Альфа-разнообразие — внутреннее разнообразие местообитания или одного сообщества.
Существует 3 возможных типа мер альфа-разнообразия, определенных Такером (2000):
• видовое богатство, определяемое как число видов, присутствующих на определенной территории (от небольшого местообитания до страны или биогеографического региона);
• численность вида (обычно какой-то его популяции);
• видовое разнообразие, т. е. соотношения числа видов и их численностей.
Для количественной оценки альфа-разнообразия обычно используют два подхода:
• построение кривых относительного обилия или доминирования — разнообразия;
• расчет индексов, представляющих различные математические выражения.
При расчете индексов для оценки альфа-разнообразия принимаются во внимание 2 фактора:
• видовое богатство — число видов, отнесенное к определенной площади;
• выравненность и доминирование — равномерность распределения видов по их обилию в сообществе.
1.1. Индексы видового богатства
Важной мерой оценки разнообразия для ограниченного в пространстве и во времени сообщества, для которого точно известно число составляющих его видов и особей, является видовое богатство. Однако в большинстве случаев исследователь имеет дело с выборкой, не располагая полным списком видов сообщества. В этом случае необходимо использовать нумерическое видовое богатство, т. е. число видов на строго оговоренное число особей или на определенную биомассу, и видовую плотность.
Видовая плотность — число видов, отмечаемых на определенной, заранее оговоренной территории (например, на 1 м2, 1 га). Это один из наиболее распространенных показателей видового богатства. Видовое разнообразие в разных местах часто зависит от шкалы измерения разнообразия (Мэгарран, 1992). Например, в 1 м2 полуестественных европейских пастбищ может быть больше видов, чем в нижнем ярусе дождевого тропического леса в бассейне Амазонки. Разнообразие видов на 1 км и более будет выше в тропическом лесу. Данный показатель очень сильно зависит от размеров изучаемой площади, поэтому при сравнении разновеликих территорий для частичного устранения данной зависимости используют индекс концентрации видового богатства Dc r:
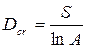 ,
,
где S — число видов; А — площадь местообитания.
Занимаясь изучением биологического разнообразия на какой-либо территории, исследователь, как правило, не знает полного числа видов живых организмов, которые там находятся. Имея дело с выборками организмов из данного местообитания, он может учесть только число видов, которые попали в эти выборки (S). При этом вероятность выявления каждого вида будет прямо пропорциональна его частоте встречаемости. Как правило, обильные виды выявляются уже при небольшом размере выборок, тогда как очень редкие могут не быть обнаружены даже при больших размерах выборок. И чем больше выборка — тем выше вероятность выявления полного видового состава изучаемого сообщества.
Довольно часто возникает необходимость сравнить между собой видовое богатство сообществ, по которым у исследователя имеются выборки различного объема. В этом случае следует учитывать, что различное число видов в выборках может быть вызвано как различиями в видовом богатстве сообществ, так и размерами выборок. Для преодоления этой проблемы был разработан так называемый метод разрежения, а также предложено большое число индексов.
Метод разрежения позволяет рассчитать число видов в так называемой редуцированной выборке (т. е. выборке меньших размеров по сравнению с исходной). Этот метод впервые был предложен Сандерсом (1968), но в дальнейшем для обеспечения несмещенной оценки он был преобразован Хэлбертом (1971). При этом можно оценить ожидаемое число видов E(SN') в выборке объемом N' особей, взятой случайным образом из более крупной выборки, включающей N особей, принадлежащих к S видам.
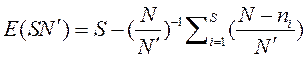
где 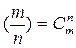 — число сочетаний из т элементов по п.
— число сочетаний из т элементов по п.
Оно рассчитывается следующим образом:
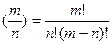 ,
,
где n! – n -факториал.
В основе индексов, позволяющих оценить видовое богатство, лежат различные сочетания S (число выявленных видов) и N (общее число особей всех S видов). Основным недостатком таких индексов является их очень сильная зависимость от объема выборки. В наименьшей степени этому недостатку подвержен индекс видового богатства Менхиника:
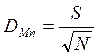 .
