Введение
Изложенный здесь материал на протяжении ряда лет читался профессором Вернером Куихом в курсе «Теоретическая информатика» для студентов Венского технического университета. Данное пособие может рассматриваться лишь как краткий конспект лекций, читаемых авторами для студентов математического факультета Калининградского госуниверситета, и не является заменой последних.
В пособии изложены основы теории формальных языков и грамматик, включая регулярные, контекстно-свободные грамматики и грамматики Ван Вайнгаардена, а также теория автоматов применительно к анализу формальных языков, включая конечные автоматы, магазинные автоматы и машины Тьюринга. Далее даны основы теории алгоритмов и рекурсивных функций, где особое внимание уделено вопросам вычислимости. В последней главе рассмотрены проблемы весьма актуальной сейчас теории сложности.
В конце пособия приведены упражнения по изложенным темам вместе с их краткими решениями, что необходимо для практического закрепления материала.
ГРАММАТИКИ, АВТОМАТЫ
И КОНТЕКСТНО-СВОБОДНЫЕ ЯЗЫКИ
Алфавит есть непустое конечное множество. Элементы алфавита называются символами. Пусть S – алфавит. Множество всех слов над S, а именно
S* = { x 1 x 2 …xn | xi ÎS, 1£ i £ n, n ³0}
вместе с операцией конкатенации образуют свободный моноид, порожденный S, с единичным элементом e (для n = 0). Через | w | обозначим длину слова w ÎS*: | x 1… xn | = n, n ³1, |e| = 0. Очевидно, выполняется | w1w2 | = | w 1| + | w 2|. Отображение | |: S* ® ¥, где ¥ – неотрицательные целые числа {0, 1, 2,...} есть гомоморфизм моноида <S*, ×, e> на моноид <¥, +, 0>.
Каждое подмножество L множества S*, т.е. L Í S*, называется формальным языком над S. Пусть L 1 и L 2 формальные языки над S, т.е. L 1, L 2 Í S*. Тогда определим произведение L 1 и L 2 как L 1× L 2= { w 1 w 2 | w 1Î L 1, w 2Î L 2} Í S*.
Естественно <P(S*), ×, {e}> снова моноид. (Через P обозначим степень множества.) Он называется моноидом формальных языков.
Для L Í S* мы можем с помощью произведения определить степени:
L 0 = {e}, Ln +1 = LLn = LnL, n ³0.
L * определяется как L * =  n. Нам потребуется также L + =
n. Нам потребуется также L + =  n. Очевидно, выполняется L * = {e} È L + и L + = LL * = L * L.
n. Очевидно, выполняется L * = {e} È L + и L + = LL * = L * L.
В случае, если множество М содержит в точности один элемент, М = { а }, то мы также будем писать, если не возникнет путаницы, просто а. Справедливо: an = a … a (n раз) и a * = { an | n ³0}.
Пусть S – множество. Каждое подмножество R множества S ´ S, т.е. R Í S´S, называется (двухместным) отношением над S. Если (s 1 ,s 2)Î R, то мы пишем s 1 Rs 2.
Пусть R – отношение над S. Транзитивное замыкание R+ определяется следующим образом: t 1 R+t 2в точности тогда, если существуют s 1, s 2, …, sn Î S, n >1, такие что t 1 = s 1, t 2 = sn и sjRsj+1, 1£ j £ n -1. Рефлексивное и транзитивное замыкание R *определяется следующим образом: t 1 R * t 2 в точности тогда, если t 1 = t 2 или t 1 R+t 2.
Грамматики есть математические системы, служащие для порождения формальных языков. Для определения синтаксиса языка программирования они чрезвычайно важны. Множество синтаксически правильных программ (причем содержание программ не принимается во внимание) может пониматься как формальный язык. Этот формальный язык определяется в общем случае через контекстно-свободную грамматику в нормальной форме Бэкуса.
