Семинар 3
Метод главных компонент
В этом примере анализируются социально-экономические данные, предоставленные Harman (1976). Пять переменных представляют:
- общую численность населения (население),
- средние школьные годы (школа),
- общую занятость (занятость),
- различные профессиональные услуги (услуги),
- медианную стоимость дома (HouseValue).
Каждое наблюдение представляет один из двенадцати переписных участков в столичной статистической зоне Лос-Анджелеса.
Проведем анализ главных компонентов путем создания программы следующей программы в SAS Studio:
data SocioEconomics;
input Population School Employment Services HouseValue;
datalines;
5700 12.8 2500 270 25000
1000 10.9 600 10 10000
3400 8.8 1000 10 9000
3800 13.6 1700 140 25000
4000 12.8 1600 140 25000
8200 8.3 2600 60 12000
1200 11.4 400 10 16000
9100 11.5 3300 60 14000
9900 12.5 3400 180 18000
9600 13.7 3600 390 25000
9600 9.6 3300 80 12000
9400 11.4 4000 100 13000
;
proc factor data=SocioEconomics simple corr;
run;
Вы начинаете со спецификации необработанного набора данных с 12 наблюдениями. Затем вы используете опцию DATA = в операторе PROC FACTOR, чтобы указать набор данных в анализе. Кроме того, вы можете установить параметры SIMPLE и CORR для дополнительных результатов вывода, которые показаны в выходных данных 41.1.2 и 41.1.3 соответственно.
По умолчанию PROC FACTOR предполагает, что все начальные сообщества равны 1, что имеет место для текущего анализа основных компонентов. Если вы намерены вместо этого найти общие факторы, используйте опцию PRIORS = или оператор PRIORS, чтобы установить для исходных общностей значения меньше 1, что приводит к извлечению основных факторов, а не главных компонентов. См. Пример 41.2 для спецификации основного факторного анализа.
Для текущего анализа PCA первая выходная таблица отображается в выходных данных 41.1.1.
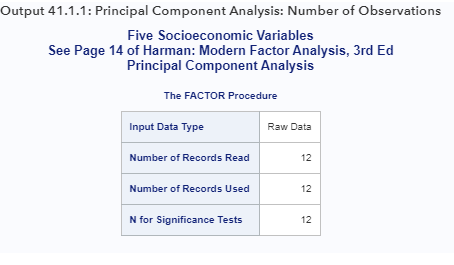
На выходе 41.1.1 тип входных данных показан как необработанные данные. PROC FACTOR также принимает другие типы данных, такие как корреляции и ковариации. См. Пример 41.5 для использования корреляций в качестве входных данных. Для текущего набора необработанных данных PROC FACTOR считывает 12 записей, и все эти 12 записей используются. Если в наборе данных отсутствуют значения, эти два числа могут не совпадать из-за удаления записей с пропущенными значениями. Последний ряд таблицы показывает, что 12 используется в тестах значимости, проводимых в анализе.
Опция SIMPLE, указанная в операторе PROC FACTOR, генерирует средние и стандартные отклонения всех наблюдаемых переменных в анализе, как показано в выходных данных 41.1.2.
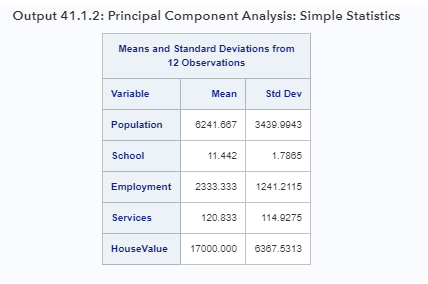
Диапазоны средних и стандартных отклонений для анализа довольно велики. Переменные измеряются в совершенно разных масштабах. Однако это не проблема, потому что PROC FACTOR в основном анализирует стандартизированные шкалы (то есть корреляции) переменных.
Опция CORR, указанная в операторе PROC FACTOR, генерирует выходные данные наблюдаемых корреляций в выходных данных 41.1.3.
