ПЛАНИРОВАНИЕ ПУТЕЙ С ЭЛЕМЕНТАМИ СЛУЧАЙНОСТИ ДЛЯ МНОГОШАРНИРНЫХ МАНИПУЛЯТОРОВ БЕЗ ИСПОЛЬЗОВАНИЯ ОБРАТНОЙ КИНЕМАТИКИ
RANDOMIZED PATH PLANNING FOR REDUNDANT MANIPULATORS
WITHOUT INVERSE KINEMATICS
Mike Vande Weghe (Institute for Complex Engineered Systems, CMU)
Dave Ferguson, Siddhartha S. Srinivasa (Intel Research Pittsburgh)
АННОТАЦИЯ
Мы представляем алгоритм планирования пути, основанный на выборках, способный эффективно генерировать решения для многомерных задач манипулятора, включая задачи, связанные с обратной кинематикой и сложными препятствиями. Наш алгоритм расширяет Быстро-исследующее Случайное Дерево (RRT), чтобы справляться с целями, определёнными в подпространстве конфигурационного пространства манипулятора, в котором растёт поисковое дерево. При планировании действий рукой естественно появляются недостаточно определённые цели, когда конечная позиция рабочего органа критично важна, а конфигурация всей остальной части манипулятора – нет. Для осуществления чего, алгоритм запускает оптимальный локальный оператор, основанный на преобразовании Якобиана, для глобального поиска по RRT. Подход в результате известен, как Быстро-исследующие Случайные Деревья в направлении преобразования Якобиана (JT-RRTs), которые способны комбинировать исследование деревьями пространства конфигураций со смещениями к цели в рабочем пространстве для того, чтобы создавать прямые пути через сложную среду крайне эффективно, без необходимости иметь какую бы то ни было кинематику. Мы сравнили наш алгоритм с недавно разработанным соревновательным подходом и предоставим результаты как для симуляции, так и для робототехнической руки с семью степенями свободы.
I. ВВЕДЕНИЕ
В реальной внешней среде робототехнической системе сложно планировать пути. Такие системы должны иметь дело не только со стандартными задачами планирования в потенциально многомерных и сложных пространствах поиска, но они также должны справляться с несовершенной информацией относительно их окружения и, возможно, их задач, динамической среды и ограничений на время размышления. Поскольку при генерации решений алгоритмы планирования, которые используются этими системами, должны быть крайне эффективны настолько, что должны быть быстро выполнены, пока решения продолжают быть пригодными.
Ответом на эти требования исследователи разработали алгоритмы, основанные на выборке образцов, которые быстро создают решения в очень многомерных пространствах. Один из наиболее широко используемых алгоритмов – это Быстро-исследующее Случайное Дерево (RRT) [1]. Этот алгоритм выращивает дерево поиска из начальной позиции в поисковом пространстве (начальная конфигурация), при чём использует в этом пространстве случайный выбор смещений роста дерева в направлении неисследованных регионов. Следовательно, дерево исследует пространство чрезвычайно эффективно. Т.к. для роста дерева используется случайность, алгоритм хорошо справляется, как с очень многомерными пространствами, так и с очень большим числом факторов ветвления. Далее, RRT может смещать поиск в направлении редких целевых конфигураций, которые значительно улучшают эффективность вычисления решений в данной задачи планирования.
Рис. 1. Цельная Манипуляторная Рука (WAM) Баррета.
Из-за возможности решать очень сложные многомерные задачи планирования и относительную лёгкость реализации, RRT-вья используются в громадном множестве сценариев планирования движений [1], [2], [3], [4], [5]. В частности, они использовались и в планировании манипулирования для многомерного случая [6], который сейчас в центре нашего внимания. В данном сценарии целью является создание траекторий для манипулятора, чтобы переместить его из некоторой начальной конфигурации к желаемой цели. Однако, в противоположность многим другим областям применения RRT, цель планирования манипулятора обычно является не определена, как просто желаемая конфигурация сочленения, но скорее, как желаемое местоположение рабочего органа руки внутри рабочего пространства. Например, если мы пытаемся решить задачу хватания, в которой мы хотим, чтобы наша робототехническая рука подняла чашку для нас из раковины, мы пытаемся понять, как действия руки (рабочего органа) по осуществлению конкретного контакта с чашкой может быть спланированы. К сожалению, если мы имеем дело с многошарнирным манипулятором, то цель рабочего органа в рабочем пространстве зависит от потенциального бесконечного числа целей в конфигурационном пространстве манипулятора. Тогда не существует аналитического решения для отображения цели из рабочего пространства в цель(-и) в пространстве конфигураций для сложных манипуляторов.