Контекстно-свободная грамматика есть четверка G = (Ф, S, P, S). Причем
(i) Ф – алфавит, называемый алфавитом переменных, или нетерминальных символов;
(ii) S – алфавит, называемый алфавитом базовых,или терминальных, символов, где Ф Ç S = Æ, V = Ф È S;
(iii) P Ì Ф´(Ф È S)* – конечное множество, называемое множеством продукций;
(iv) S ÎФ – начальная переменная.
Пусть G = (Ф, S, P, S) – контекстно-свободная грамматика. Тогда Þ G (или просто Þ) – отношение на V *, которое определено следующим образом: j Þ y тогда и только тогда, когда j = g A d, y = gad и (A,a)Î P.
Говорят, что j прямо выводит y, или y может быть непосредственно выведено из j.
Пусть отношение Þ  (или просто Þ*) рефлексивное и транзитивное замыкание отношения Þ G. Говорят, что j выводит y, или y может быть выведено из j.
(или просто Þ*) рефлексивное и транзитивное замыкание отношения Þ G. Говорят, что j выводит y, или y может быть выведено из j.
Пусть G = (Ф, S, Р, S) – контекстно-свободная грамматика. Тогда обозначим L (G) – язык, порожденный G, причем выполняется:
L (G) = { w | w ÎS* и S Þ w }.
Если (А,a)Î Р, то пишем также А ® G a, или А ®aÎ P.
Пример 1.1. Пусть G = ({ S }, {(,)}, P, S) с P = { S ®(S) S, S ®e}. Тогда L (G) – есть множество всех корректных скобочных выражений над скобками (и). Например: (())() Î L (G), так как это выражение может быть выведено из S:
S Þ (S) S Þ ((S) S) S Þ (() S) S Þ (()) S Þ (())(S) S Þ (())() S Þ (())().
Таким образом, выполняется S Þ* (())(), и тем самым (())() лежит в L (G).
Грамматика G ’ = ({ S }, {(,)}, P ’, S) с P ’ = { S ® SS, S ®(S), S ®e} порождает тот же самый язык. Однако правила вывода имеют другую структуру:
S Þ SS Þ (S) S Þ ((S)) S Þ (()) S Þ (())(S) Þ (())().
Тем самым показано, что (())()Î L (G ’). □
Если синтаксис языка программирования определяют через контекстно-свободную грамматику, то продукции часто представляют в нормальной форме Бэкуса. При этом переменные пишутся в форме < w >, где w – непустое слово над алфавитом VZ. Если < w > ® a1, …, < w > ® a n – все продукции с левой частью < w >, то пишут
< w >::= a1|a2|…|a n.
Алфавиты Ф, VZ , S не всегда указаны. Кроме того, разрешена следующая конструкция: aj может иметь вид g1{g2}g3. Это означает, что возможны прямые выводы:
< w > Þ g1g2 n g3, n ³0.
