Самостоятельная работа № 3
Окно «Вывод»
В окне «Вывод» выводится список последних 12 команд, которые использовали. Благодаря этой функции не нужно каждый раз заходить в анализ описательной статистики.
В нашем случае зашли в меню «Анализ» и попытались вывести анализ по частотам, что и отразилось в истории операций в окне «Вывод».
Алгоритм построения частотных таблиц и таблиц сопряженности
Частотные таблицы
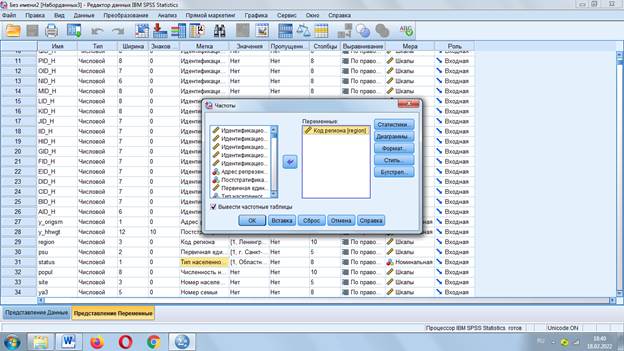
Заходим в меню «Анализ» - «Описательные статистки» - «Частоты» - «Статистики»
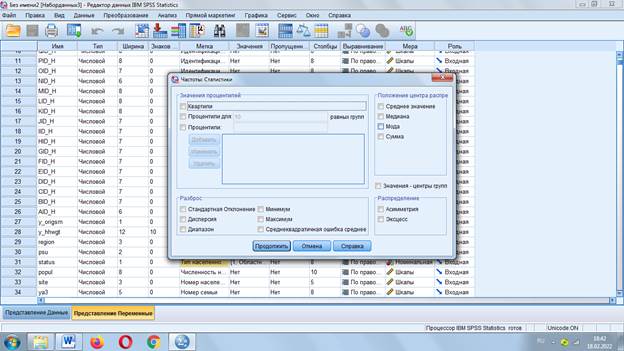
Выводится статистика (показывает самые основные вещи – сколько респондентов ответило и пропустило вопрос), затем - запрашиваемые данные (распределение по регионам).

Процент допустимых - пересчет процентного соотношения без учета тех респондентов, кто пропустил вопрос.
Накопленный процент включает сумму двух предыдущих ответов.
Такие таблицы подходят для разных типов шкал: номинальной, метрической, порядковой.
Таблицы сопряженности
Выводятся: «Анализ» - «Описательные статистики» - «Таблицы сопряженности»

Показывают распределение ответа по группам.
Выбираем строки: «Тип населенного пункта», а в столбцы «Количество членов семьи».
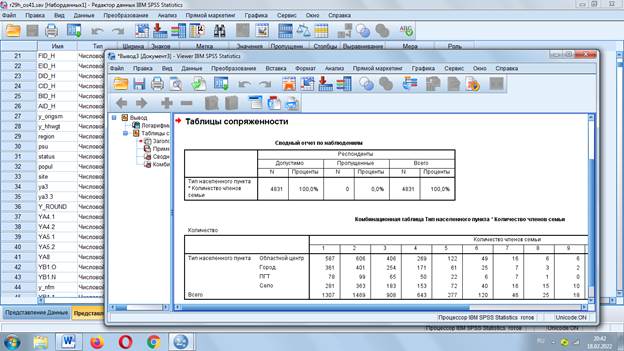
Данные выведены в абсолютных частотах, но можно сделать и в процентах.
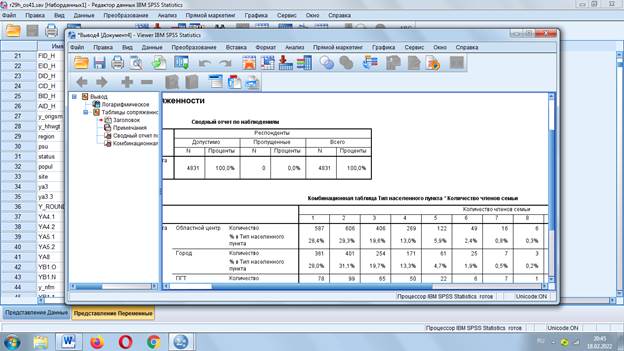
Теперь можно сравнивать сколько членов семьи в каждом типе поселения.