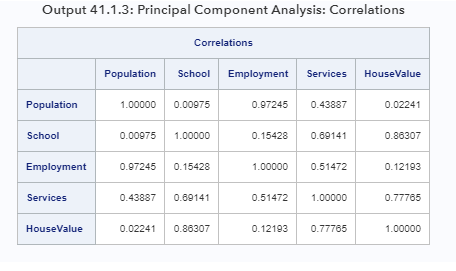
Корреляционная матрица, показанная в выходных данных 41.1.3, анализируется PROC FACTOR.
Первым этапом анализа главных компонент является рассмотрение собственных значений матрицы корреляции. Большие собственные значения извлекаются первыми. Поскольку существует пять наблюдаемых переменных, пять собственных значений могут быть извлечены, как показано в Выходе 41.1.4.
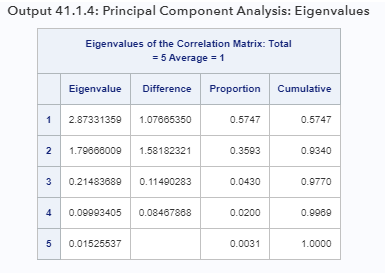
В Выходе 41.1.4 два самых больших собственных значения - 2.8733 и 1.7967, которые вместе составляют 93.4% стандартизированной дисперсии. Таким образом, первые два основных компонента обеспечивают адекватную сводку данных для большинства целей. Три компонента, которые объясняют 97,7% вариации, должны быть достаточными для почти любого применения. PROC FACTOR сохраняет первые два компонента на основе правила собственных значений больше единицы, поскольку третье собственное значение составляет всего 0,2148.
Чтобы выразить наблюдаемые переменные как функции компонентов (или факторов в целом), вы обращаетесь к матрице факторных нагрузок, как показано в Выходных данных 41.1.5.
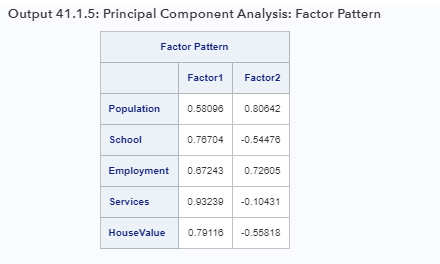
Существует как минимум два способа интерпретировать эти факторные нагрузки.
Во-первых, вы можете использовать эту таблицу, чтобы выразить наблюдаемые переменные как функции извлеченных факторов (или компонентов, как в текущем анализе). В каждой строке загрузок факторов указывается линейная комбинация показателей факторов или компонентов, которая дает ожидаемое значение связанной переменной.
Во-вторых, вы можете интерпретировать каждую загрузку как корреляцию между наблюдаемой переменной и фактором или компонентом, при условии, что факторное решение является ортогональным (то есть факторы некоррелированы), например текущее исходное решение для фактора. Следовательно, факторные нагрузки показывают, насколько тесно связаны переменные и факторы или компоненты.
На выходе 41.1.5 первый компонент (помеченный как «Фактор1») имеет большие положительные нагрузки для всех пяти переменных. Его корреляция с Сервисами (0,9324) особенно высока. Второй компонент - это, в основном, контраст между населением (0,8064) и занятостью (0,7261) по отношению к школе (–0,5448) и HouseValue (–0,5582) с очень небольшой нагрузкой на службы (–0,1043).
Общая дисперсия, объясненная этими двумя компонентами, показана в Выходных данных 41.1.6.
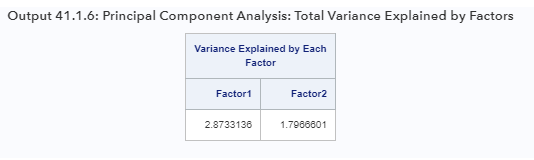
На первый и второй компоненты приходится 2,8733 и 1,7967, соответственно, общей дисперсии, равной 5. В исходном решении факторов полная дисперсия, объясняемая факторами или компонентами, совпадает с извлеченными собственными значениями. (Сравните общую дисперсию с собственными значениями, показанными в выходных данных 41.1.4.) Из-за отбрасывания менее важных компонентов сумма этих двух чисел составляет 4,6700, что лишь немного меньше, чем общая дисперсия 5 исходной корреляции. матрица.
