Индексы видового богатства и видового разнообразия очень широко применяются в ботанических, зоологических и экологических исследованиях. Они позволяют:
• дать оценку разнообразия;
• обнаружить воздействие факторов, влияющих на него;
• оценить и измерить направление изменений разнообразия под влиянием тех или иных условий;
• сравнить разнообразие различных местообитаний;
• обнаружить границу ассоциации видов или сообщества;
• оценить видовое богатство.
В то же время довольно часто индексы используются неправильно, впустую, для того чтобы получить цифры ради самих цифр и придать проделанной работе большую наукообразность. Это происходит в основном по следующим причинам.
1. Использование только одного индекса (богатства, разнообразия, выравненности) без параллельных сведений о поведении индексов других типов. При этом информативность индекса может еще больше снижаться в том случае, если не указывается объем выборки, степень ее приближения к генеральной совокупности. Например, по двум выборкам либо из разных местообитаний, либо взятым в разное время из одного места, получены меньшее и большее значения индекса Шеннона. Различия в величине данного индекса могут быть следствием либо увеличения числа видов, либо выравнивания соотношения числа видов, происходящего вследствие снижения численности сверхдоминанта, либо роста численности видов со средним обилием. Отсутствие в данном случае дополнительных сведений о размерах выборок, числе видов в них, выравненности видов лишает индекс Шеннона информационного содержания.
2. Расчет индексов по объединенным выборкам разного содержания. Например, когда при изучении сукцессии сравниваются выборки, полученные в течение длительного времени, соизмеримого с временем протекания разных стадий сукцессии. При
этом может происходить объединение тенденций, связанных с
разными стадиями сукцессии, и сопровождающими эти стадии
разными группировками видов, каждая из которых проходит
свой цикл формирования, используя разные микрониши.
3. Применение индексов для сравнения частей целостных выборок. Примером такого некорректного использования индексов
Индекс Жаккара. Является отношением числа общих видов к числу видов в объединенном списке.
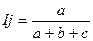 |
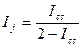
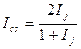 Это один из наиболее старых и широко используемых индексов. Он легко может быть трансформирован в индекс Чекановского — Съеренсена:
Это один из наиболее старых и широко используемых индексов. Он легко может быть трансформирован в индекс Чекановского — Съеренсена:
.
Так же, как и индекс Чекановского — Съеренсена, индекс Жаккара изменяется от 0 при отсутствии общих видов до 1 в случае полного совпадения видового состава изучаемых сообществ.
Индекс Кулъчинского. Это отношение числа общих видов к среднему гармоническому числу видов в двух списках:
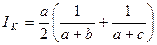 |
Индекс изменяется от 0 при отсутствии общих видов до 1 при полном совпадении сравниваемых сообществ.
Индекс Охиаи — Баркмана. Является отношением числа общих видов к среднему геометрическому числу видов в двух списках.
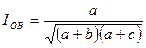
Индекс изменяется от 0 при отсутствии общих видов до 1 при полном совпадении сравниваемых сообществ.
Индекс Сокала — Снита. Представляет собой отношение числа общих видов к сумме числа видов в общем списке и числа необщих видов:
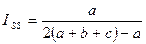 |
Индекс изменяется от 0 при отсутствии общих видов до 1 при полном совпадении сравниваемых сообществ.
К особенностям индекса Сокала — Снита следует отнести то, что он имеет сильно нелинейную связь с мерой абсолютного сходства. В связи с этим его применение может быть предпочтительным в том случае, если имеется высокий уровень сходства анализируемой группы списков. В этом случае для более точного выяснения взаимоотношений необходим индекс с повышенной чувствительностью к незначительным изменениям абсолютного сходства в области его наибольших значений. Из широко распространенных индексов индекс Сокала — Снита удовлетворяет этому требованию в наибольшей степени (чуть меньше — индекс Жаккара).
Индекс Стугрена — Радулеску. Является дополнением к удвоенному индексу Жаккара:
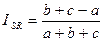 |
Данный индекс имеет интервал значений от -1 при идентичности списков до +1 при отсутствии в них общих видов.