Пример 1.2. В языке PASCAL константы определяются в разделе описания констант. Синтаксис раздела описания констант задается следующими правилами (в нормальной форме Бэкуса):
<раздел описания констант>::= <пустой>| const <определение константы> {;<определение константы>};
<определение константы>::=<идентификатор константы> = <константа>
<идентификатор константы>::= <идентификатор>
<идентификатор>::= <буква>{<буква или цифра>}
<буква или цифра>::= <буква>|<цифра>
<буква>::= A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z
<цифра>::= 0|1|2|3|4|5|6|7|8|9
<константа>::= <число без знака>|<знак><число без знака>|
<идентификатор константы>|<знак><идентификаторконстанты>
<число без знака>::= <целое без знака>|<вещественное без знака>
<целое без знака>::= <цифра>{<цифра>}
<вещественное без знака>::= <целое без знака>.<цифра>{<цифра>}|
<целое без знака>.<цифра>{<цифра>}Е
<характеристика>|<целое без знака>Е
<характеристика>
<характеристика>::= <целое без знака>|<знак><целое без знака>
<знак>::= +|-
<пустой>::= e
Определение константы
const PI = 3.14; E = 2.73;
синтаксически правильно, так как существует вывод:
<раздел описания констант>
Þ const <определение константы>;<определение константы>;
Þ const <идентификатор константы>=<константа>;<определение константы>;
Þ const <идентификатор>=<константа>;<определение константы>;
Þ const <буква><буква или цифра>=<константа>;<определение константы>;
Þ const <буква><буква>=<константа>;<определение константы>;
Þ const Р <буква> = <константа>;<определение константы>;
Þ const РI = <константа>;<определение константы>;
Þ const РI = <число без знака>;<определение константы>;
Þ const РI = <вещественное без знака>;<определение константы>;
Þ const РI = <целое без знака><цифра><цифра>;<определение константы>;
Þ const РI = <цифра><цифра><цифра>;<определение константы>;
Þ* const РI = 3.14;<определение константы>;
Þ* const PI = 3.14; E = 2.73; □
Формальный язык L Í S* называется контекстно-свободным тогда и только тогда, когда имеется контекстно-свободная грамматика G, такая что L (G) = L. Множество всех выражений, правильно заключенных в скобки, и множество всех синтаксически правильных определений констант есть, таким образом, контекстно-свободные языки.
Каждому выводу в контекстно-свободной грамматике G = (Ф, S, Р, S) можно поставить в соответствие направленное дерево, так называемое дерево вывода, узлы которого обозначаются символами из V:

(1) Выводу S Þ A 1 A 2… An, Aj Î V, 1£ j £ n, соответствует дерево вывода:

(2) Пусть выводу S Þ* a1 A a2, a1,a2 Î V *, A ÎФ, соответствует дерево вывода:

Тогда выводу S Þ* a1 A a2 Þ a1 A 1… An a2, Aj Î V соответствует дерево вывода:
Метки конечных узлов, если они при прохождении по дереву вывода в положительном направлении связываются воедино, дают в результате слово a1 A 1… An a2. Это слово называется результатом дерева вывода.
Пример 1.3. Выводам слова (())() в G и G ’ соответствуют деревья вывода:
 | |||
 | |||
Пунктирные линии не принадлежат дереву вывода, которое соответствует правилу вывода в примере. Тем не менее дерево, состоящее из сплошных и пунктирных линий, также является деревом вывода с результатом (())(). Таким образом, имеется два различных дерева вывода с результатом (())(). Это приводит к определению однозначной контекстно-свободной грамматики. Контекстно-свободная грамматика G называется однозначной тогда и только тогда, когда для каждого w Î L (G) найдется единственное дерево вывода. В противном случае она называется многозначной.
Пример 1.4. Пусть G = (Ф, S, P, S),
где Ф = {  оператор if
оператор if  , оператор
, оператор  };
};
S = { if, then, else, выражение, другой_оператор };
P = { оператор if ::= if выражение then оператор  |
|
if выражение then оператор else оператор ;
оператор ::= оператор if | другой_оператор };
S = оператор if .
L (G) описывает оператор if в PASCAL. Грамматика G – неоднозначна, так как «программа»:
if выражение then if выражение then
другой_оператор else другой_оператор
имеет два различных дерева вывода. Необходимая для языка программирования однозначность грамматики достигается тем, что вышеуказанная программа ставится в соответствие всегда только одному из двух возможных деревьев вывода. □
Контекстно-свободные грамматики, продукции которых имеют простую структуру, называются регулярными грамматиками. Контекстно-свободная грамматика G = (Ф, S, P, S) называется регулярной, если все продукции имеют вид: А ® аВ ‚ А ® а ‚ или S ® ε‚ А ‚ В ÎΦ‚ а ÎS. Однако продукция S ® ε может встречаться только тогда, когда S не встречается нигде в правой части продукции. Таким образом, продукции вида А ® aS запрещены.