Алгоритм построения частотных таблиц и таблиц сопряженности для вопросов со множественными ответами.
Частотные таблицы
В меню анализа данных можно поменять отражение вопросов: по меткам или именам. Поменяли на имена.
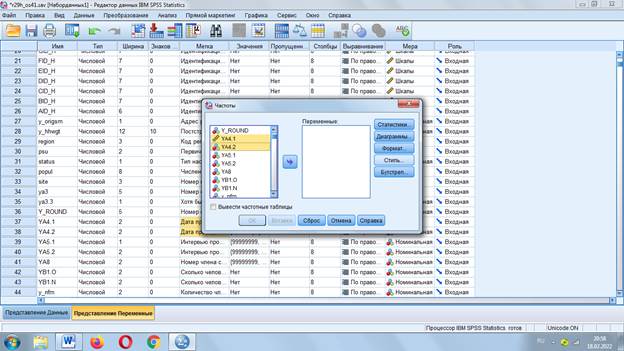
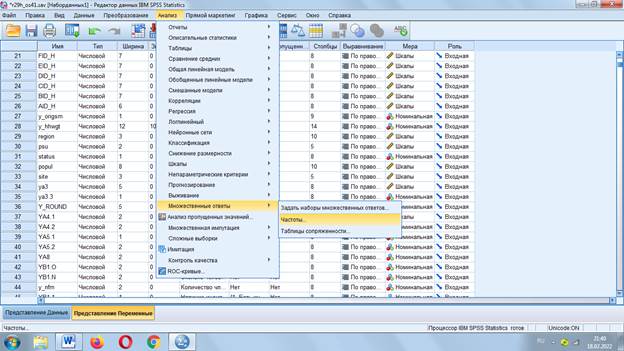
Вывод таблиц: «Анализ» - «Множественные ответы»
Нужно задать наборы множественных ответов
Дихотомии – ответы из 2 символов (выбрано – не выбрано)
В «Подсчитываемое значение» ставим «1», т.е. выбранный ответ.
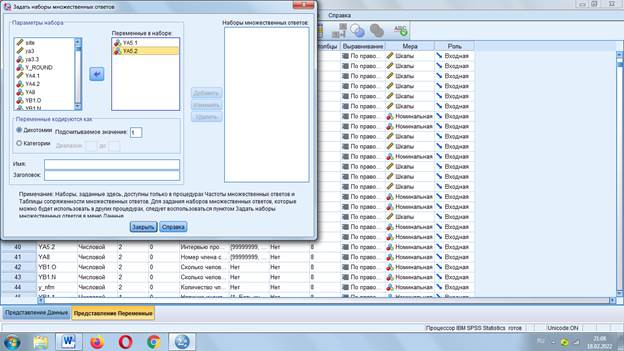
«Категории» подходят для вопросов, в которых ответы предполагают определить степень (Насколько вы согласны…?).
Даем имя и заголовок набору
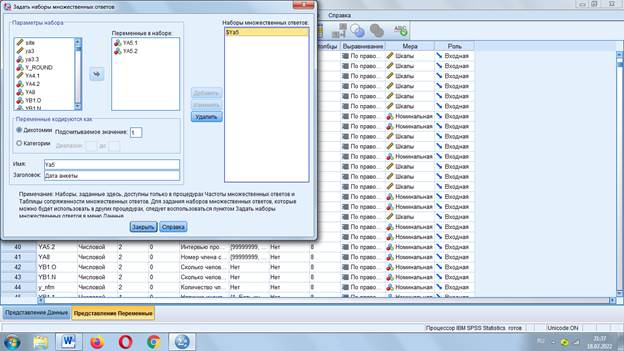
Набор храниться только в оперативной памяти.
