В значительной мере на качество результатов исследования влияет статистическая обработка данных. Но в зависимости от цели и задач исследования устанавливают принцип отбора данных. Очень важно принять решение о проведении исследования по всей генеральной совокупности или по выборке из нее. Если не будет обеспечено необходимое количество статистических данных, то следует возвратиться к постановке задачи. Необходимо составить детальный план сбора исходной информации с учетом полной схемы статистического анализа.
Иногда задача ставиться в упрощенном виде, где исследуется влияние одного фактора на результирующий признак, а потом добавляются последовательно другие факторы. Отбор факторов, оказывающих наиболее существенное влияние на результативный признак, проводится на основе исследования связности (тесноты, силы, строгости, интенсивности) двух и более явлений.
Рассмотрим пример зависимости производительности труда (у) от уровня механизации работ (х) по данным 14 промышленных предприятий.
Таблица 4.1
| Предприятие | Производи- тельность труда | Коэффициент механизации (%) |
| i | yi | xi |
Построим корреляционное поле, чтобы определить тенденцию изменения зависимой переменной в зависимости от фактора (хi - уровень механизации).
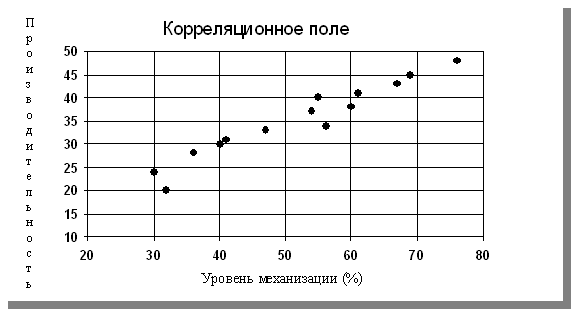
Рис. 4.1
Скопление точек определяет в некотором смысле зависимость двух переменных. Систематизация опытного материала в виде диаграммы дает возможность высказать гипотезу о зависимости переменных. В примере эта тенденция имеет явно линейный характер, поэтому естественно аппроксимировать рассматриваемую зависимость линейной функцией регрессии.
Формально коэффициенты корреляции могут быть вычислены для любой двухмерной системы наблюдений. Они являются измерителями степени тесноты линейной статистической связи между анализируемыми признаками. Однако только в случае совместной нормальной распределенности исследуемых величин коэффициент корреляции имеет четкий смысл как характеристика степени тесноты связи между ними. В остальных случаях коэффициент корреляции можно использовать в качестве одной из возможных характеристик.
Введем исходные данные в ЭВМ и получим статистическое описание исходных совокупностей (табл. 4.2). Аспекты реализации обработки экономической информации на ЭВМ здесь не рассматриваются, так как к настоящему времени накоплен достаточный опыт по программному обеспечению прикладной математической статистики и можно использовать любой пакет прикладных программ.
Таблица 4.2
| Описательная статистика | yi | xi |
| Среднее | 35.14286 | 51.71429 |
| Стандартная ошибка | 2.158187 | 3.846546 |
| Медиана | 35.5 | 54.5 |
| Стандартное отклонение | 8.075196 | 14.39246 |
| Дисперсия выборки | 65.20879 | 207.1429 |
| Эксцесс | -0.55977 | -1.07092 |
| Асимметричность | -0.25996 | -0.00504 |
| Интервал | ||
| Минимум | ||
| Максимум | ||
| Сумма | ||
| Счет | ||
| Наибольший(1) | ||
| Наименьший(1) | ||
| Уровень надежности(95%) | 4.229962 | 7.539081 |
По результатам вычислений характеристик выборочных наблюдений можно делать вывод о соответствующих параметрах генеральной совокупности.
Теперь вычислим параметры линейной регрессии и получим уравнение:
 = 0.5435x + 7.0361
= 0.5435x + 7.0361
Нанесем уравнение линейной регрессии на корреляционное поле
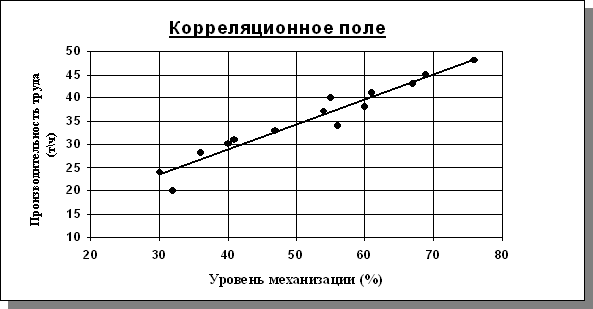
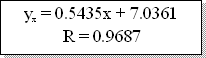
Рис. 4.2
В качестве характеристики точности оценки регрессии или степени согласованности расчетных значений найдем значения регрессии в точках хi. и определим остатки.
Таблиц № 4.3.
| Предприятие | Производи- тельность труда | Производи- тельность труда | Остатки yi - yi^ |
| i | yi^ | yi | |
| 24.753 | -4.753 | ||
| 23.666 | 0.334 | ||
| 26.927 | 1.073 | ||
| 29.101 | 0.899 | ||
| 29.6445 | 1.3555 | ||
| 32.9055 | 0.0945 | ||
| 37.797 | -3.797 | ||
| 36.71 | 0.29 | ||
| 39.971 | -1.971 | ||
| 37.2535 | 2.7465 | ||
| 40.5145 | 0.4855 | ||
| 43.7755 | -0.7755 | ||
| 44.8625 | 0.1375 | ||
| 48.667 | -0.667 |
Рассматривая остатки как отклонения i-х наблюдений от значений, которые следует ожидать в среднем, можно сделать ряд практических выводов, например, провести дополнительные исследования по предприятиям 1,3,5,7,9,10.