Формальный язык L Í S* называется регулярным, если существует регулярная грамматика G, такая что L (G) = L. Отсюда сразу следует, что каждый регулярный язык также контекстно-свободный. Однако обратное неверно: именно { anbn | n  1} контекстно-свободный, но не регулярный язык. Позже мы увидим, что множество всех констант в PASCAL – регулярный язык (см. пример 1.11).
1} контекстно-свободный, но не регулярный язык. Позже мы увидим, что множество всех констант в PASCAL – регулярный язык (см. пример 1.11).
Пример 1.5. Контекстно-свободная грамматика.
G = ({ E, T }, {+,*, a }, P, E), где P = { E  Ε + T, E T, T T * a, T ® a }
Ε + T, E T, T T * a, T ® a }
порождает язык L (G) = a (* a)*(+ a (* a)*)*. Поэтому возможны следующие продукции:
Е Þ* T + T +...+ T, T Þ* a * a * ... * a.
Слова из L (G) могут рассматриваться как арифметические выражения без скобок. Однако возможно указать некоторую регулярную грамматику G ’, которая порождает L (G), именно: G ’= ({ S, A }, {+,*, a }, P ’, S), где P ’ = { S аА ‚ S а ‚ А + S, A * S }. Тогда L (G) регулярный язык. □
Разберем теперь проблему анализа некоторого заданного слова w относительно грамматики G. Под этим понимается следующее.
Пусть G = (Ф, S, P, S) и w ÎS*. Тогда требуется проверить, является ли w словом из L (G). Эта проблема встречается при трансляции программ. В случае, если L (G) – множество всех синтаксически правильных программ и w – программа, то требуется проверить, является ли w синтаксически правильной программой, то есть лежит ли w в L (G). Мы увидим, что конечные автоматы (соответственно, магазинные автоматы) могут применяться для разрешения проблемы анализа в отношении регулярных (соответственно, контекстно-свободных грамматик).
Конечный автомат обладает конечным числом состояний и входной лентой со считывающей головкой. Если конечный автомат находится в некотором состоянии и считывающая головка читает символ на входной ленте, то функция перехода недетерминировано в зависимости от предыдущего состояния и прочитанного символа определяет новое состояние и считывающая головка смещается на один символ вправо. Конечный автомат имеет, кроме того, одно начальное состояние и сколь угодно много конечных состояний. Некоторое слово воспринимается конечным автоматом тогда и только тогда, когда это слово как содержимое входной ленты переводит конечный автомат из начального состояния в некоторое конечное состояние. В общем случае конечный автомат работает недетерминировано. Существует несколько возможных определений конечных автоматов.
Конечный автомат A над алфавитом  есть система A =(Q, S, d, q0, F),
есть система A =(Q, S, d, q0, F),
(i)
|
(ii) S – входной алфавит;
(iii) d: Q ´S ® P(Q) (степень множества Q) – функция перехода;
(iv) q0 Î Q – начальное состояние;
(v) F Í Q – множество конечных состояний.
Продолжим отображение dдо отображения  : Q ´S* ®P(Q) путем
: Q ´S* ®P(Q) путем
(q, e) = { q }, (q, aw) =  для каждого q
для каждого q  Q, w ÎS*, a ÎS.
Q, w ÎS*, a ÎS.
Слово w принимается конечным автоматом A тогда и только тогда, когда F Ç (q 0, w) ¹ Æ. Формальный язык ||A||, принимаемый автоматом A, есть ||A|| = { w | F Ç (q 0, w) ¹ Æ}.
В случае, если не возникает путаницы, вместо пишут просто d.
Функцию перехода d можно также представить так называемой таблицей переходов.
