. Далее из таблицы фактов следует выбрать одно или несколько полей, на основе которых вычисляются меры куба (то есть поля, данные которых подлежат суммированию либо обработке с помощью других агрегатных функций). Выберем поля Line Item Total, Line Item Quantity и Line Item Discount.
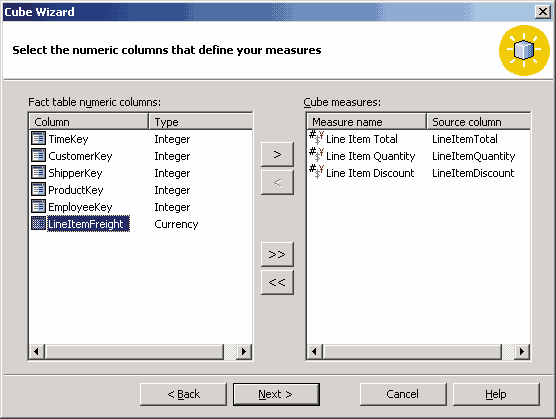
Рис. 5.11. Выбор мер куба
Следующим шагом будет выбор коллективных измерений, используемых в этом кубе, а также создание недостающих частных измерений. Выберем коллективные измерения Employee.PC, Employee.Regular, Time.YQMD, Product и Customer. Кроме того, добавим новое измерение Shipper, нажав кнопку New Dimension в диалоговой панели выбора измерений. Это приведет к запуску уже знакомого нам мастера создания измерений; в последней из диалоговых панелей мастера в этом случае мы можем выбрать, каким будет создаваемое измерение — частным или коллективным.
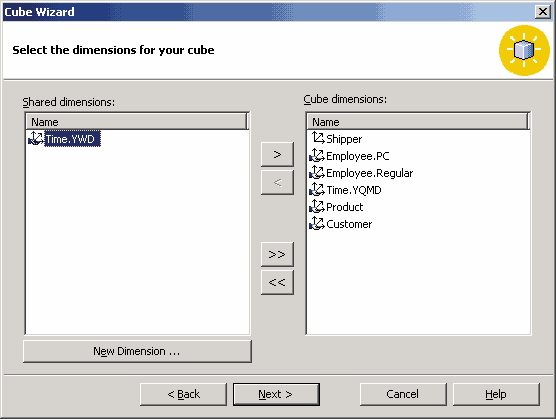
Рис. 5.12. Выбор мер куба
Таким образом, мы определили метаданные куба. По окончании работы мастера будет запущен редактор кубов, в котором при необходимости можно внести исправления в определение куба, например добавить или удалить измерения и меры, создать вычисляемые значения и т.д.
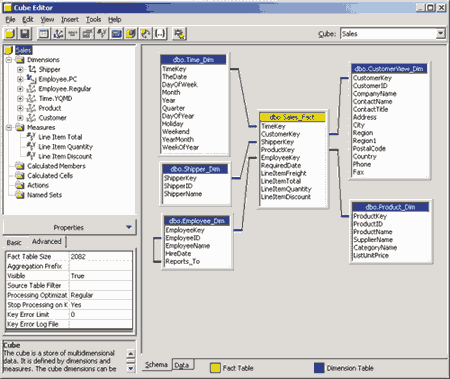
Рис. 5.13. Редактор кубов
Теперь попробуем добавить к нашему кубу вычисляемые значения, то есть значения, которые не хранятся в самом кубе, а вычисляются «на лету». Типичным примером такого значения может быть дополнительная мера, вычисленная на основе уже имеющихся. При вычислениях можно использовать как функции из библиотеки, входящей в состав Analysis Services, так и выражения VBA, а также собственные библиотеки функций (последние следует зарегистрировать в Analysis Services).