.
Довольно широкое распространение получил также индекс, предложенный геоботаником Глизоном и гидробиологом Марга-лефом. Индекс видового богатства Глизона — Маргалефа:
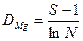 .
.
Как видно из формул, данные индексы полностью зависят от объема выборки, из-за чего они не всегда пригодны, особенно при работе с группами, для которых сложно быстро и полностью выявить видовой состав. С другой стороны, для групп, в которых немного видов и они хорошо обнаруживаются, может быть быстро достигнута близкая к абсолютной оценка S, и вес N будет продолжать расти несмотря на логарифмирование или извлечение из корня. В то же время достоинство этих индексов — легкость расчетов. Большая величина индекса соответствует большему разнообразию.
1.2. Индексы видового разнообразия
Индексы видового разнообразия — это соотношения между числом видов и каким-либо показателем, имеющим значимость для сообщества и экосистемы, — численностью, биомассой, продуктивностью и др. (Снакин, 2000).
Цель введения различных индексов — охарактеризовать и смоделировать многокомпонентную структуру сообществ с тем, чтобы наиболее полно сравнивать их между собой (Терещенко и др., 1994). Индексы, предлагаемые для оценки биоразнообразия, должны отвечать определенным требованиям:
• небольшие изменения обилия массовых видов, появление и исчезновение редких видов не должны сильно влиять на величину индекса;
• индекс не должен зависеть от параметров, дифференцированно характеризующих разные виды, т. е. он должен относиться ко всем видам равноценно;
• индекс должен иметь экологическую интерпретацию и обладать приемлемыми статистическими свойствами, т. е. простотой в понимании и расчетах;
• вклад отдельных видов в величину индекса должен быть пропорционален их обилию.
Среди общего числа видов, образующих сообщество, некоторые могут преобладать по какому-то показателю (численность, биомасса, продуктивность) — их называют доминирующими. В этом случае велика вероятность того, что значительная часть оставшихся в сообществе видов будет иметь минимальные показатели, т. е. являться редкими. В то же время возможен и диаметрально противоположный случай, когда доминантные виды отсутствуют и целый ряд видов обладает определенным обилием и достаточно равномерным распределением по тем же значимым признакам (численность и др.). В этом случае говорят о выравненности (равномерном распределении) видов в структуре сообщества. Например, две биологические системы, состоящие из 100 особей, принадлежащих к 10 видам (т. е. одинаковое видовое богатство), могут иметь два крайних варианта распределения особей: максимальное доминирование и минимальную выравнен-ность (91 особь принадлежит к одному виду, а остальные 9 — к девяти различным видам); максимальную выравненность и отсутствие доминирования (каждый из 10 видов представлен десятком особей). На показателях доминирования или выравненности чаще всего основан расчет тех или иных индексов.
В настоящее время существует более 40 индексов, предназначенных для оценки биоразнообразия. Индексы, применяемые в анализе разнообразия сообществ, должны удовлетворять следующим требованиям (Песенко, 1982):
1) разнообразие сообщества тем выше, чем больше в нем видов;
2) разнообразие сообщества тем выше, чем выше его выравненность.
Большинство различий между индексами, измеряющими биоразнообразие, заключается в том, какое значение они придают выравненности и видовому богатству.
Индекс Шеннона. Один из наиболее широко применяемых индексов видового разнообразия. Он основан на изучении вероятности наступления цепи событий, т, е. является информационной мерой разнообразия, которая выражается в единицах неопределенности или информации. Данный индекс впервые был предложен К. Шенноном в 1948 г., а в биологических исследованиях впервые применен Макартуром и Маргалефом в середине 1950-х гг.