Пусть A = (Q, S, d, q0, F), где Q = { q 0, q 1, …, qn } и S = { a 1, a 2, …, am }, тогда d изображается следующей таблицей:
| d | a 1 | a 2 | … | am |
| q 0 | d(q 0, a 1) | d(q 0, a 2) | … | d(q 0, am) |
| q 1 | d(q 1, a 1) | d(q 1, a 2) | … | d(q 1, am) |
| . | . | . | . | |
| . | . | . | . | |
| . | . | . | . | |
| qn | d(qn, a 1) | d(qn, a 2) | … | d(qn, am) |
Другая возможность – представление функции перехода ориентированным помеченным графом. Граф имеет n +1 узлов, которые соответствуют состояниям q 0,…, qn. Если выполняется q d(p, a), то ребро, обозначенное символом а, ведет от узла p к узлу q. Узел, соответствующий начальному состоянию, обозначается зачерненным, а узлы, соответствующие конечным состояниям, заключаются в кольцо.
Слово a 1… am ÎS* описывает путь от p к q в графе, в случае если существуют узлы p 1 = p, p 2,…, pm, pm +1 = q, так, что для каждого j, 1 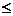 j m, имеется ребро от p j к pj +1, которое обозначается как aj. Пустое слово e описывает для любого q путь от q к q. Поэтому справедливо, что слово w ÎS* в точности тогда описывает путь в графе от p к q, когда q Î (p, w). Отсюда ||A|| – множество всех слов, которые описывают путь от начального состояния к одному из конечных состояний.
j m, имеется ребро от p j к pj +1, которое обозначается как aj. Пустое слово e описывает для любого q путь от q к q. Поэтому справедливо, что слово w ÎS* в точности тогда описывает путь в графе от p к q, когда q Î (p, w). Отсюда ||A|| – множество всех слов, которые описывают путь от начального состояния к одному из конечных состояний.
Пусть G = (Ф, S, P, S) – регулярная грамматика. Построим граф конечного автомата, который воспринимает L (G).
Множество узлов графа задается как Ф È { F }. Узел F – конечный узел.
Если S ® eÎ R, то S также конечный узел. Начальный узел задается через S.
Если A ® a Î R, то ребро, обозначенное через а, ведет от узла А к конечному узлу F.
Если A ® aB Î R, то ребро а ведет от узла А к узлу В.
Пример 1.5. (продолжение). Построим граф конечного автомата, воспринимающего L (G):
 Конечный автомат A = (Q, S, d, q0, F) – детерминированный, если |d(q, x)|£1
Конечный автомат A = (Q, S, d, q0, F) – детерминированный, если |d(q, x)|£1  для всех q Q, x ÎS. Вместо d(q, x) = { p } пишем тогда d(q, x) = p, что означает, что мы рассматриваем d как частичную функцию d: Q ´S ® Q. Определение для упрощается тогда до следующего:
для всех q Q, x ÎS. Вместо d(q, x) = { p } пишем тогда d(q, x) = p, что означает, что мы рассматриваем d как частичную функцию d: Q ´S ® Q. Определение для упрощается тогда до следующего:
(q, ε) = q, (q, aw) = (d(q, a), w) и ||A|| = { w | (q0, w)Î F }.
На графе это означает, что от каждого узла q отходит не более чем одно ребро, обозначаемое х ÎS.
Справедлива следующая теорема:
Пусть A = (Q, S, d, q0, F) – конечный автомат, тогда имеется детерминированный конечный автомат A’, такой что ||A|| = ||A’||.
Мы хотим теперь построить автомат A’ с множеством состояний P (Q). Продолжим d: Q ´S® P (Q) до отображения d’: P (Q) ´S ® P (Q) посредством
d′({ q 1, q 2,..., qk }, x) =  (qj, x), q 1,..., qk Q, x ÎS.
(qj, x), q 1,..., qk Q, x ÎS.