Вы также можете посмотреть на дисперсию, объясненную двумя компонентами для каждой наблюдаемой переменной в Выходе 41.1.7.
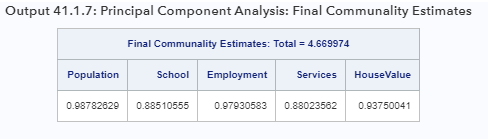
В Результате 41.1.7 окончательные оценки общности показывают, что все переменные хорошо учтены двумя компонентами, при этом окончательные оценки общности варьируются от 0,8802 для Служб до 0,9878 для Населения. Сумма сообществ составляет 4.6700, что совпадает с суммой дисперсии, объясненной двумя компонентами, как показано в Результат 41.1.6.
Анализ главных компонент с использованием PROC FACTOR и PROC PRINCOMP
Анализ основных компонент PROC FACTOR подчеркивает, как основные компоненты объясняют наблюдаемые переменные. Факторные нагрузки в шаблоне коэффициентов, как показано в выходном файле 41.1.5, представляют собой коэффициенты для объединения оценок факторов / компонентов для получения наблюдаемых переменных оценок, когда ожидаемые остатки ошибок равны нулю. Например, прогнозируемое стандартизированное значение Population с учетом значений факторов / компонентов для Factor1 и Factor2 определяется как:

Если вы в первую очередь заинтересованы в получении оценок компонентов в виде линейных комбинаций наблюдаемых переменных, таблица матрицы загрузки коэффициентов не является для вас подходящей. Однако вы можете запросить стандартизированные оценочные коэффициенты, добавив опцию SCORE в операторе FACTOR:
proc factor data=SocioEconomics n=5 score;run;В предыдущем операторе PROC FACTOR указано N = 5 для сохранения всех пяти компонентов. Это делается для сравнения результатов PROC FACTOR с результатами PROC PRINCOMP, что будет описано позже. Опция SCORE запрашивает отображение стандартизированных скоринговых коэффициентов, которые показаны в выходных данных 41.1.8.
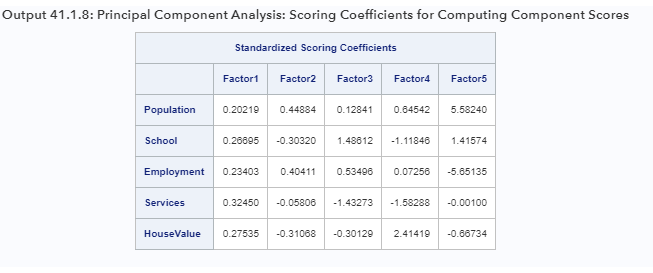
В выходных данных 41.1.8 каждый фактор / компонент выражается в виде линейной комбинации стандартизированных наблюдаемых переменных. Например, первый главный компонент или Factor1 вычисляется как:

Опять же, при применении этой формулы вы должны использовать стандартизированные наблюдаемые переменные (со средним значением 0 и стандартным отклонением 1), но не необработанные данные.
Помимо некоторых различий в масштабировании, набор скоринговых коэффициентов, полученных из PROC FACTOR, эквивалентен тем, которые получены из PROC PRINCOMP, как указано в следующем утверждении:
proc princomp data=SocioEconomics;run;
PROC PRINCOMP отображает скоринговые коэффициенты в виде собственных векторов, которые показаны в выходных данных 41.1.9.