Чаще всего используется основное выражение индекса
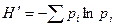 ,
,
где pi – доля i-го вида в выборке. В выборке истинное значение pi неизвестно. Оно оценивается как ni/N, что дает смещенный результат. Это связано с тем, что расчеты индекса разнообразия Шеннона предполагают попадание в выборку особей случайно из «неопределенно большой» (т. е. практически бесконечной) генеральной совокупности. Более точное значение индекса можно получить из ряда
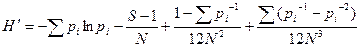 .
.
Однако на практике эта ошибка редко бывает значимой. Более существенную погрешность вносит тот факт, что расчет индекса Шеннона предполагает наличие в выборке всех видов генеральной совокупности. Поэтому чем меньше видов оказалось в выборке по сравнению с их действительным количеством, тем более смещенной оказывается оценка.
При вычислении обычно используется натуральный логарифм, реже десятичный или логарифм по основанию 2. К сожалению, во многих публикациях не уточняется, какое основание применено, что затрудняет сравнение полученных данных с данными литературы, особенно когда не указано и число видов. Хотя стоит отметить, что в настоящее время прослеживается устойчивая тенденция к стандартизации расчетов путем использования натурального логарифма.
Индекс Шеннона обычно варьирует в пределах от 1,5 до 3,5, очень редко превышая 4,5. Как показывают расчеты, для получения значения индекса Шеннона, равного 5, необходимо оперировать выборкой, в которой содержится 105 видов.
Индекс Шеннона имеет оценку дисперсии и стандартной ошибки, что допускает основные статистические процедуры. Если рассчитать индекс Шеннона для нескольких выборок, то полученные значения будут распределены нормально. Это позволяет применять мощные параметрические методы анализа, включая дисперсионный, что особенно полезно в том случае, если есть повторности.
Дисперсию индекса Шеннона (VarH´) рассчитывают по формуле
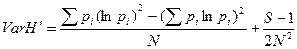
Для проверки значимости различий между выборочными совокупностями значений индекса Шеннона можно использовать параметрический критерий Стьюдента:
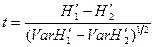 .
.
Число степеней свободы определяется по уравнению:
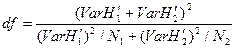 ,
,
где N1 и N2 — общее число видов в двух выборках.
Индекс выравненности по Шеннону, или индекс Пиелу. Являясь индексом разнообразия, индекс Шеннона учитывает как видовое богатство, так и выравненность видов в выборке. В то же время на основе индекса Шеннона можно получить индекс, который оценивает только выравненность. Выравненность по Шеннону рассчитывается исходя из того, что при одном и том же объеме выборки и числе видов максимальное значение этот индекс принимает при равном обилии всех входящих в выборку видов. Если же доля какого-то одного вида (в случае доминирования) стремится к 1, а всех остальных — к 0, то значение индекса также стремится к 0. Показатель выравненности Е рассчитывается как отношение наблюдаемого разнообразия к максимальному:
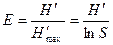 .
.
Е имеет значения от 0 до 1, причем чем выше значение, тем более выровнена выборка. При этом Е = 1 соответствует равному обилию всех видов, входящих в выборку.
Индекс Шелдона.. Представляет собой экспоненциальную форму индекса Шеннона:
SH = ехр (Н').
Он принимает значения от 1 (наличие только одного вида) до N в случае максимально разнообразного сообщества, в котором каждый вид представлен только одной особью. С биологической точки зрения индекс Шелдона показывает, какое число видов содержится в гипотетической выборке с равнообильными видами, разнообразие которой равно наблюдаемому (Песенко, 1982).
Индекс Бриллуэна. Когда невозможно гарантировать случайный отбор объектов в выборочную совокупность или учесть все виды сообщества, более подходящей по сравнению с индексом Шеннона формой информационно-статистического индекса может быть индекс Бриллуэна. Он рассчитывается по формуле
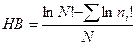 .
.
Индекс Бриллуэна дает сходную с индексом Шеннона величину разнообразия, редко превышая 4,5. Однако при оценке одних и тех же данных его величина ниже индекса Шеннона. Это объясняется отсутствием в нем неопределенности, свойственной индексу Шеннона. Главным различием индексов является то, что индекс Шеннона всегда дает одну и ту же величину, если число видов и их относительные обилия остаются постоянными, а индекс Бриллуэна этим свойством не обладает.