Таким образом, d’({ q 1, q 2,..., qk }, x) есть множество всех тех состояний, которые могут быть достигнуты из одного из состояний q 1, q 2,..., qk через ребро, обозначенное x. Пусть F ’ = { G P (Q) | G  F ≠ Ø}, что значит множество G как состояние автомата A’ есть конечное состояние тогда и только тогда, когда оно содержит хотя бы одно конечное состояние из F. Пусть A’ = (P (Q), S, d’, { q0 }, F ’). Тогда выполняется ||A’|| = ||A|| и A’ по построению – детерминированный автомат.
F ≠ Ø}, что значит множество G как состояние автомата A’ есть конечное состояние тогда и только тогда, когда оно содержит хотя бы одно конечное состояние из F. Пусть A’ = (P (Q), S, d’, { q0 }, F ’). Тогда выполняется ||A’|| = ||A|| и A’ по построению – детерминированный автомат.
Пример 1.5. (продолжение). Построим граф детерминированного конечного автомата, который принимает L (G):
 С помощью детерминированных конечных автоматов можно конечно «быстро» анализировать регулярные языки. Обратно: можно показать, что для каждого конечного автомата A найдется регулярная грамматика G, такая что L (G) = ||A||.
С помощью детерминированных конечных автоматов можно конечно «быстро» анализировать регулярные языки. Обратно: можно показать, что для каждого конечного автомата A найдется регулярная грамматика G, такая что L (G) = ||A||.
Предложение 1.1. Пусть L Í S* – формальный язык. Тогда следующие высказывания эквивалентны:
(i) существует регулярная грамматика G, такая что L = L (G);
(ii) существует конечный автомат A, такой что L = ||A||;
(iii) существует детерминированный конечный автомат, такой что L = ||A||. □
Пример 1.6. Слово v ÎS* называется подсловом слова w ÎS* тогда и только тогда, когда найдутся слова u 1, u 2ÎS*, такие, что w = u 1 v u 2. Требуется проверить, встречаются ли в слове w ÎS* подслова с определенными свойствами. Для этого строят детерминированный конечный автомат A, который принимает все слова w ÎS*, содержащие подслова с определенными свойствами. Это есть простейшая проблема распознавания образов («сопоставление с образцом»).
Пусть S = { a, b }. Требуется проверить, обладает ли слово w ÎS* следующими свойствами:
(i) ааа должно быть подсловом слова w;
(ii) аa должно встречаться как подслово на правом конце слова w.
Таким образом, можно построить детерминированный конечный автомат, который принимает формальный язык L ={ a,b }* ааа { a, b }*Ç{ a,b }* аа. Укажем две возможных конструкции.
Первый способ построения: конечный автомат вида
 |
принимает L. Чтобы его «детерминировать» представим функцию перехода в виде таблицы (без фигурных скобок) и определим функцию перехода детерминированного автомата.
| a | b | |
| q0 | q0, q1 | q0 |
| q1 | q2 | – |
| q2 | q3 | – |
| q3 | – | q4 |
| q4 | q4, q5, | q4 |
| q5 | q6 | – |
| q6 | – | – |
| q0, q1 | q0, q1, q2 | q0 |
| q0, q1, q2 | q0, q1, q2, q3 | q0 |
| q0, q1, q2, q3 | q0, q1, q2, q3 | q0, q4 |
| q0, q4 | q0, q1, q4, q5 | q0, q4 |
| q0, q1, q4, q5 | q0, q1, q2, q4,q5, q6 | q0, q4 |
| q0, q1, q2, q4, q5, q6 | q0, q1, q2, q3,q4,q5,q6 | q0, q4 |
| q0, q1, q2, q3, q4, q5, q6 | q0, q1, q2, q3, q4, q5, q6 | q0, q4 |
Это дает следующий детерминированный конечный автомат:

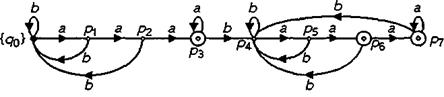
Относительно состояний p3, p6, p7 видно следующее: три состояния являются конечными состояниями. Символ a переводит автомат из одного из этих трех состояний снова в одно из трех состояний; символ b переводит из всех трех состояний в состояние p4. Поэтому можно три состояния p3, p6, p7 объединить в одно состояние p, при этом получают следующий детерминированный автомат:
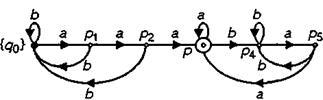
Второй способ построения. Видно, что слово лежит в L тогда и только тогда, когда оно заканчивается на aaa или содержит aaa и заканчивается на aa:

Затем дополняют этот «скелет автомата» до вышеописанного автомата. 