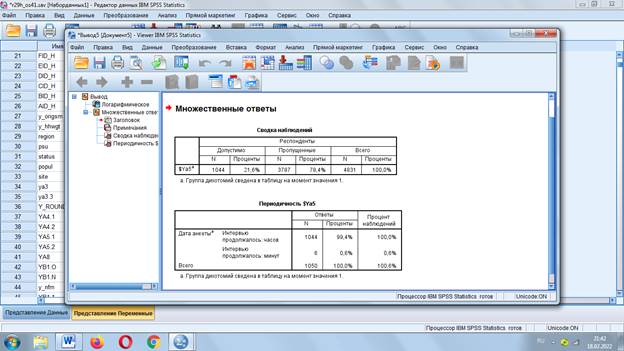
Затем закрываем набор и повторяем: «Анализ» - «Множественные ответы» и добавляем «Частоты» (активировались после создания набора)
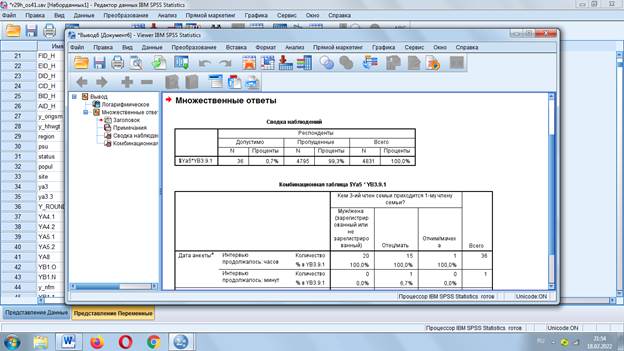
Сформировалась таблица:
Таблицы сопряженности
Также как для частотных таблиц создается набор: «Анализ» - «Множественные ответы» - «Таблица сопряженности»
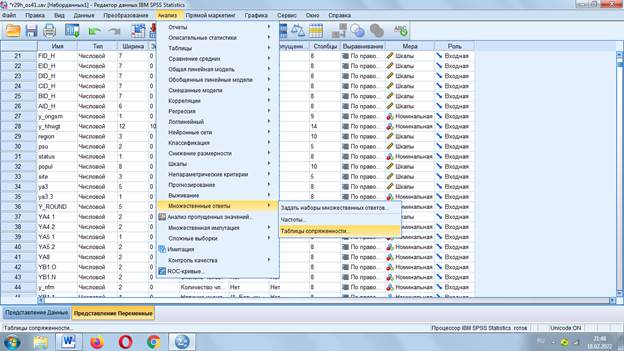
Помещаем в строкинабор и выбираем вопрос для столбца
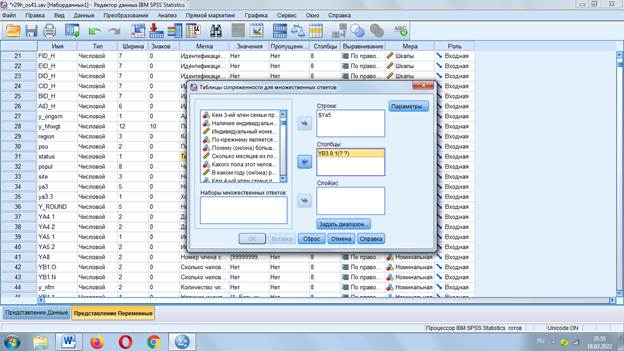
Задаем параметры от 1 до 3 и получаем результат
4 Статистики для частотного анализа:
Частотное распределение переменной - соответствие между значениями переменной и их количеством в выборке.
Положение центра распределения
Среднее значение - сумма всех значений переменной, деленная на количество значений.
Определяется математически выполнимым алгебраическим выражением. Искажается выбросами.
Для чего применяется: понять наиболее эффективное решение. Например, решить какая публикация получила наибольший охват. Для этого необходимо сложить все охваты первой публикации за определенный период, например за неделю, и поделить на количество дней в неделю.
(R1+R2+R3+R4+R5+R6+R7)/7 = Rmedium
То же самое сделать с другими публикациями. Сравнить получившиеся значения.
Медиана - значение, которое делит его распределение пополам. Можно использовать только для количественных и порядковых переменных, но не номинальных. Не искажается выбросами, но игнорирует большую часть информации.
Формула:
М= (N(число признаков) +1)/2
Мода - наиболее часто встречающееся значение, применяется для количественных, ранговых и качественных переменных.
Характеризует центральную тенденцию. В случае с охватами мода будет индикатором основного количества прочтений/охвата публикации. Максимально частое значение охвата/прочтений – мода.
Например: понедельник - охват 1 млн, вторник -1,5 млн, среда - 0,9 млн, четверг - 0,5 млн, суббота - 1 млн, воскресенье - 1 млн.
Мода будет 1 млн.