К недостаткам индекса можно отнести относительную сложность расчетов, возможность получить неверные выводы при сравнении малых выборок и невозможность применения индекса к выборкам, имеющим большую долю неопределенности. В то же время этот индекс рекомендуется использовать, если оценивается коллекция, а не случайная выборка, и если известен полный состав сообщества.
Индекс выровненности по Бриллуэну. При его применении (аналогично индексу Шеннона) выравненность определяется как отношение наблюдаемого разнообразия к максимальному:
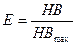 .
.
Максимальное значение индекса Бриллуэна рассчитывается по формуле
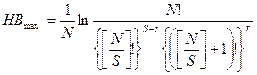
где [N/S] — целая часть отношения N/S, а r = N - S[N/S].
Индекс Симпсона. Данный индекс, иногда называемый мерой концентрации, описывает вероятность принадлежности любых двух особей, случайно отобранных из неопределенно большого сообщества, к разным видам следующей формулой:
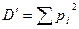 ,
,
где pi — доля особей i-ro вида.
В том случае, если имеется конечное сообщество, для расчета индекса должна быть применена формула:
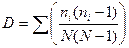 ,
,
где ni — число особей i-го вида; N — общее число особей.
С точки зрения теории вероятностей приведенные выше формулы имеют следующий биологический смысл. Представим, что две особи случайным образом изымаются из сообщества, имеющего N особей, принадлежащих к S видам, из которых ni особей принадлежат i-му виду. Тогда первая формула соответствует вероятности того, что обе особи принадлежат к одному виду при условии, что они будут возвращены в сообщество. Вторая формула отражает то же, но с условием, что учтенные особи не будут возвращены в сообщество. Это обусловливает заниженные оценки при расчетах по второй формуле по сравнению с первой, так как в этом случае игнорируются виды, представленные в сообществе одной особью.
Индекс Симпсона с биологической точки зрения можно интерпретировать еще и как меру концентрации главного ресурса в распоряжении немногих видов. Он обладает следующими свойствами: равен нулю при S = 0; стремится к нулю при S→ ∞, равен единице при S = 1. Он имеет оценку дисперсии и стандартной ошибки.
Вероятность межвидовых встреч. По мере увеличения значения индекса Симпсона разнообразие уменьшается, поэтому в качестве меры разнообразия часто используется дополнение к данному индексу (1 - D) или (1 - D'). Эта величина носит название «вероятность межвидовых встреч» и варьирует от 0 до 1:
PIE'=1-D'=1- ∑ pi2,
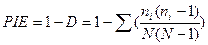 .
.
Для данного индекса можно рассчитать максимальное и минимальное значения разнообразия в выборке с данными N и S, соответствующие крайним типам распределения особей по видам в ней. Разнообразие выборки будет максимальным в том случае, когда все особи будут равномерно распределены по видам:
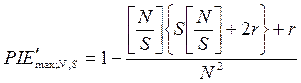 ,
,
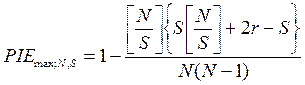 ,
,
где [N/S] — целая часть отношения N/S;r — остаток от деления N на S, целое число меньше S; r = N - S[N/S].
Минимальные оценки PIE' и PIE, соответствующие крайне неравномерному распределению N особей по S видам, вычисляются по следующим формулам:
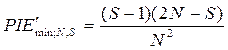 ,
,
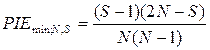 .
.
Исходя из полученного реального значения индекса вероятности межвидовых встреч для изучаемой выборки, а также из рассчитанных минимального и максимального значений для выборки с такими же значениями N и S, можно оценить ее выравненность.