Обратимся к магазинным автоматам.
Магазин – это накопитель, в котором может читаться или изменяться только самый верхний символ.
Магазинный автомат имеет конечное число состояний, входную ленту со считывающей головкой и магазинную ленту (стек) с головкой чтения-записи, которая находится над самым верхним магазинным символом. Если магазинный автомат находится в некотором состоянии, читающая головка читает символ с входной ленты и головка чтения-записи читает самый верхний символ на магазинной ленте, то функция перехода определяет недетерминированным образом, в зависимости от старого состояния и двух прочитанных символов, следующие действия:
1) читающая головка остается над прочитанным символом или передвигается на один символ вправо;
2) самый верхний символ в магазине стирается;
3) слово над алфавитом магазина записывается на магазинной ленте, и головка чтения-записи устанавливается на новый самый верхний символ магазинной ленты;
4) магазинный автомат переходит в новое состояние.
Итак, пусть дан магазинный автомат, работающий с входным алфавитом S. На входной ленте пусть записано слово w ÎS*. Магазинный автомат стартует в заданном начальном состоянии, имеет читающую головку над первым символом входного слова и головку чтения-записи над стартовым символом в остальной части пустой магазинной ленты. Далее, автомат действует согласно пунктам 1) – 4). Если магазинному автомату удается попасть в так называемое конечное состояние, причем читающая головка должна стоять справа от последнего символа входной ленты, то тогда говорят, что магазинный автомат принимает w через конечное состояние. Если магазинному автомату удается достичь того, что магазинная лента пуста и читающая головка находится справа от последнего символа входной ленты, то говорят, что магазинный автомат принимает w через пустой магазин.
Формализуем теперь магазинные автоматы.
Магазинный автомат P есть семерка P = (Q, S, G, d, q0, p0, F), где
(i) Q – непустое конечное множество состояний;
(ii) S – алфавит, называемый входным алфавитом;
(iii) G – алфавит, называемый алфавитом магазина;
(iv) q0 Î Q – начальное состояние;
(v) p0 ÎG – начальный символ на магазинной ленте;
(vi) F  Q – множество конечных состояний;
Q – множество конечных состояний;
(vii) d: Q  (SÈ{ e }) G® P f (Q Г*) – функция перехода.
(SÈ{ e }) G® P f (Q Г*) – функция перехода.
(Через P f мы обозначаем множество всех конечных подмножеств.)
Содержимое магазинной ленты есть слово, причем самый верхний символ магазина стоит крайним слева.
Интерпретация d следующая:
Пусть d(q,a,p)={ (q1, g1),…,(qm, gm) }, q,q1,…,qm Î Q, a Î S, p Î G, g1, …, gm ÎГ*.
Если магазинный автомат находится в состоянии q, головка чтения читает символ a, а головка чтения-записи читает самый верхний символ в магазине p, то магазинный автомат выбирает недетерминированным образом некоторую пару (qi, gi). Это означает, что магазинный автомат переходит в состояние qi, на магазинной ленте p замещается на gi, головка чтения передвигается на один символ вправо и головка чтения-записи устанавливается над самым верхним (первым) символом слова gi.
Если выполняется d(q,e, p)={ (q1, g1),…,(qm, gm) }, то это означает, что головка чтения ничего не читает, а поэтому также и не перемещается вправо. Состояние и содержимое магазина изменяются, как описано выше.