Он легко может быть трансформирован в индекс Чекановского — Съеренсена и в индекс Жаккара:
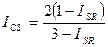 | |||
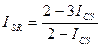 | |||
;
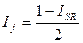 |
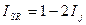 ;.
;.
Индексы общности, учитывающие негативные совпадения.
Данная группа индексов, помимо положительного совпадения признаков, включает также информацию и о так называемом отрицательном совпадении, т. е. о тех видах, которые отсутствуют в обоих сравниваемых списках, но имеются в других списках, входящих в анализируемую совокупность. Наиболее широко применяются индекс Сокала — Майченера, а также индекс Ба-рони — Урбани и Бюссера.
Индекс Сокала — Майченера. Этот индекс, иначе называемый коэффициентом простого совпадения, представляет собой отношение числа общих и необщих видов к общему числу видов в анализируемой совокупности списков:
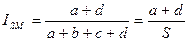 |
Индекс изменяется от 0 в случае отсутствия как положительных, так и отрицательных совпадений видов в анализируемых списках (а = d = 0) до 1 при полном положительном совпадении сравниваемых списков.
Индекс Барони — Урбани и Бюссера. Отличается от индекса Сокала — Майченера способом введения в индекс отрицательных совпадений:
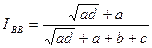 |
Индекс изменяется от 0 в случае отсутствия как положительных, так и отрицательных совпадений (а = d - 0) до 1 в случае отсутствия уникальных видов (b = с = 0). Максимальное значение индекса может быть получено и при отсутствии, и при наличии отрицательных совпадений.
К использованию индексов, учитывающих отрицательные совпадения, следует относиться с известной осторожностью. Они очень чувствительны к редким видам, которые могут не попасть в выборку. При этом следует учитывать, что вид может не попасть в выборку по нескольким причинам:
1) вид встречается на изучаемой территории, но отсутствует в данном местообитании в силу того, что здесь отсутствуют подходящие условия для его существования;
2) вид может отсутствовать в данном местообитании по целому ряду как исторических, так и географических причин;
3) вид присутствует в данном местообитании, но в силу своей низкой встречаемости или из-за неадекватности использованных методов выявления видового состава не попал в выборку.
Отсутствие вида как результат первых двух причин несет очень ценную информацию о видовом составе изучаемой территории и местообитаний, но только в том случае, если будет исключена третья причина, что сделать, как правило, невозможно (Песенко, 1982).
Индексы общности, основанные на количественных данных. Зачастую, помимо информации о наличии или отсутствии видов, исследователь имеет возможность оценить и их количественное участие в формировании структуры изучаемых сообществ. Параметры оценки могут быть разными: число особей каждого вида, биомасса, проективное покрытие, балл обилия по каждому виду и др. В любом случае это важные показатели, несущие ценную информацию о составе и структуре анализируемых сообществ, и не использовать их — значит потерять большой объем информации. Для того чтобы при сравнении сообществ избежать подобной потери информации, используют индексы общности, учитывающие количественные данные.
На сегодняшний день предложено большое число формул для вычисления сходства между списками видов по количественным данным. Согласно Песенко (1982), все разнообразие индексов можно свести к шести формам расширения основных индексов общности, учитывающих только качественные данные. Из них наиболее часто используются и имеют наиболее простое математическое и биологическое объяснение расширения индекса Чекановского — Съеренсена, основанные на пересечении выборок и пересечении структуры сравниваемых выборок.
Количественный индекс Чекановского — Съеренсена, основанный на пересечении выборок. Имеет следующую форму:
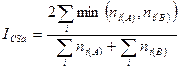 |
,
где 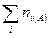 — общее число особей (биомасса, проективное покрытие и др.) на первом из сравниваемых участков;
— общее число особей (биомасса, проективное покрытие и др.) на первом из сравниваемых участков; 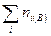 — общее число особей (биомасса, проективное покрытие и др.) на втором участке;
— общее число особей (биомасса, проективное покрытие и др.) на втором участке; 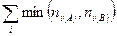 — сумма наименьших из двух обилий видов, встреченных на обоих участках.
— сумма наименьших из двух обилий видов, встреченных на обоих участках.