Для создания вычисляемых выражений следует выбрать раздел Calculated Members и из контекстного меню выбрать опцию New Сalculated Member. После этого будет запущен построитель выражений (Calculated Member Builder), в котором можно создавать и редактировать выражения, перетаскивая мышью имена измерений и их уровней, мер, имена функций. Например, перенесем в поле для выражения имена мер [Measures].[Line Item Total] и [Measures].[Line Item Discount], поставим между ними знак вычитания, а в качестве значения Member Name ведем Discounted Total.
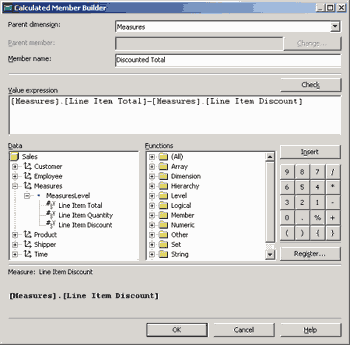
Рис. 5.14. Редактор вычисляемых выражений
В результате мы получили еще одну меру — значение суммы, вырученной за товар, с учетом скидки. Теперь можно сохранить определение куба, выбрав пункт меню File | Save редактора кубов. Процесс создания куба на этом не завершен — мы создали его определение, но не производили никаких вычислений. Прежде чем произвести вычисления, напомним, что существует несколько способов хранения агрегатных данных. Для данного примера вполне подойдет хранение всех данных в многомерной базе данных (MOLAP), так как объем исходных данных невелик. Однако в других случаях следует оценить, какой способ хранения наиболее выгоден для данной задачи.
Еще один вопрос, который следует решить при создании многомерного хранилища данных — сколько агрегатов следует хранить? Агрегаты — это заранее вычисленные агрегатные данные, соответствующие ячейкам куба. Чем их больше, тем быстрее выполняются запросы к многомерному хранилищу и тем больше объем самого хранилища. Поэтому в общем случае требуется некое их количество, позволяющее осуществить разумный баланс между компактностью и производительностью. Для определения количества агрегатов и их вычисления следует запустить Storage Design wizard — мастер создания многомерного хранилища. Для этого в редакторе кубов следует выбрать пункт меню Tools | Design Storage. В первой диалоговой панели следует указать способ хранения данных — MOLAP, ROLAP или HOLAP (в нашем примере мы выберем MOLAP). Затем выбрать, какова должна быть производительность при выполнении запросов (либо будущий максимальный объем хранилища). После этого можно нажать на кнопку Start и получить зависимость производительности от объема хранилища.

Рис. 5.15. Определение количества агрегатов
И наконец, нам необходимо вычислить сами агрегатные данные. Это можно сделать как в том же мастере создания хранилища, так и в редакторе кубов (команда Tools | Process Cube).
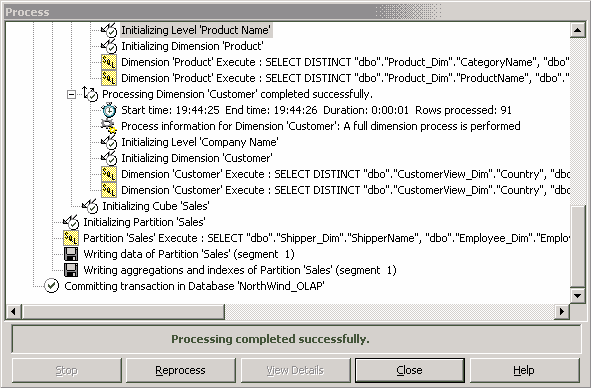
Рис. 5.16. Вычисление агрегатных данных
Теперь, когда куб готов, можно заняться его просмотром в редакторе кубов (для этого нужно выбрать закладку Data в нижней части экрана.