Индекс полидоминантности. В качестве меры разнообразия, рассчитанной на основании индекса Симпсона, может быть использовано отношение данного индекса к единице, которое иногда называют индексом полидоминантности. Он показывает, какое число видов присутствует в гипотетической выборке, где все виды равнообильны, если она имеет такое же разнообразие, как данная выборка (Песенко, 1982). Рассчитывается индекс полидоминантности по следующим формулам:
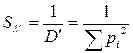 ,
,
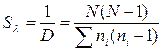 .
.
Индексы полидоминантности служат полезными трансформациями PIE' и PIE в том случае, когда анализируемые выборки имеют высокие значения индекса вероятности межвидовых встреч или если желательно выразить разнообразие в таких интерпретируемых единицах, как число видов.
Индексы Макинтоша. В том случае, если выборка состоит из N особей, распределенных по S видам, и численность i-гo вида равняется ni, эту выборку можно представить в S-мерном гиперпространстве как точку с координатами (n1, п2,..., ns). В 1967 г. Макинтош предложил в качестве индекса, измеряющего разнообразие, евклидово расстояние от точки, соответствующей выборке, до точки начала координат (0, 0,..., 0):
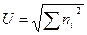 .
.
Из формулы видно, что при одном и том же числе особей чем большее число видов включает выборка, тем меньше U. Следовательно, индекс Макинтоша U сам по себе не является индексом доминирования, а измеряет, наоборот, однообразие выборки. Поэтому в качестве меры разнообразия может быть использовано N-дополнение до U:
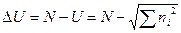 .
.
Эти индексы очень редко непосредственно используются при анализе биоразнообразия, так как являются ненормированными и очень чувствительными к размеру выборки. В то же время, используя их, можно рассчитать индекс разнообразия D, который независим от объема выборки:
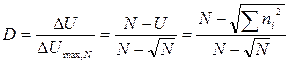 .
.
Данный индекс имеет диапазон значений от нуля при наличии в выборке только одного вида до единицы в том случае, если в выборке каждый вид представлен только одной особью. Минимум этого индекса для выборки с N особями S видов достигается при ее крайней невыравненности:
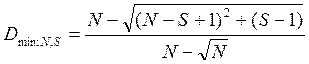 ,
,
а максимум — при полной выравненности:
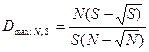 .
.
Исходя из полученных значений, можно рассчитать выравненность выборки:
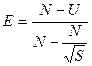
Индекс Бергера — Паркера. Этот индекс является одним из наиболее простых и легко интерпретируемых индексов доминирования. Его достоинство — простота вычисления. Индекс Бергера — Паркера представляет собой долю самого массового вида в выборке:
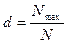
где Nmax —число особей самого обильного вида.
Так как при увеличении степени доминирования одного вида и, как следствие этого, увеличении величины индекса Бергера — Паркера происходит уменьшение разнообразия, то обычно используется величина, обратная индексу Бергера — Паркера, 1/d. При этом увеличение индекса 1/d соответствует увеличению разнообразия и снижению степени доминирования одного вида. Этот индекс независим от количества видов, но на него влияет объем выборки.
1.3. Модели распределения видового обилия
Анализ распределения обилий видов является самым полным математическим описанием всей собранной по сообществу информации (Мэгарран, 1992). Имеющиеся реальные данные по видовому обилию того или иного сообщества можно описать одним или несколькими распределениями. На сегодняшний день известно большое количество математических моделей, с помощью которых можно описать видовое обилие тех или иных сообществ, но все же разнообразие чаще всего анализируется с учетом четырех основных теоретических моделей: геометрического, логарифмического (лог-ряда), логарифмически-нормального (лог-нормального) распределения и распределения, описываемого моделью «разломанного стержня» Макартура.
Каждую из моделей можно представить в виде графиков, на которых по оси абсцисс будет указан порядковый номер видов от наиболее обильных до самых немногочисленных, а по оси ординат — их обилие в логарифмической шкале (рис. 1). При этом можно увидеть переход от геометрического ряда к модели «разломанного стержня». В случае геометрического распределения доминируют немногие виды при очень низкой численности большинства, при логарифмическом и лог-нормальном распределении виды со средним обилием становятся все более и более обычными; в распределении, описываемом моделью «разломанного стержня», обилия видов распределены с максимально возможной в природе равномерностью.
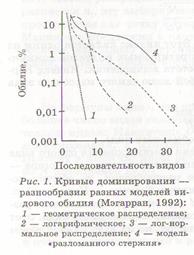 Каждой из моделей соответствует характерная кривая на графике ранг/обилие (рис. 1). Геометрическое распределение выражается прямой линией с крутым наклоном. Логарифмическое распределение также имеет крутой наклон, но это не прямая линия, а кривая. Модель «разломанного стержня» имеет более пологий график. Лог-нормальное распределение
Каждой из моделей соответствует характерная кривая на графике ранг/обилие (рис. 1). Геометрическое распределение выражается прямой линией с крутым наклоном. Логарифмическое распределение также имеет крутой наклон, но это не прямая линия, а кривая. Модель «разломанного стержня» имеет более пологий график. Лог-нормальное распределение
описывается S-образной кривой, которая располагается на графике между логарифмическим распределением и моделью «разломанного стержня».
Геометрический ряд. Данное распределение описывает ситуацию, при которой наиболее обильный вид захватывает часть k некоего ограниченного ресурса, второй по обилию вид захватывает такую же долю k остатка этого ресурса, третий по обилию — k от остатка и т. д., пока ресурс не будет разделен между всеми S видами. Если это условие выполнено и если обилия видов (выраженные, например, их биомассой, проективным покрытием или числом особей) пропорциональны используемой доле ресурса, распределение этих обилий будет описываться геометрическим рядом (или гипотезой преимущественного захвата ниши).
Модель имеет два параметра: ni — численность самого обильного вида и k — константу геометрической прогрессии. При этом обилия видов от наибольшего к наименьшему можно рассчитать с помощью формулы
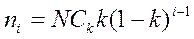 ,
,
где ni — число особей i-ro вида; N — общее число особей;
Ск = [l - (1 - k)s]-1 — константа, при которой ∑ ni = N.
Распределение обилий видов по типу геометрического ряда обнаруживается преимущественно в бедных видами местообитаниях или в сообществах на очень ранних стадиях сукцессии. Такое распределение характерно для некоторых растительных сообществ в суровых условиях окружающей среды (например, сообщество растений субальпийского пояса).
Логарифмический ряд (лог-ряд). Данное распределение, так же как и геометрический ряд, описывает ситуацию заселения биотически ненасыщенного местообитания, но в отличие от него виды проникают в сообщество не через равные, а через случайные промежутки времени. Распределение частот видов для лог-ряда описывается формулой:
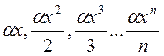 ,
,
где 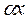 — число видов, представленных одной особью;
— число видов, представленных одной особью; 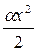 - число
- число
видов, представленных двумя особями и т. д.
Общее число видов S рассчитывается в результате сложения всех членов данного ряда, что в конечном итоге приводит к равенству:
S = S1+S2+...= -α ln(l-x).
Входящая в это уравнение константа х оценивается путем итерационного решения уравнения:
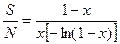 ,
,
где N — общее число особей.
На практике х почти всегда больше 0,9 и никогда не превышает 1,0. Если N/S > 20, х > 0,99.
α — это индекс лог-ряда, который можно получить из уравнения:
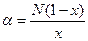
с доверительными пределами, устанавливаемыми выражением
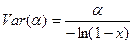 .
.
Довольно широко α используется как индекс видового разнообразия, причем он может применяться даже в том случае, если распределение обилий видов в изучаемом сообществе не подчиняется логарифмическому распределению.
Для того чтобы оценить соответствие распределения обилий особей в конкретном местообитании лог-ряду, необходимо рассчитать число видов, ожидаемое в каждом классе обилия, и сравнить его с действительно наблюдаемым. Для сравнения и оценки достоверности различий используются критерии согласия (чаще всего χ2).
Моделью логарифмического распределения, характеризующейся малым числом обильных видов и большой долей редких, с наибольшей вероятностью можно описать такие сообщества, структура которых определяется одним или немногими экологическими факторами. Так, к примеру, такому ряду соответствует распределение обилий видов растений наземного яруса в хвойных культурах в условиях низкой освещенности (Мэгарран, 1992).
Логарифмически нормальное распределение. Данный тип распределения характерен для систем, когда величина некоей переменной определяется большим числом факторов. Например, лог-нормальное распределение обилий видов характерно для больших, зрелых и разнообразных сообществ.
Эта модель впервые была применена к распределению обилий видов Престоном (Preston, 1948). При построении графика он нанес обилия видов на ось в log2-шкале и назвал получившиеся классы октавами. В случае использования логарифма по основанию 2 каждая октава будет соответствовать удвоенному обилию предыдущей, но для описания модели можно использовать любое основание логарифма. На графике распределения частот видов по полученным таким способом классам численности соответствуют известной кривой нормального распределения, усеченной слева, в области частот редких видов. Распределение обычно записывается в форме:
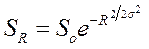 ,
,
где SR — теоретическое число видов в октаве, расположенной в R октавах от модальной октавы; S0 — число видов в модальной октаве; σ — стандартное отклонение теоретической лог-нормальной кривой, выраженное в числе октав.
Лог-нормальное распределение описывается симметричной «нормальной», т. е. колоколообразной, кривой (рис. 2.). Однако чем меньше объем выборки, на основании анализа которой строится распределение, тем больше вероятность того, что очень редкие виды, представленные небольшим числом особей, в нее не попадут. На графике это выражается в том, что левая часть кривой будет выражена нечетко, располагаясь за так называемой «линией занавеса». «Линия занавеса» сдвигается влево при увеличении объема выборки, хотя, как правило, при анализе небольших сообществ бывает выражена только часть кривой справа от моды. Только при огромном количестве данных, собранных на, обширных биогеографических территориях, прослеживается полная кривая (Мэгарран, 1992).
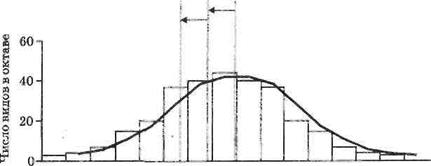
-7-6-5-4-3-2-10 1 2 3 4 5 6 7
Октавы
Рис. 2. Лог-нормальное распределение. Стрелками обозначен сдвиг «линии занавеса» при увеличении объема выборки
Распределение по модели «разломанного стержня» Макартура. Эту модель иногда называют гипотезой случайной границы ниши. S видов разделяют среду случайно между собой так, что занимают неперекрывающиеся ниши. При этом число особей каждого вида пропорционально размеру (ширине) ниши. Такое разделение пространства ниши в пределах сообщества можно образно сравнить со случайным и одновременным разламыванием стержня на S кусков.
Эта модель рассматривает только один ресурс. Она отражает более равномерное его разделение, чем лог-нормальная модель, логарифмическая и геометрическая модели. Модель «разломанного стержня» характеризуется только одним параметром S (числом видов) и сильно зависит от объема выборки.
Число особей в i-м классе по порядку обилия среди S видов (Ni) получают по формуле

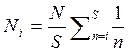 ,
,
где N - общее число особей; S — общее число видов.
Эту модель можно выразить также в величинах стандартного распределения обилий видов:
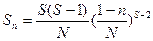 ,
,
где S(n) — число видов в классе обилия с п особями.
Как и в рассмотренных выше случаях лог-ряда и лог-нормального распределения, для сравнения ожидаемых и наблюдаемых частот классов обилия используют критерии согласия.
Модель Макартура предполагает, что пространство ниш поделено на случайные, соприкасающиеся, но неперекрывающиеся участки. Такое распределение характерно для сообществ с интенсивной межвидовой конкуренцией, территориальным поведением. Лучше всего использовать модель «разломанного стержня» для доказательства большей выравненности обилий видов в определенном сообществе.