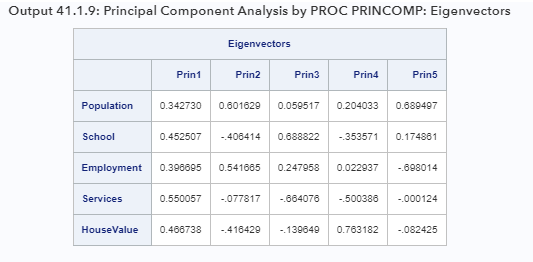
Например, чтобы получить первую оценку основного компонента, используйте следующую формулу:

Эта формула не совсем совпадает с формулой, показанной с помощью PROC FACTOR. Все оценочные коэффициенты в PROC FACTOR меньше, примерно в 0,59 раза по сравнению с коэффициентами, полученными из PROC PRINCOMP. Причина скалярного различия заключается в том, что PROC FACTOR предполагает, что все факторы / компоненты имеют дисперсию 1, а PROC PRINCOMP создает компоненты, которые имеют дисперсии, равные собственным значениям. Вы можете выполнить простое изменение масштаба стандартизированных скоринговых коэффициентов, полученных из PROC FACTOR, чтобы они соответствовали соответствующим собственным векторам из PROC PRINCOMP. По сути, вам необходимо изменить масштаб каждого столбца стандартизированных скоринговых коэффициентов, полученных из PROC FACTOR, чтобы сумма квадратов была равна единице, что является определяющей характеристикой собственных векторов. Это может быть достигнуто путем деления каждого коэффициента на квадратный корень суммы квадратов в соответствующем столбце.
Для данного примера вы можете использовать PROC STDIZE для изменения масштаба, как показано в следующих инструкциях:
proc factor data=SocioEconomics n=5 score; ods output StdScoreCoef=Coef;run; proc stdize method=ustd mult=.44721 data=Coef out=eigenvectors; var Factor1-Factor5;run; proc print data=eigenvectors;run;Сначала вы создаете выходной набор Coef для стандартизированных скоринговых коэффициентов с помощью оператора ODS OUTPUT. Обратите внимание, что «StdScoreCoef» - это таблица ODS, которая содержит стандартизированные скоринговые коэффициенты, как показано в Выходных данных 41.1.8. (См. Таблицу 41.6 для всех имен таблиц ODS для PROC FACTOR.) Затем вы используете METHOD = USTD в операторе PROC STDIZE, чтобы разделить выходные коэффициенты на соответствующие нескорректированные (для среднего) стандартных отклонений. Следующая формула показывает взаимосвязь между нескорректированным стандартным отклонением и суммой квадратов:
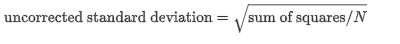
Напомним, что то, что вы намерены разделить от каждого коэффициента, это его квадратный корень из суммы столбцов соответствующего квадрата. Поэтому, чтобы настроить то, что PROC STDIZE делает с помощью METHOD = USTD, необходимо умножить каждую переменную на постоянный член 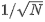 в стандартизации. В текущем примере этот постоянный член равен 0,44721
в стандартизации. В текущем примере этот постоянный член равен 0,44721  и указывается с помощью параметра MULT = в операторе PROC STDIZE. С опцией OUT =, пересчитанные скоринговые коэффициенты сохраняются в собственных векторах набора данных SAS. Распечатка набора данных на выходе 41.1.10 показывает масштабированные стандартизированные оценочные коэффициенты, полученные из PROC FACTOR.
и указывается с помощью параметра MULT = в операторе PROC STDIZE. С опцией OUT =, пересчитанные скоринговые коэффициенты сохраняются в собственных векторах набора данных SAS. Распечатка набора данных на выходе 41.1.10 показывает масштабированные стандартизированные оценочные коэффициенты, полученные из PROC FACTOR.
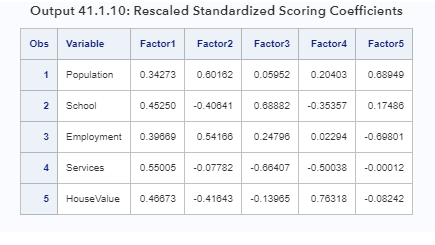
Как вы можете видеть, эти стандартизированные скоринговые коэффициенты, по сути, такие же, как и полученные из PROC PRINCOMP, как показано в выходном файле 41.1.9. Этот пример показывает, что анализ основных компонентов PROC FACTOR и PROC PRINCOMP действительно эквивалентны. PROC PRINCOMP больше подчеркивает линейные комбинации переменных для формирования компонентов, в то время как PROC FACTOR выражает переменные как линейные комбинации компонентов в выходных данных.