Рис.2. Многошарнирные манипуляторы могут иметь бесконечное количество конфигураций, соответствующих одной и той же позиции рабочего органа в пространстве. Рисунки от (a) до (c) показывают три таки конфигурации WAM.
В результате обычный алгоритм RRT ожидаемо не работает достаточно хорошо в данной области. Вместо этого, разработаны другие подходы, которые полностью предназначены для решения сложной задачи обратной кинематики. Тем не менее, все эти подходы имеют свои ограничения, которые мы обсудим в последующей секции.
В данном исследовании мы представляем расширение алгоритма RRT, который может одолеть задачу обратной кинематики с помощью исследования природы Якобиана, как преобразования из конфигурационного пространства в рабочее пространство робота. Результирующий алгоритм способен обуздать мощь RRT для исследования сильно многомерных пространств, в то время также концентрируя свой поиск непосредственно на желаемой цели внутри рабочего пространства.
Мы начнём обсуждение обратной кинематической задачи для проблемы планирования пути многошарнирного манипулятора и опишем существующие алгоритмы планирования, которые стараются справляться с этой проблемой. В частности, мы обсудим недавний алгоритм Бертрама и ко. [6], который произвёл отличную работу по расширению алгоритма RRT, позволив алгоритму оперировать без необходимости решения обратной задачи кинематики манипулятора. Затем мы опишем аналитический метод выявления траектории в конфигурационном пространстве, которая приводит путь в рабочем пространстве. Мы используем этот метод для разработки алгоритма, основанного на RRT, который может эффективно концентрировать свой поиск непосредственно к цели, указанной в рабочем пространстве, во то время как исследование конфигурационного пространства робота продолжается. Мы предоставим несколько результатов сравнения нашего алгоритма с текущем положением дел в искусстве планирования и проиллюстрируем его эффективность как в симуляции, так и на физической руке-манипуляторе с семью степенями свободы.
II. ПЛАНИРОВАНИЕ ДЛЯ МНОГОШАРНИРНОГО МАНИПУЛЯТОРА
Стандартная задача планирования пути может быть сформулирована, как поиск пути от некоторой начальной конфигурации qstart системы к некоторой желаемой конфигурации qgoal. Конфигурационное пространство, внутри которого ищется этот путь для представленного множества всех возможных состояний или перестановок системы. При манипулировании роботами, где мы имеем робототехническую систему, составленную из нескольких перемычек, соединённых друг с другом с помощью различных сочленений (см. рис. 1 для примера такого робота), конфигурационное пространство соответствует всем различным фигурам, которые рука может описывать внутри пространства. Каждая из этих фигур сформирована уникальным множеством углов сочленений (и/или смещениями для призматических сочленений робота), и, следовательно, конфигурационное пространство экспоненциальным образом зависит от числа сочленений, составляющих манипулятор. В таких случаях конфигурация системы есть множество углов сочленений для конкретной фигуры.
Из-за того, что пространство конфигураций манипулятора с несколькими сочленениями может быть чрезвычайно громадным и многомерным, классические техники планирования пути, основанные на дискретизации пространства конфигураций, а затем на детерминированном поиске внутри этого пространства (т.е. поиск Дейкстры [7] или A* [8]), обычно слишком далеки от оптимума как по памяти, так и по интенсивности вычислений при генерации решений для задач планирования пути манипулятора. Вместо этого, техники планирования, основанные на выборках, показали себя подходящими очень хорошо для этого класса проблем планирования. Возможно, наиболее популярным алгоритмом, основанным на выборках, в робототехнике является алгоритм Быстро-исследующего Случайного Дерева (RRT) [1].
RRT-вья ищут пути через конфигурационное пространство, выращивая дерево поиска из начальной конфигурации qstart и пытаясь соединить это дерево с целевой конфигурацией qgoal. Чтобы сделать это, они случайно выбирают точки в целом пространстве конфигураций и, затем пробуют расширить дерево поиска к этим точкам. В результате рост дерева стремится в направлении ранее непосещённых регионов конфигурационного пространства и исследование происходит очень быстро.
Как предполагалось ранее, они могут также быть выполнены намного более эффективно с помощью концентрирования их роста более направленно в сторону цели. Чтобы сделать это скорее, чем случайными выборками точек при расширении далее на каждой итерации алгоритма, они время от времени (с некоторой вероятностью pg) выбирают целевые конфигурации, как точки направления дальнейшего расширения дерева. Это создаёт эффект вытягивания дерева в направлении к цели и обычно решения получаются со значительно меньшей сложностью вычислений. Это притяжение к цели – очень важное свойство RRT, т.к. оно улучшает шансы достижения цели в пределах желаемого допуска без необходимости изучать всё пространство конфигураций с данной точностью.

Рис. 3. Преобразование Якобиана производит отображение из пространства сочленения в рабочее пространство так, что позволяет манипулятору примерно прослеживать путь в рабочем пространстве. Это отображение может быть использовано для расширения нашего дерева поиска в конфигурационном пространстве в направлении к цели, определённой в рабочем пространстве.
Для большинства задач планирования путей в робототехнике, вычисление желаемой целевой конфигурации qgoal происходит напрямую: мы знаем где мы бы хотели, чтобы робототехническая система остановилась, и мы можем понять где соответствующее местоположение находится в конфигурационном пространстве робота. Однако, когда мы имеем дело с многошарнирными манипуляторами такими, как наша семи связная рука-робот, вычисление отображения из рабочего пространства в пространство сочленения, известное как обратная кинематическая задача манипулятора, чрезвычайно трудное. На самом деле, для манипуляторов с числом звеньев большим чем 6, нет аналитического решения этой проблемы [9], и даже для манипулятора с шестью или меньшим число звеньев может найтись бесконечное число состояний конфигурационного пространства, результатом которых будет одно состояние рабочего пространства.
Исследователи изучили разные способы преодоления данной проблемы. Классически большинство общих подходов используют численное приближение для вычисления решения обратной кинематической задачи (IK) [10]. Однако, как описано в [6], эти подходы могут перестать сходиться к правильному решению и обычно ограничены нахождением только одного из потенциально бесконечного числа решений. Это может быть особенно неблагоприятно при планировании манипулятором в среде, содержащей препятствия, потому что, вероятно, отдельная цель в пространстве конфигураций, которая выбрана, может быть недостижима. Даже если не представлено никаких препятствий, эта цель может всё ещё быть неосуществимой из-за пределов движения механизма.
Чтобы побороть ограничения этих численных техник, основанных на приближении, Бертрам и ко. [6] разработали изящное расширение алгоритма RRT, которое убирает необходимость решения задачи обратной кинематики и может обрабатывать цели для рабочего органа, определённые в рабочем пространстве манипулятора. В их подходе предпочтительнее выбора целевой конфигурации, как эталонной точки для дальнейшего расширения дерева (с некоторой вероятностью pg), выбирается конфигурация в дереве поиска, ближайшая к цели в рабочем пространстве с помощью метрики расстояния рабочего пространства робота, затем из этой конфигурации дерево расширяется в случайном направлении. Этот алгоритм имеет несколько замечательных свойств относительно численных приближений задачи IK и стандартного RRT подхода. Во-первых, нет необходимости в явно выведенной обратной кинематике для планирования. Во-вторых, все конфигурации, достигнутые в течение поиска - допустимы, это значит нет проблемы планирования для недопустимых целевых конфигураций, основанных на неточной обратной кинематике. Наконец, благодаря влиянию целей в рабочем пространстве на рост дерева, сходимость обычно происходит намного быстрее, чем у простого алгоритма RRT.
Алгоритм, который мы представим в последующих секциях, разделяет ту же мотивацию, что и алгоритм Бертрама и ко., а именно он нацелен на устранение необходимости явного решения задачи обратной кинематики без жертв эффективности итогового процесса планирования. Однако, наш подход пытается эксплуатировать цели рабочего пространства даже ещё сильнее, чтобы улучшить сходимость. И, предпочтительнее случайного расширения дерева поиска из вершины, ближайшей к цели в рабочем пространстве, вычисляется лучшее расширение из этой вершины в направлении к цели. В следующей секции мы опишем как это расширение может быть вычислено.
III. ЭКСПЛУАТАЦИЯ ЯКОБИАНА
Пусть данная конфигурация руки робота q ∈ Q, а желаемая целевая позиция рабочего органа xg ∈ X, где X есть пространство R3 (или SE(3)) позиций рабочего органа манипулятора, мы заинтересованы в вычислении расширения конфигурационного пространства от q к xg. К сожалению, отображение из Q в X обычно нелинейное и очень дорого для вычисления. Тем не менее, производная этого отображения называется Якобиан – это есть линейное отображение из касательного пространства для Q к такому же для X, оно обозначается 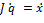 , где x ∈ X есть позиция рабочего органа соответствующая q, и она может быть вычислена быстро.
, где x ∈ X есть позиция рабочего органа соответствующая q, и она может быть вычислена быстро.
В идеале, для того, чтобы подвести рабочий орган к желаемой конфигурации xg, мы могли бы вычислить ошибку e = (xg − x) и запускать оператор в форме 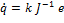 , где k есть положительный прирост. В отсутствии каких бы то ни было препятствий, внутренних столкновений или ограничений сочленений, этот отдельный оператор гарантированно достигает цели. К сожалению, при отсутствии аналитического решения, вычисление обратного Якобиана должно быть произведено численно в каждый такт времени. Есть несколько численных методов, предложенных для вычисления обратного преобразования, в диапазоне от эффективных техник координатного спуска [11], [12], [13], [14] до функций-аппроксимаций, изучающих приближение обратного отображения [15], [16]. Такие техники, тем не менее, оказываются на порядок медленнее, чем простое вычисление Якобиана.
, где k есть положительный прирост. В отсутствии каких бы то ни было препятствий, внутренних столкновений или ограничений сочленений, этот отдельный оператор гарантированно достигает цели. К сожалению, при отсутствии аналитического решения, вычисление обратного Якобиана должно быть произведено численно в каждый такт времени. Есть несколько численных методов, предложенных для вычисления обратного преобразования, в диапазоне от эффективных техник координатного спуска [11], [12], [13], [14] до функций-аппроксимаций, изучающих приближение обратного отображения [15], [16]. Такие техники, тем не менее, оказываются на порядок медленнее, чем простое вычисление Якобиана.
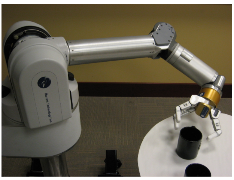
| Рис. 4. WAM попал в 6 из 7 ограничений сочленений, пока тянулся за кружкой. Пределы движения сочленений приводят к тому, что оператор Якобиана застревает в локальном минимуме. |
Альтернативным подходом, впервые представленным в [17], является использование транспонирования Якобиана вместо инверсии. В итоге закон управления имеет форму 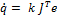 . Данный оператор исключает большие накладные расходы на вычисление обратного преобразования, используя вместо него легко-вычислимый Якобиан. Легко показать, что в тех же условиях без препятствий, как и оператор обратного преобразования Якобиана, так и оператор транспонированного Якобиана (JT) гарантированно достигает цели. Строгое доказательство дано в [17], его идея состоит в следующем. Движение рабочего органа в каждый момент времени записывается, как
. Данный оператор исключает большие накладные расходы на вычисление обратного преобразования, используя вместо него легко-вычислимый Якобиан. Легко показать, что в тех же условиях без препятствий, как и оператор обратного преобразования Якобиана, так и оператор транспонированного Якобиана (JT) гарантированно достигает цели. Строгое доказательство дано в [17], его идея состоит в следующем. Движение рабочего органа в каждый момент времени записывается, как  . Произведение мгновенного движения на вектор ошибки есть
. Произведение мгновенного движения на вектор ошибки есть 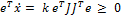 . Т.к. оно всегда положительно, с нашими предположениями о препятствиях оператор гарантировано направляет процесс к цели.
. Т.к. оно всегда положительно, с нашими предположениями о препятствиях оператор гарантировано направляет процесс к цели.
JT-оператор делает ключевое предположение о том, что любое направление скорости управляемого сочленения допустимо. Это предположение нарушается в присутствии препятствий в конфигурационном пространстве[1]. Эти препятствия могут быть в форме препятствий рабочего пространства, с самопересечениями или в виде ограничений сочленений. Рисунок 4 предоставляет пример, где транспонированный Якобиан пытается направить манипулятор в направлении к цели, а рука не может следовать в этом направлении из-за пределов сочленений. Эти ограничения связей уменьшают эффективность подхода, как самодостаточного решения генерации траекторий для многошарнирного манипулятора. Однако, JT управляющий цикл очень быстро вычисляется и предоставляет действие для следования рабочего органа напрямую по направлению к его цели. Эти свойства делают его идеальным кандидатом для локальной операции расширения внутри алгоритма планирования такого, как RRT.
IV. ИССЛЕДОВАНИЕ В ПРОСТРАНСТВЕ КОНФИГУРАЦИЙ,
А КОНЦЕНТРАЦИЯ УСИЛИЙ В РАБОЧЕМ ПРОСТРАНСВЕ
Мы может использовать оператор транспонированного Якобиана для предоставления мощных действий, направленных на цель, внутри планировщика, основанного на выборках, такого, как RRT. Идея – поменять стремление к цели в пространстве конфигураций, использованное в оригинальном RRT, на стремление к цели в рабочем пространстве с помощью транспонированного Якобиана.
| GrowRRT() 2 Qnew = { qstart }; 3 while (DistanceToGoal(Qnew) > distanceThreshold) 4 p = RandomReal([0.0, 1.0]); 5 if (p < pg) 6 Qnew = ExtendTowardsGoal(); 7 else 8 Qnew = ExtendRandomly(); 9 if (Qnew!= ∅) 10 AddNodes(Qnew) ExtendTowardsGoal() 11 qold = ClosestNodeToGoal(); 12 repeat 13 JT = JacobianTranspose(qold); 14 δx = WorkspaceDelta(qold, xgoal); 15 δq = JT · δx; 16 qnew = qold + δq; 17 if (CollisionFree(qold, qnew)) 18 Qnew = Qnew ∪ qnew; 19 else 20 return Qnew; 21 qold = qnew; 22 while (DistanceToGoal(qnew) > distanceTrheshold) 23 return Qnew; |
Рис. 5. Алгоритм JT-RRT
Чтобы реализовать это, вместо выбора с вероятностью pg вершины, ближайшей в конфигурационном пространстве к цели в конфигурационном пространстве ggoal, и затем расширение от этой вершины в направлении к qgoal, используя метрику конфигурационного пространства, мы выбираем вершины в рабочем пространстве, ближайшие и движемся к цели xgoal в рабочем пространстве, расширяем из вершины в направлении к xgoal, используя конструкцию транспонированного Якобиана. Это позволяет стремить поиск к желаемой цели в рабочем пространстве в то время, как происходит эффективное исследование пространства конфигураций. В итоге подход разделяет все преимущества подхода Бертрама и ко. над предыдущими техниками. А именно никакого явного решения задачи обратной кинематики не требуется для планирования (как и нет ограничений, вызванных сокращённым набором образцов решений IK), все вычисленные решения достижимы, и стремление к цели в рабочем пространстве завершится с намного более быстрой сходимостью, чем у обычного алгоритма, основанного на выборках. Однако, возможность использовать транспонированный Якобиан для вычисления расширений приводит прямо к цели, в результате даёт на много более эффективное стремление к цели, чем алгоритм Бертрама и ко., который вычисляет случайные расширения из ближайших вершин. Это важное различие предоставляет значительное улучшение быстродействия, которое будет показано в следующей секции. JT-RRT представлена на рисунке 5. В этом псевдокоде RRT выращивается до того, как одна из новых вершин, добавленная в дерево (т.е. во множество Qnew), не станет удовлетворять желаемому порогу расстояния до цели. В течение этапа расширения, с вероятностью pg дерево выращивается в направлении к цели, и с вероятностью (1 – pg) оно выращивается в случайную сторону пространства конфигураций (точно, как направленный на цель RRT). При выращивании дерева по направлению к цели (функция ExtendTowardsGoal), выбиралась вершина дерева qold с кратчайшим расстоянием до цели xgoal в рабочем пространстве и для этой вершины вычислялся транспонированный Якобиан.

Рис. 6. Пример задачи планирования, использованной в наших результатах. В каждом случае манипулятор был подвержен проверке планированием пути для помещения его рабочего органа в желаемое местоположение (x,y,z) в пространстве. Самое левое изображение показывает начальную конфигурацию руки, остальные изображения показывают отдельные конфигурации руки, удовлетворяющие каждому сценарию соотв.
| Approach | Scenario | Successful | Time (s) | Nodes | Random Extensions | Goal Extensions | Collision Checks | Joint Limits |
| Bertram et al. | 50/50 | 1.542 | N/A | |||||
| JT-RRTs | 50/50 | 0.450 | ||||||
| Bertram et al. | 50/50 | 0.981 | N/A | |||||
| JT-RRTs | 50/50 | 1.761 | ||||||
| Bertram et al. | 31/50 | 10.926 | N/A | |||||
| JT-RRTs | 50/50 | 0.866 | ||||||
| Bertram et al. | 1/50 | 5.396 | N/A | |||||
| JT-RRTs | 50/50 | 2.304 | ||||||
| Bertram et al. | 50/50 | 1.810 | N/A | |||||
| JT-RRTs | 47/50 | 1.840 | ||||||
| Bertram et al. | 6/50 | 16.011 | N/A | |||||
| JT-RRTs | 50/50 | 4.152 |
Табл.1. Результаты планирования для манипулятора с 7ю ст. свободы
В рабочем пространстве вектор от положения рабочего органа qold до xgoal используются для вычисления дельты delta δx рабочего пространства, на которую умножается JT. Из-за того, что это даёт (только) мгновенное направление движения по направлению к цели, важно, что только маленький шаг производится в этом направлении до того, как транспонированный Якобиан будет перевычислен. Итоговая дельта δq в пространстве конфигураций добавлена к qold для вычисления новой конфигурации qnew, которая относится направлению к xgoal в рабочем пространстве. Если эта конфигурация достижима из qold без столкновений с некоторыми препятствиями в конфигурационном пространстве или нарушений ограничений связей сочленений, оно включается во множество вершин Qnew, добавляется в дерево. Некоторое число расширений хотя и оставлены вне псевдокода для его чистоты, но могут быть добавлены в эту базовую версию алгоритма для улучшения производительности. В частности, из-за того, что транспонированный Якобиан может приводить к тому, что манипулятор входил в противоречие с пределами сочленений, во время вычисления новой конфигурации qnew обычно намного более эффективно ограничить величину каждого сочленения с помощью соответствующего предела (строка 16). Если все сочленения достигли своих пределов, тогда мы заканчиваем операцию расширения (с этих пор мы не может больше использовать транспонированный Якобиан). В добавок, выбирая вершины, из которых будем расширять дерево к цели (строка 11), мы избегаем выбор вершин, которые уже были посещены на этапе расширения (с этих пор транспонированный Якобиан будет производить те же расширения, полученные в дублирующих вершинах).
V. РЕЗУЛЬТАТЫ
Мы сравнили быстродействие алгоритма JT-RRT с расширением RRT от Бертрама и ко. по широкому диапазону разных сценариев планирования запутывая наш манипулятор с 7ю степенями свободы. В каждом сценарии задачей было достигнуть разных положений (x,y,z) рабочего органа в пространстве, избегая препятствий в окружающей среде. Рисунок 6 показывает начальную конфигурацию руки и образец целевой конфигурации для каждого сценария. Т.к. одним из мотивов данного исследования является координирование между руками-манипуляторами, а мобильный робототехнический Segway, мы включили Segway, как одно из препятствий внешней среды вместе с чашками, установленными на его крышку. Стенки, пол и основа манипулятора также включены в перечень для целей предотвращения столкновений.
Оба подхода реализованы на C++, используя симулятор OpenRAVE, в оригинале разработанный в Университете Carnegie Mellon, а выполнение проводилось на процессоре Centrino Core2Duo 2.3 GHz. Для каждого сценария мы осуществляли 50 разных запусков планирования и записывали: число успешных запусков (Successful), всё затраченное время (Time (s)), число добавленных вершин в дерево (Nodes), число попыток случайных расширений (Random Extensions), число попыток расширений к цели (Goal Extensions), число проверок самопересечений (Collision Checks), а также число раз, когда любое сочленение достигало своего предела в течение работы расширения по транспонированному Якобиану (Joint Limits). Все значения соответствуют успешным запускам. Средние для всех этих значений включены в Таблицу 1. Для обоих подходов мы использовали стремление к цели с вероятностью pg равной 0.5, которая показала себя наиболее эффективной для подхода Бертрама и ко. [6]. Мы более не подстраивали это значение для подхода JT-RRT. Каждая целевая позиция рабочего органа должна быть достигнута с порогом в 0.15 метров, тогда цель считается исполненной.
Отдельная траектория из результатов третьего сценария показана на рис. 7, в обоих случаях: симуляции и в течение работы нашей физической руки-манипулятора. Из результатов видно, что алгоритм JT-RRT обычно требует намного меньше вычислений и добавляет значительно меньше вершин в дерево поиска, в том числе и в особо сложных сценариях работы.
Также он успешно генерирует решения для почти каждого запуска[2]. Для отдельного сценария, где он не мог создавать решения все 100% времени, оказывалось, что операция расширения по транспонированному Якобиану находился в конфликте с пределами сочленений манипулятора (число раз, когда ограничения сустава были достигнуты в течение исследования, составило 5559). Это побочный эффект использования транспонированного Якобиана: как было отмечено ранее, это очевидно при существовании препятствий в конфигурационном пространстве и ограничениях сочленений. Простым избавлением от данного эффекта было бы убеждаться в том, что каждая новая вершина, сгенерированная на этапе расширения к цели, переводит рабочий орган ближе к цели на нетривиальное расстояние; и убеждаться также в том, что пределы сочленений не сместят движение перемещаться в бесполезном направлении. Даже более ожидаемым улучшением могло бы быть, использование транспонированного Якобиана, как проводника для более компетентного локального поиска во время расширения к цели, таким образом, ограничения связей могли бы быть приняты к рассмотрению и преодолены.
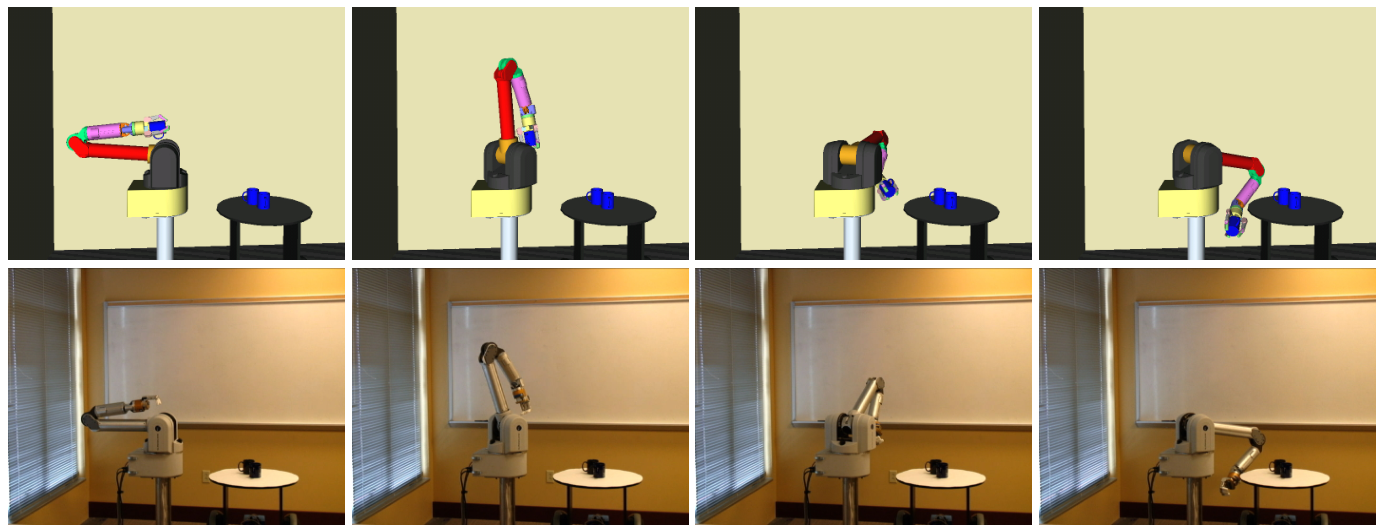
Рис. 7. Алгоритм JT-RRT, использован для планирования манипуляций руки-робота с 7ю ст. свободы. Верхние картинки показывают траекторию, выполненную в симуляторе OpenRAVE; нижние картинки – траекторию нашей робо-платформы. Траектория соответствует 10й задаче из множества результатов.
Однако, в общем случае производительность JT-RRT – очень хорошая для затрат как по времени вычислений, так и по памяти. Причина того, что обычно он был намного более эффективен, чем подход Бертрама и ко., была в том, что он лучше способен вычислять расширения, приводящие к желаемой цели. Дереву лучше, чем просто выбирать ближайшую к цели вершину и затем расширяться в случайном направлении, быть в состоянии выбрать такую вершину и расширяться напрямую в направлении к цели. Это значительно улучшает целе-ориентированную часть дерева поиска и даёт возможность поражать цели с очень малым отклонением, что по-другому было бы нереализуемо при случайных расширениях.
VI. ЗАКЛЮЧЕНИЕ
Мы представили расширение алгоритма RRT, которое способно преодолеть проблему вывода обратной кинематики, эксплуатируя природу Якобиана, как преобразования из пространства конфигураций в рабочее пространство. Итоговый алгоритм может обуздать мощь RRT в исследовании сильно многомерных конфигурационных пространств в то время, также способен концентрировать его поиск в направлении к желаемой цели в рабочем пространстве. Мы нашли данный алгоритм очень эффективным при планировании путей для многошарнирного манипулятора и представили результаты как симуляции, так и для руки робота с семью степенями свободы.
В настоящее время мы работаем над некоторыми расширениями нашего текущего каркаса. Во-первых, мы изучаем использование транспонированного Якобиана, как проводника для более компетентного локального поиска при операции расширения. Мы также внимательно изучаем использование эвристик, чтобы создавать лучшие/быстрейшие решения (такие как использованы в алгоритме RRT с отсечением по времени [5]), т.к. качество решений обычного RRT может изменяться существенно. Наконец, мы объединяем наш планировщик уровня руки с планировщиком хватания, чтобы выполнять законченные манипуляции и хватательные задачи включая известные и неизвестные объекты.
VII. БЛАГОДАРНОСТИ
ЛИТЕРАТУРА
[1] Связи с неинтегрируемой скоростью (неголономные связи) будут также нарушать это предположение, но они реже встречаются у рук роботов.
[2] Каждый подход ограничен добавлением 100 000 вершин в дерево поиска.