Данный индекс чувствителен к различиям в объеме сравниваемых выборок, поэтому он должен использоваться только в том случае, если это различие является существенным при оценке степени сходства сравниваемых сообществ.
Для балльных оценок имеется следующая модификация этого индекса:
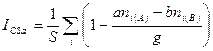 |
,
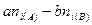 |
где S — число видов; — абсолютное различие в
обилии i-гo вида между списками А и В, выраженное в баллах по g-балльной шкале.
Данные индексы принимают значения от 0 при отсутствии общих видов в сравниваемых сообществах до 1 при полном совпадении сравниваемых сообществ по видовому составу и количественным показателям 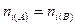 .
.
Количественный индекс Чекановского — Съеренсена, основанный на пересечении структуры выборок. Применяется, когда необходимо исключить влияние различий в объеме сравниваемых выборок и вычислить разницу не между численностями каждого вида, а между их долями в выборках. В этом случае будет определяться пересечение не самих выборок, а их структуры:
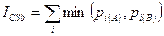 |
Максимум индекса, равный 1, достигается при равенстве долей обилия для каждого i-го вида из S, входящих в сравниваемые выборки. Минимальное значение индекса, равное 0, получается в том случае, если в сравниваемых сообществах нет общих видов.
В том случае, если анализируемые выборки имеют одинаковый объем, ICSa и ICSb дают одинаковые оценки общности. Различия между этими индексами тем больше, чем сильнее различается объем сравниваемых выборок. Например, в том случае, если сравниваются две выборки, имеющие идентичный видовой состав и количественные соотношения между видами, но одна из выборок имеет в два раза больший объем, ICSb = 1, тогда как
Isa= 0,67.
Меры включения
Для того чтобы корректно использовать симметричные меры сходства для сравнения между собой разновеликих выборок, необходимо провести математическую нормировку списков (чаще всего путем приведения исходных данных к долям единицы или процентам). Это связано с тем, что только установление единого масштаба для сравниваемых разновеликих объектов позволяет определить степень сходства между ними. Вместе с тем любое математическое нормирование приводит к потере части информации о признаках и свойствах сравниваемых объектов и не раскрывает в полной мере отношения и связи между ними.
Этого недостатка лишена группа несимметричных мер, называемых мерами включения. Меры включения впервые предложены в 1968 г. Юрцевым для сравнения разновеликих по числу видов флор, а в дальнейшем их математические свойства были детально изучены Семкиным. В символах таблицы кросс-табуляции меры включения для качественных данных можно записать в следующем виде:
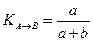 | |||
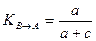 |
где КA→B — мера включения сообщества А в сообщество В;
КB→A — мера включения сообщества В в сообщество А; а + Ь —
число видов в сообществе А; а+с — число видов в сообществе В;
с — число общих для двух сравниваемых сообществ видов.
Меры включения имеют диапазон варьирования от 0 при отсутствии в сравниваемых списках общих видов до 1 в том случае, если включаемое сообщество не будет иметь характерных только для него видов.
Интерпретация данных показателей с биологической точки зрения довольно проста. Сообщества включаются друг в друга тем больше, чем больше у них общих видов. То сообщество (флора, фауна), которое при этом будет иметь большее число характерных только для него видов, будет в меньшей степени включаться в то, у которого характерных видов меньше, поэтому его можно рассматривать как более «оригинальное», «экзотичное» по отношению к более бедному характерными видами. И наоборот, то сообщество, мера включения которого во второе более высока, может рассматриваться как более «банальное», имеющее меньшее число специфических черт. Крайним случаем «банальности» будет полное включение видового состава одного сообщества в видовой состав другого.
Данная формула хотя и выглядит громоздкой, но вычисления по ней не очень трудоемки, так как суммы встречаемости видов и суммы квадратов их встречаемости вычисляются для каждой выборки только один раз. Диапазон возможных значений данного индекса, как и всех коэффициентов корреляции, заключен в пределах от -1 при полной уникальности видового состава выборки относительно остальных выборок сравниваемой совокупности до +1 в том случае, если сравниваемая выборка включает только виды, имеющиеся во всех остальных выборках группы.