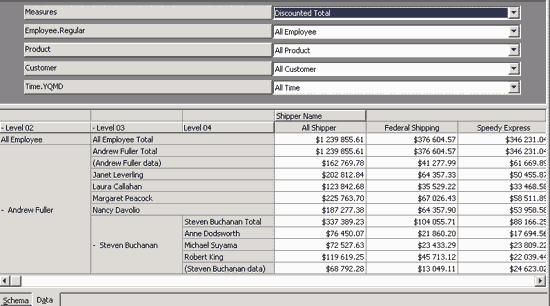
Рис. 5.17. Просмотр сечений куба
В редакторе кубов мы можем просматривать различные двухмерные сечения куба, перемещая имена измерений на горизонтальную и вертикальную оси, а также скрывая и раскрывая уровни. Это самый простой из способов просмотра кубов. О других способах чтения многомерных кубов мы расскажем в одной из следующих статей данного цикла.
OLAP клиенты
Проиллюстрируем возможности OLAP-клиентов на примере Microsoft Excel. Для начала кратко остановимся на компонентах Microsoft Office, используемых для работы с OLAP-данными, — это позволит нам в дальнейшем избежать терминологической путаницы. Тем более что все эти компоненты содержат в своем названии словосочетание PivotTable.
Первым из компонентов Microsoft Office, предназначенных для создания OLAP-клиентов, является набор библиотек PivotTable Service. С одной стороны, он является составной частью Analysis Services и выполняет роль связующего звена между Analysis Services и их клиентами (не обязательно имеющими отношение к Microsoft Office). PivotTable Service может быть установлен отдельно на компьютер, на котором эксплуатируются какие-либо клиенты Analysis Services; для его установки в состав Analysis Services входит отдельный дистрибутив. С другой стороны, PivotTable Service входит и в состав Microsoft Office 2000/XP и при этом может быть использован не только для работы с данными Analysis Services, но и для создания и чтения локальных OLAP-кубов, не имеющих отношения к Analysis Services, как с помощью Microsoft Excel, так и без него. Вторым компонентом, который может быть использован для просмотра OLAP-кубов, является служба, называемая PivotTable Reports, — средство создания сводных таблиц Microsoft Excel. Это средство позволяет получать, сохранять в кэше в оперативной памяти и отображать на листах рабочих книг двухмерные и трехмерные наборы агрегатных данных на основе данных из реляционных СУБД и рабочих книг Excel. PivotTable Reports входит в Excel начиная с версии 5.0, но возможность считывать с помощью него данные из OLAP-кубов Analysis Services, равно как и создавать локальные OLAP-кубы, впервые появилась в Excel 2000. Отметим, что средство создания сводных таблиц Excel использует библиотеки PivotTable Services. И наконец, третьим компонентом, применяемым при создании OLAP-клиентов, является PivotTable List — элемент управления ActiveX, входящий в состав Microsoft Office Web Components и предназначенный для просмотра сечений OLAP-кубов. Применяется он главным образом на Web-страницах, а иногда и в обычных Windows-приложениях.
Выяснив, что представляют собой средства чтения OLAP-кубов Microsoft Office, мы можем перейти к более детальному рассмотрению процесса чтения и отображения OLAP-кубов с помощью Microsoft Excel. Как было отмечено выше, средства создания сводных таблиц Microsoft Excel хранят в кэше агрегатные данные, вычисленные на основе данных из реляционных СУБД или полученные от OLAP-серверов. Манипулируя сводной таблицей, пользователь может управлять отображением данных из этого кэша. Прежде чем приступить к созданию примера, заметим, что посредством Microsoft Excel 2000 можно корректно отображать данные из OLAP-кубов, созданных с помощью Microsoft SQL Server 7.0 OLAP Services. Что касается OLAP-кубов, созданных с помощью Microsoft SQL Server 2000 Analysis Services, по большей части посредством Microsoft Excel 2000, то они также отображаются корректно, однако имеются и некоторые ограничения. Например, при создании локальных кубов OLAP или при сохранении сводной таблицы в виде Web-страницы с помощью соответствующих мастеров автоматически выбирается OLE DB-провайдер предыдущей версии (версии 7.0), не поддерживающий несбалансированные измерения. Это приводит к сообщениям об ошибках и к игнорированию таких измерений или даже всего источника данных. При использовании же Microsoft Excel 2002 эти проблемы не возникают.
В качестве примера создадим сводную таблицу, содержащую данные OLAP-куба, создание которого мы рассматривали в предыдущей главе. Для этого запустим Microsoft Excel и из меню Data выберем PivotTable and PivotChart Report. После этого управление будет передано мастеру PivotTable and PivotChart Wizard. В первой диалоговой панели этого мастера укажем, что для построения сводной таблицы выбирается внешний источник данных, для чего выберем опцию External data source. Затем укажем, что это за источник, нажав кнопку Get Data в следующей диалоговой панели, что приведет к запуску приложения Microsoft Query. Далее выберем закладку OLAP Cubes и, если в операционной системе еще нет описания соответствующего источника данных, создадим его.

Рис. 6.1. Описание источника данных
В процессе создания источника данных укажем его имя, выберем OLE DB-провайдер (в нашем случае — Microsoft OLE DB Provider for OLAP Services 8.0, поскольку мы используем Microsoft SQL Server 2000 Analysis Services) и нажмем на кнопку Connect.
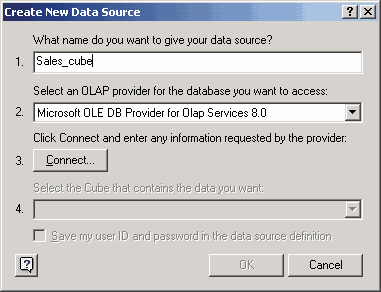
Рис. 6.2. Выбор провайдера данных
В диалоговой панели Multidimensional Connection укажем имя компьютера (если это локальный компьютер, можно использовать имя localhost), на котором расположен OLAP-сервер, а также данные для аутентификации пользователя, которые понадобятся только в том случае, если для связи с OLAP-сервером мы используем HTTP-протокол.
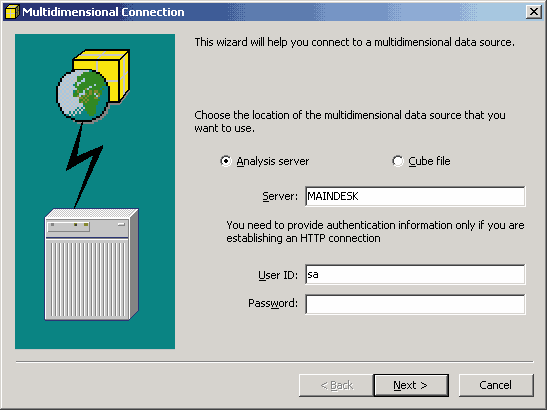
Рис. 6.3. Выбор OLAP-сервера
И наконец, выберем имя многомерной базы данных, в которой хранится OLAP-куб.
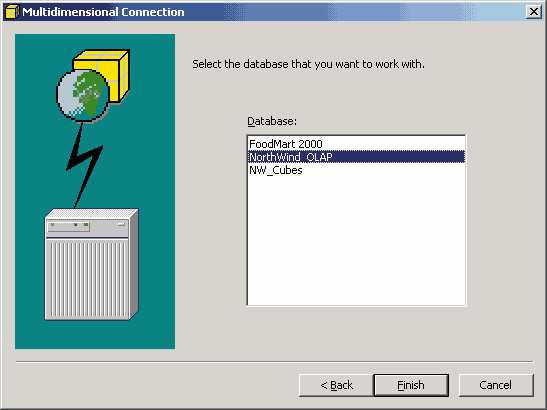
Рис. 6.4. Выбор многомерной базы данных
Определив источник данных, выберем куб, который мы будем отображать в сводной таблице.
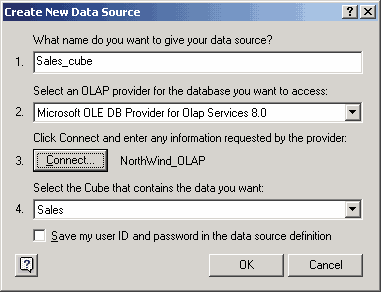
Рис. 6.5. Выбор куба для отображения в сводной таблице
После этого можно нажать кнопку OK. В результате мы получим пустую сводную таблицу, вид которой в Excel 2000:

Рис. 6.6. Сводная таблица в Excel 2000
Для дальнейших манипуляций нам потребуется панель инструментов PivotTable. В случае с Excel 2000 пользоваться ею удобнее, если она не закреплена у края окна Excel, а свободно перемещается по экрану, в противном случае некоторые нужные нам элементы этой панели окажутся недоступны.
Следует отметить, что, когда фокус ввода находится на самой сводной таблице (для чего достаточно щелкнуть по ней мышью), панель PivotTable в Excel 2000 содержит кнопки с названиями измерений и мер куба. Отметим, что они обозначаются пиктограммами разного вида и, если их названия не умещаются на кнопке, их можно увидеть на всплывающих подсказках. При смещении фокуса ввода в другое место листа эти кнопки исчезают. В Excel 2002 диалоговая панель PivotTable выглядит иначе — она не содержит кнопок с именами измерений и мер. Их список предоставляется в отдельной панели PivotTable Field List.

Рис. 6.7. Сводная таблица в Excel 2002
Теперь нам необходимо определить, какие из мер мы хотим отобразить в сводной таблице. Для этого достаточно перенести мышью кнопку (в случае Excel 2002 — соответствующий элемент из списка) с наименованием нужной меры в область данных.
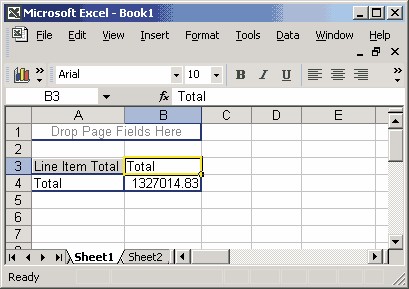
Рис. 6.8. Выбор меры для отображения в сводной таблице
Теперь требуется определить, какие из полей будут участвовать в формировании строк, столбцов и страниц (иногда последние называются фильтрами). В общем случае сводная таблица является трехмерной, и можно считать, что третье измерение расположено перпендикулярно экрану, а мы наблюдаем сечения, параллельные плоскости экрана и определяемые тем, какая «страница» выбрана для отображения. Осуществить фильтрацию можно путем перетаскивания мышью соответствующих кнопок с панели инструментов PivotTable (в случае Excel 2002 — соответствующих элементов с панели PivotTable Field List) на области строк, столбцов и страниц сводной таблицы — Row Area, Column Area и Page Area.

Рис. 8.9. Готовая сводная таблица
Итак, мы отобразили в сводной таблице Excel содержимое OLAP-куба. Теперь этим отображением можно манипулировать.
Если нас интересуют более подробные данные, связанные с одним из членов одного из отображаемых измерений, можно дважды щелкнуть по ячейке с этим значением и отобразить члены следующего уровня данного измерения (эта операция называется drill-down). То, что получится, если дважды щелкнуть на ячейке A5:

Рис. 6.10. Результат операции drill-down
Если же нас интересуют более подробные данные, нежели представленные в данный момент в сводной таблице, следует выбрать ячейку с именем соответствующего измерения (например, ячейку A4) и нажать на панели инструментов PivotTable кнопку Show Detail.

Рис. 6.11. Отображение следующего уровня иерархии измерения
При необходимости можно вручную определить, какие члены измерения должны быть отображены в сводной таблице; для этого можно нажать кнопку вывода соответствующего выпадающего списка в правой части ячейки с именем измерения.
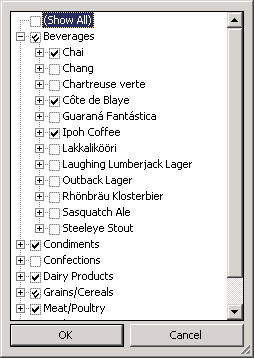
Рис. 6.12. Выбор отображаемых членов измерения
Если в сводной таблице отображается несколько мер, они формируют отдельное дополнительное измерение Data. По умолчанию оно располагается на оси строк, но может быть перенесено и на ось столбцов.
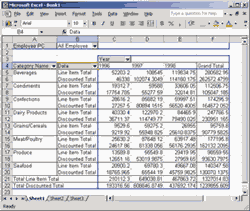
Рис. 6.13. Отображение нескольких мер в сводной таблице
Если в сводной таблице оставить только одну меру, перенеся оставшиеся обратно на панель инструментов PivotTables, измерение Data исчезнет. Отметим, что с помощью одного из доступных в Excel шаблонов оформления можно изменить оформление сводной таблицы. Кроме того, можно выбрать на панели инструментов PivotTables пункты меню PivotTable | Table Options или PivotTable | Field Settings и изменить другие параметры отображения данных в сводной таблице. Применяя Excel в качестве OLAP-клиента, следует помнить, что объем данных, отображаемых в сводной таблице, ограничен — ведь все эти данные хранятся в оперативной памяти клиентского компьютера.
При необходимости в Excel можно построить сводную диаграмму, синхронизированную со сводной таблицей. Для этого достаточно нажать соответствующую кнопку на панели инструментов PivotTables и, если нужно, отредактировать внешний вид диаграммы.

Рис. 6.14. Сводная диаграмма с данными OLAP-куба
Отметим, что с помощью панелей инструментов PivotTable и PivotTable FieldList, а также выпадающих списков на осях и легенде можно управлять отображением данных на сводной диаграмме, например выполнять операцию drill-down; при этом сводная таблица будет меняться синхронно с диаграммой. Как уже было отмечено выше, Microsoft Excel позволяет создавать локальные OLAP-кубы, представляющие собой подмножества данных серверных OLAP-кубов. Локальные кубы хранятся в файлах с расширением *.cub. Напомним, что для корректного создания локального куба на основе серверного куба, содержащего несбалансированные измерения, рекомендуется применять Microsoft Excel 2002. Поэтому все последующие примеры выполнены в этой версии Microsoft Excel.
Чтобы создать локальный OLAP-куб на основе серверного куба, следует на панели инструментов PivotTables выбрать пункт меню PivotTable | Offline OLAP в Excel 2002 (в Excel 2000 ему соответствовал пункт меню PivotTable | Client-Server Settings) и нажать кнопку Create offline data file.
Рис. 6.15. Диалоговая панель Offline OLAP Settings
Далее следует выбрать измерения и их уровни, а также меры, которые будут присутствовать в локальном кубе.
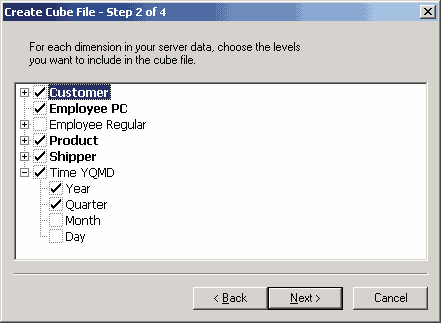
Рис. 6.16. Выбор измерений и мер для локального куба
Помимо выбора измерений, их уровней и мер можно внести и другие ограничения в набор данных, который будет содержаться в локальном кубе, выбрав набор членов изменений, участвующих в его формировании.

Рис. 6.17. Выбор членов измерений для локального куба
Теперь осталось только сохранить локальный куб в файле с расширением *.cub. Отметим, что этот файл является отчуждаемым: его можно просматривать на любом компьютере, оснащенном как Microsoft Excel 2002, так и Microsoft Excel 2000, независимо от наличия на нем Microsoft SQL Server Analysis Services или их клиентской части.