Пусть P = (Q, S, G, d, q0, p0, F) – магазинный автомат. Конфигурация (ситуация) магазинного автомата P есть тройка (q, w, g), q Î Q, w ÎS*, gÎГ*. Интуитивно это означает, что автомат находится в состоянии q, что слово w – еще не прочитанная часть входного слова и что g стоит на магазинной ленте.
Определим далее отношение P, называемое прямым отношением перехода над конфигурациями P:
(q1, aw, pg) P (q2, w, g1g) Û (q2, g1)Îd(q1, a, p)
для q1, q2 Î Q, a ÎSÈ{ e }, w ÎS*, p ÎG, g, g1 ÎG*
Отношение P* есть рефлексивное и транзитивное замыкание P. Если выполняется (q1, w1, g1) P* (q2, w2, g2), то говорят, что конфигурация (q1, w1, g1) ведет к (q2, w2, g2). В случае, если ясно, какой магазинный автомат имеется в виду, вместо P и P*можно писать и *.
Пусть P = (Q, S, G, d, q0, p0, F) – магазинный автомат. Язык T(P), который принимается автоматом P через конечное состояние, есть
T(P)={ w ½(q0, w, p0) * (q,e, g), qÎF, gÎG*}.
Язык N(P), который принимается автоматом P через пустой магазин, есть
N(P)={ w ½(q0, w, p0) * (q, e,e), qÎQ }.
Язык  , который принимается автоматом P через пустой магазин и конечное состояние,есть
, который принимается автоматом P через пустой магазин и конечное состояние,есть
= { w ½(q0, w, p0) * (q, e,e), qÎF }.
Конечный автомат P – детерминированный тогда и только тогда, когда для всех qÎQ, a ÎSÈ{ e }, p ÎG выполнено:
1) ½d(q, a, p)½£ 1;
2) если d(q, e, p) ¹ Æ, то d(q, x, p) =Æ для всех x ÎS.
Магазинный автомат P = (Q, S, G, d, q0, p0, F) может быть представлен бесконечным ориентированным помеченным графом: множество узлов графа задается как {(g, q)½ gÎG*, q ÎQ}. От узла (g1, q1) к узлу (g2, q2) ведет в точности одно ребро, обозначенное a ÎSÈ e, если
(q1,a, g1) (q2, e, g2), т. е., если g1 = pg, g2 = g3g и (q2, g3) Î d(q1,a, p).
Тогда справедливо, что w ÎS* в точности тогда описывает путь от (g1, q1) к (g2, q2), когда (q1,w, g1) * (q2, e, g2).
Отсюда следует непосредственно, что T (P) есть множество всех тех слов, которые описывают путь от (p0,q0) к (g, q), q Î F, gÎG*; что N (P) есть множество всех слов, описывающих путь от (p0,q0) к (e, q), qÎQ и что есть множество всех тех слов, которые описывают путь от (p0,q0) к (e, q), q Î F.
Пусть G =(F,S, R, S) – контекстно-свободная грамматика, тогда магазинный автомат P = ({q},S, V,d, q,S,{ q }) принимает язык L(G) через пустой магазин (и конечное состояние), причем d определена следующим образом:
(q, Ba) Î d(q, e, A)  A ® Ba Î P, B Î F,
A ® Ba Î P, B Î F,
(q, a) Î d(q, a, A) A ® aa Î P, a Î S,
(q, e) Î d(q, e, A) A ® e Î P,
d(q, x, x) = {(q, e)} для всех x ÎS.
Пример 1.7. Для контекстно-свободной грамматики G = ({ S },{ a, b },{ S ® aSS, S ® b }, S) получают P = ({ q },S, V,d, q, S,{ q }), где d(q, e, S)={(q, aSS),(q, b)}, d(q, a, a)=d(q, b, b)={(q, e)}. Имеем: