Оценка параметров уравнения регресии в стандартизованном масштабе
Параметры уравнения множественной регрессии в задачах по эконометрике оценивают аналогично парной регрессии, методом наименьших квадратов (МНК). При применении этого метода строится система нормальных уравнений, решение которой и позволяет получать оценки параметров регрессии.
При определении параметров уравнения множественной регрессии на основе матрицы парных коэффициентов корреляции строим уравнение регрессии в стандартизованном масштабе:

в уравнении стандартизированные переменные

Применяя метод МНК к моделям множественной регрессии в стандартизованном масштабе, после опрделенных преобразований получим систему нормальных уравнений вида

Решая системы методом определителей, находим параметры — стандартизованные коэффициенты регрессии (бета — коэффициенты). Сравнивая коэффициенты друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом заключается основное достоинство стандартизованных коэффициентов в отличие от обычных коэффициентов регрессии, которые несравнимы между собой.
В парной зависимости стандартизованный коэффициент регрессии связан с соответствующим коэфициентом уравнения зависимостью

Это позволяет от уравнения в стандартизованном масштабе переходить к регрессионному уравнению в натуральном масштабе переменных:

Параметр а определяется из следующего уравнения

Стандартизованные коэффициенты регрессии показывают, на сколько сигм изменится в среднем результат, если соответствующий фактор xj изменится на одну сигму при неизменном среднем уровне других факторов. В силу того, что все перемеyные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии сравнимы между собой.
Рассмотренный смысл стандартизованных коэффициентов позволяет использовать их при отсеве факторов, исключая из модели факторы с наименьшим значением.
Компьютерные программы построения уравнения множественной регрессии позволяют получать либо только уравнение регрессии для исходных данных и уравнение регрессии в стандартизованном масштабе.
19. Характеристика эластичности по модели множественной регрессии. СТР 132-136
https://math.semestr.ru/regress/mregres.php
20. Взаимосвязь стандартизированных коэффициентов регрессии и коэффициентов эластичности. СТР 120-124
21. Показатели множественной и частной корреляции. Их роль при построении эконометрических моделей
Корреляция — это статистическая взаимосвязь двух или нескольких случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом, изменения одной или нескольких из этих величин приводят к систематическому изменению другой или других величин. Математической мерой Корреляции двух случайных величин служит коэффициент Корреляции. Понятие корреляции появилось в середине XIX века в работах английских статистиков Ф. Гальтона и К. Пирсона.
Коэффициент множественной корреляции (R) характеризует тесноту связи между результативным показателем и набором факторных показателей:

где σ2 — общая дисперсия эмпирического ряда, характеризующая общую вариацию результативного показателя (у) за счет факторов;
σ ост 2— остаточная дисперсия в ряду у, отражающая влияния всех факторов, кроме х;
у — среднее значение результативного показателя, вычисленное по исходным наблюдениям;
s — среднее значение результативного показателя, вычисленное по уравнению регрессии.
Коэффициент множественной корреляции принимает только положительные значения в пределах от 0 до 1. Чем ближе значение коэффициента к 1, тем больше теснота связи. И, наоборот, чем ближе к 0, тем зависимость меньше. При значении R < 0,3 говорят о малой зависимости между величинами. При значении 0,3 < R < 0,6 говорят о средней тесноте связи. При R > 0,6 говорят о наличии существенной связи.
Квадрат коэффициента множественной корреляции называется коэффициентом детерминации (D): D = R2. Коэффициент детерминации показывает, какая доля вариации результативного показателя связана с вариацией факторных показателей. В основе расчета коэффициента детерминации и коэффициента множественной корреляции лежит правило сложения дисперсий, согласно которому общая дисперсия (σ2) равна сумме межгрупповой дисперсии (δ2) и средней из групповых дисперсий σi2):
σ2 = δ2 + σi2.
Межгрупповая дисперсия характеризует колеблемость результативного показателя за счет изучаемого фактора, а средняя из групповых дисперсий отражает колеблемость результативного показателя за счет всех прочих факторов, кроме изучаемого.
Показатели частной корреляции. Основаны на соотношении сокращения остаточной вариации за счет дополнительно включенного в модель фактора к остаточной вариации до включения в модель соответствующего фактора

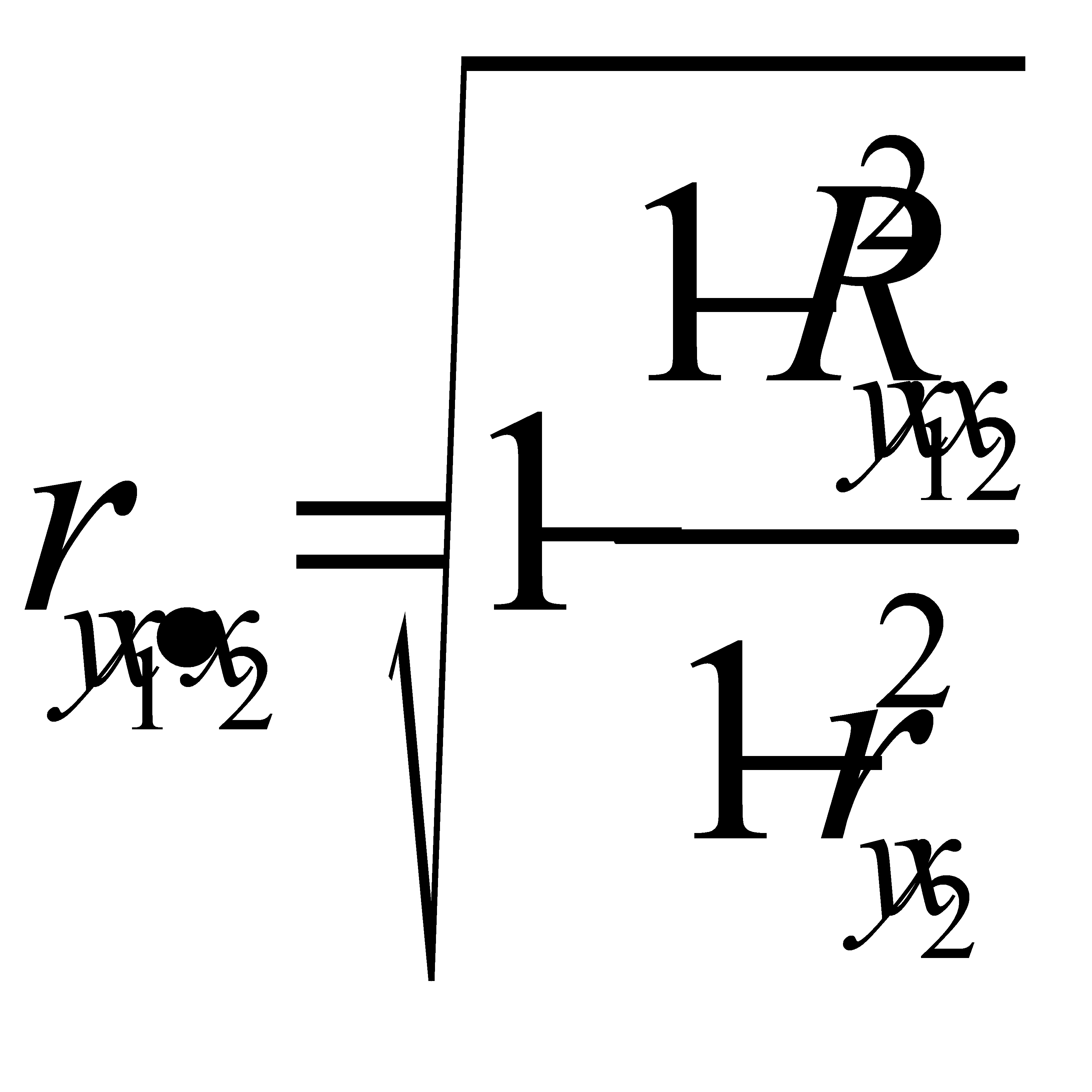
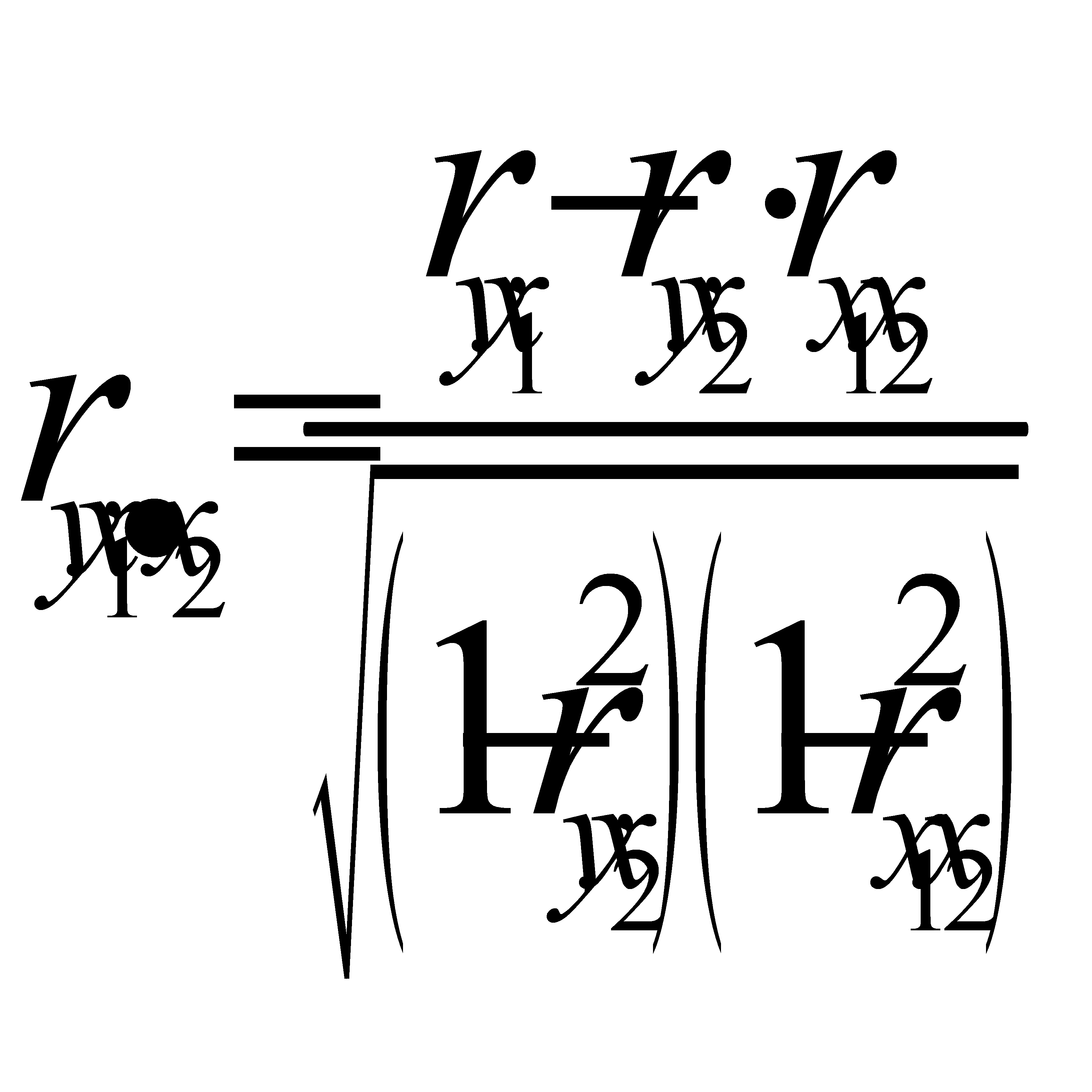


Рассмотренные показатели можно также использовать для сравнения факторов, т.е. Можно ранжировать факторы(т.е.2ой фактор более тесно связан).
Частные коэффициенты могут быть использованы в процедуре отсева факторов при построении модели.
Рассмотренные выше показатели являются коэф-ми корреляции первого порядка,т.е.они характризуют связь между двумя факторами при закреплении одного фактора (yx1. x2). Однако можно построить коэф-ты 2го и более порядка (yx1. x2x3, yx1. x2x3x4).
22. Оценка надежности результатов множественной регрессии.
Коэфициенты структурной модели могут быть оценены разными способами в зависимости от вида одновренных уравнений.
Методы оценивания коэф-тов структурной модели:
1) Косвенный МНК(КМНК)
2)Двухшаговый МНК(ДМНК)
3)Трехшаговый МНК(ТМНК)
4)МНП с полной информацией
5)МНП при огранич. информации
Применение КМНК:
КМНК применяется в случаеточнойидентификацииструктурноймодели.
Процедуры примения КМНК:
1. Структурн. модель преобраз. в привед. форму модели.
2. Для каждого уравнения привед.форма модели обычным МНК оцениваются привед. коэф 
3. Коэфициенты приведенной формы модели трансформируются в параметры структурной модели.
Еслиси стема сверхидентифицируема, то КМНК не исп, так как не дает однозначных оценок для параметров структурной модели. В этом случае могут исп. разные методы оценивания, среди которых наиболее распространен ДМНК.
Основная идея ДМНК на основе приведенной модели получить для сверхидентиф. уравнения теор. значения эндогенных переменных, содерж. в правой части ур-ния. Далее подставив в найденные значения вместо факт.значений применяется обычный МНК и структурн. форма сверхидент. ур-ния.
1 шаг: при опред.привед. формы модели и нахождении на ее основе оценок теор. значений эндогенной переменой
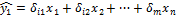
2 шаг: Применительно к структурному сверхидентифицируемому уравнению при определении структурных коэфициентов модели по данным теоритических значений эндогенных переменных.
23. Дисперсионный анализ результатов множественной регрессии.
 Задача дисперсионного анализа в проверке гипот Н0 о статист незачимости уравн регрессии в целом и показат тесн связи. Выполняется на основе сравнения факт и табличн значений F-крит кот определяются из соотн факторной и остаточной дисперсий, рассчитан на одну степень свободы
Задача дисперсионного анализа в проверке гипот Н0 о статист незачимости уравн регрессии в целом и показат тесн связи. Выполняется на основе сравнения факт и табличн значений F-крит кот определяются из соотн факторной и остаточной дисперсий, рассчитан на одну степень свободы
| таблица дисперсионного анализа | ||||
| Вару | df | СКО,S | Дисп на одну df,S2 | Fфакт |
 общ общ
| n-1 | dy 2* n | - | - |
| факт | m | dy 2* n*R2yx1x2 | 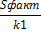
| 
|
| Ост | n-m-1 | dy 2* n*(1-R2yx1x2) =Sобщ-Sфакт | 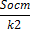
| - |
Также можно построить таблицу частного дисперсионного анализа, и найти частный F крит который оценивает целесообразность включения фактора в модель после включения др переменной
| Вариация у | df | S | S^2 |
| общая | df=n-1 | d2у*n | - |
| факторная | k1=m | d2у*n*R2 | Sфакт/k1 |
| в том числе: | |||
| за счет x2 | d2у*n*r2yx2 | Sфактx2/1 | |
| за счет доп включ. х1 | Sфакт-Sфактх2 | Sфактx1/1 | |
| Остаточная | k2=n-m | Sобщ-Sфакт |

24. Частный F-критерий Фишера, t- критерий Стьюдента. Их роль в построении регрессионных моделей.
F-критерия Фишера.
Для оценки статистич целесообразности добавления нов факторов в регрессион модель исп-ся частн критерий Фишера, т.к на рез-ты регрессион анализа влияет не только состав факторов, но и последовательность включения фактора в модель. Это обьясняется наличием связи между факторами.
Fxj =((R2 по yx1x2...xm – R2 по yx1x2…xj-1,хj+1…xm)/(1- R2 по yx1x2...xm))*((n-m-1)/1)
Fтабл (альфа,1, n-m-1) Fxj больше Fтабл – фактор xj целесообразно лючать в модель после др.факторов.
Если рассматривается уравнение y=a+b1x1+b2+b3x3+e, то определяются последовательно F-критерий для уравнения с одним фактором х1, далее F- критерий для дополнительного включения в модель фактора х2, т. е. для перехода от однофакторного уравнения регрессии к двухфакторному, и, наконец, F-критерий для дополнительного включения в модель фактора х3, т.е. дается оценка значимости фактора х3 после включения в модель факторов x1 их2. В этом случае F-критерий для дополнительного включения фактора х2 после х1 является последовательным в отличие от F-критерия для дополнительного включения в модель фактора х3, который является частным F- критерием, ибо оценивает значимость фактора в предположении, что он включен в модель последним. С t-критерием Стьюдента связан именно частный F- критерий. Последовательный F-критерий может интересовать исследователя настадии формирования модели. Для уравнения y=a+b1x1+b2+b3x3+e оценка значимости коэффициентов регрессии Ь1,Ь2,,b3 предполагает расчет трех межфакторных коэффициентов детерминации.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t -критерий Стьюдента и доверительные интервалы каждого из показателей.






 Сравнивая фактическое и критическое (табличное) значения t-статистики и tтабл. - принимаем или отвергаем гипотезу H0. Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством
Сравнивая фактическое и критическое (табличное) значения t-статистики и tтабл. - принимаем или отвергаем гипотезу H0. Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством
Если t табл.< tфакт., то H0 отклоняется, т.е. a, b и rху не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х.
Если, t табл.> tфакт. то гипотеза H0 не отклоняется и признается случайная природа формирования a, b или rху.
25. Оценка качества регрессионных моделей. Стандартная ошибка линии регрессии.
Оценка качества линейной регрессии: коэффициент детерминации R2
Из-за линейного соотношения  и
и  мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R2 (в парной линейной регрессии это величина r2, квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение 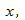 путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
26. Взаимосвязь частного F-критерия, t- критерия Стьюдента и частного коэффициента корреляции.
Ввиду корреляции м/у факторами значимость одного и того же фактора м/б различной в зависимости от последовательности его введения в модель. Мерой для оценки включения фактора в модель служит частый F-критерий, т.е. Fx i . В общем виде для фактора x i частый F-критерий определяется как:

Если рассматривается уравнение y=a+b1x1+b2+b3x3+e, то определяются последовательно F-критерий для уравнения с одним фактором х1, далее F-критерий для дополнительного включения в модель фактора х2, т. е. для перехода от однофакторного уравнения регрессии к двухфакторному, и, наконец, F-критерий для дополнительного включения в модель фактора х3, т. е. дается оценка значимости фактора х3 после включения в модель факторов x1 их2. В этом случае F-критерий для дополнительного включения фактора х2 после х1является последовательным в отличие от F-критерия для дополнительного включения в модель фактора х3, который является частным F-критерием, ибо оценивает значимость фактора в предположении, что он включен в модель последним. С t-критерием Стьюдента связан именно частный F-критерий. Последовательный F-критерий может интересовать исследователя на стадии формирования модели. Для уравнения y=a+b1x1+b2+b3x3+e оценка значимости коэффициентов регрессии Ь1,Ь2,,b3 предполагает расчет трех межфакторных коэффициентов детерминации, а именно:  ,
,  ,
,  и можно убедиться, что существует связьмежду собой t- критерия Стьюдента для оценки значимости bi и частным F-критерием:
и можно убедиться, что существует связьмежду собой t- критерия Стьюдента для оценки значимости bi и частным F-критерием:
 На основе соотношения bi и
На основе соотношения bi и 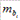 получим:
получим:


27. Варианты построения регрессионной модели. Их краткая характеристика.
28. Интерпретация параметров линейной и нелинейной регрессии.
| b | a | ||
| парная | линейная | Коэффициент регрессии b показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора х на единицу его измерения. Связь между у и х определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе – обратная | не интерпретируется, только знак >0 – рез-т изменяется медленнее фактора, <0 рез-т изм быстрее фактора |
| нелинейная | в степенной – коэфф эластичноести, т.е. на ск % изм рез-т в среднем при изменении фактора на 1% обратная ф-я – также как и в линейной, | не интерпретируется | |
| множ | линейная | В линейной множественной регрессии коэффициенты при хi характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменных значениях других факторов, закреплённых на среднем уровне | не интерпретируется |
29. Матрица парных и частных коэффициентов корреляции при построении регрессионных моделей.
30. Предпосылки метода наименьших квадратов.
Предпосылки метода наименьших квадратов (условия Гаусса-Маркова)
1. Математическое ожидание случайного отклонения равно нулю для всех наблюдений. Данное условие означает, что случайное отклонение в среднем не оказывает влияния на зависимую переменную. В каждом конкретном наблюдении случайный член может быть либо положительным, либо отрицательным, но он не должен иметь систематического смещения.
2. Дисперсия случайных отклонений постоянна для любых наблюдений. Это условие подразумевает, что несмотря на то, что при каждом конкретном наблюдении случайное отклонение может быть либо большим, либо меньшим, не должно быть некой априорной причины, вызывающей большую ошибку (отклонение).
Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсии отклонений).
3. Случайные отклонения ui и uj являются независимыми друг от друга для i¹j. Выполнимость данной предпосылки предполагает, что отсутствует систематическая связь между любыми случайными отклонениями. Другими словами, величина и определенный знак любого случайного отклонения не должны быть причинами величины и знака любого другого отклонения. Выполнимость данной предпосылки влечет следующее соотношение:
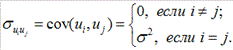
Поэтому, если данное условие выполняется, то говорят об отсутствии автокорреляции.
4. Случайное отклонение должно быть независимо от объясняющих переменных.
Обычно это условие выполняется автоматически, если объясняющие переменные не являются случайными в данной модели. Данное условие предполагает выполнимость следующего соотношения:

5. Модель является линейной относительно параметров.
Теорема Гаусса-Маркова. Если предпосылки 1-5 выполнены, то оценки, полученные по МНК, обладают следующими свойствами:
- Оценки являются несмещенными, то есть М(b0) = b0, М(b1) = b1, где b0, b1) – коэффициенты эмпирического уравнения регрессии, а b0, b1 – их теоретические прототипы. Это вытекает из первой предпосылки и говорит об отсутствии систематической ошибки в определении положения линии регрессии.
- Оценки состоятельны, так как дисперсия оценок параметров при возрастании числа n наблюдений стремится к нулю. Другими словами, при увеличении объема выборки надежность оценок увеличивается (коэффициенты теоретического и эмпирического уравнений регрессии практически совпадают).
- Оценки эффективны, то есть они имеют наименьшую дисперсию по сравнению с любыми оценками данных параметров, линейными относительно величин yi.
Если предпосылки 2 и 3 нарушены, то есть дисперсия отклонений непостоянна и (или) значения случайных отклонений связаны друг с другом, то свойства несмещенности и состоятельности сохраняются, но свойство эффективности – нет.
Наряду с выполнимостью указанных предпосылок при построении классических линейных регрессионных моделей делаются еще некоторые предположения. Например:
- объясняющие переменные не являются СВ;
- случайные отклонения имеют нормальное распределение;
- число наблюдений существенно больше числа объясняющих переменных.
ДРУГОЙ ВАРИАНТ БИЛЕТА 30.
Метод наименьших квадратов — один из методов регрессионного анализа для оценки неизвестных величин по результатам измерений, содержащих случайные ошибки.
МНК применяется также для приближённого представления заданной функции другими (более простыми) функциями и часто оказывается полезным при обработке наблюдений.
Когда искомая величина может быть измерена непосредственно, как, например, длина отрезка или угол, то, для увеличения точности, измерение производится много раз, и за окончательный результат берут арифметическое среднее из всех отдельных измерений. Это правило арифметической середины основывается на соображениях теории вероятностей; легко показать, что сумма квадратов уклонений отдельных измерений от арифметической середины будет меньше, чем сумма квадратов уклонений отдельных измерений от какой бы то ни было другой величины. Само правило арифметической середины представляет, следовательно, простейший случай метода наименьших квадратов.
МНК позволяет получить такие оценки параметров, при кот. сумма квадратов отклон-й фактич.значений результат. признака от теоретич. минимальна.
- модель д.б. линейной по параметрам
- х - случайная переменная
- значение ошибки – случайны, их изменения не образуют опред.модели (модели остатков)
- число налюденийд.б. больше чисоаоценив.парметров (в 5-6р)
- значения переменной х не д.б. одинаковыми
- совокупность должна быть однородной
- отсутствие взаимосвязи м/у ф-ром х и остатком
- модель регрессии д.б. корректно специфифированна
- в модели не д.б. тесной взаимосвязи м/у фак-ми (ля множ.регрессии)
Основные предпосылки МНК:
случайный характер остатков
нулевая средняя остатков, не зависящая от фактора x
гомоскедастичность (дисперсия каждого отклонения одинакова для всех значений x)
отсутствие автокорреляции остатков
остатки должны подчиняться нормальному распределению
Если регрессионная модель у = a + bх + E удовлетворяет условием Гаусса-Маркова, то оценки а и b, полученные на основе МНК имеют наилучшую дисперсию в классе всех линейных, несмещенных оценок.
31. Исследование остатков уравнения множественной регрессии.
Исследования остатков  предполагают проверку наличия следующих пяти предпосылок МНК:
предполагают проверку наличия следующих пяти предпосылок МНК:
1) случайный характер остатков;
2) нулевая средняя величина остатков, не зависящая от  ;
;
3) гомоскедастичность – дисперсия каждого отклонения , одинакова для всех значений  ;
;
4) отсутствие автокорреляции остатков – значения остатков распределены независимо друг от друга;
5) остатки подчиняются нормальному распределению.
Если распределение случайных остатков не соответствует некоторым предпосылкам МНК, то следует корректировать модель.
Прежде всего, проверяется случайный характер остатков – первая предпосылка МНК. С этой целью стоится график зависимости остатков от теоретических значений результативного признака (рис. 2.1). Если на графике получена горизонтальная полоса, то остатки представляют собой случайные величины и МНК оправдан, теоретические значения  хорошо аппроксимируют фактические значения
хорошо аппроксимируют фактические значения  .
.
32. Гетероскедастичность и ее учет при построении модели множественной регрессии. Качественная оценка гретероскедастичности.
Гетероскедастичность проявляется, если совокупность исходных данных включает качественно разнородные области. Гетероскедастичность означает неравную дисперсию остатков для разных значений x. Если имеет место гетероскедастичность, то:
- Оценки МНК будут неэффективными.
- Могут быть смещены оценки коэфф регрессии и они будут неэффективными.
- Сложно исп формулу станд ошибок, т.к она предполаг единую дисперсию остатков.
| Проявление гетероскедастичности: - низкое значение коэффициента детерминации - станд ошибка занижена - низкое значение t-критерия - широкие доверительные интервалы | Меры по устранению: увеличение числа наблюдений - изменение функциональной формы модели - разделение совокупности на качественно однородные группы и проведение анализа в каждой группе - использование фиктивных переменных, учитывающих неоднородность - исключение из совокупности единиц, дающих неоднородность |
Меры по устранению гетероскедастичности
p Увеличениечисланаблюдений
p Изменениефункциональнойформымодели
p Разделениеисходнойсовокупностинакачественно-однородныегруппы и проведениеанализа в каждойгруппе
p Использованиефиктивныхпеременных, учитывающихнеоднородность
p Исключениеизсовокупностиединиц, дающихнеоднородность
Тесты, используемыедлявыявлениягетероскедастичности
p Гольдфельда-Квандта
p Парка
p Глейзера
p Уайта
p РанговойкорреляцииСпирмена
33. Автокорреляция остатков и ее роль при построении регрессионной модели.
Зависимость между последовательными уровнями врем. ряда называют автокорреляцией уровня ряда. В эконометрич. исследованиях часто возникают и такие ситуации, когда дисперсия остатков постоянная, но наблюдается их ковариация. Это явление называют автокорреляцией остатков.
Один из наиболее распространенных методов определения автокорреляции в остатках – критерий Дарбина-Уотсона:
d =  ;
;
d – отношение суммы квадратов разностей последовательных значений к остаточной сумме квадратов по модели регрессии.
Сущ-ет след. соотношение между критерием Д-У «d» и коэф-ом автокорреляции остатков 1ого порядка r1:
d = 2 * (1-r1).
Если в остатках сущ-ет полная положит. автокорреляция и r1 = 1, то d = 0.
Если в остатках полная отриц. автокорреляция, то r1 = -1 и d = 4.
Если автокорреляция отсутствует, то r1 = 0 и d = 2.
Т.е. 0≤d≤4.
Рассмотрим алгоритм выявления автокорреляции остатков на основе критерия Д-У.
Выдвигается гипотеза H0 об отсутствии автокорреляции остатков. Альтернативные гипотезы H1 и H1* предполагают наличие положительной или отрицательной автокорреляции в остатках. Затем по спец. таблицам определяются критические значения критерия Дарбина — Уотсона dL и du для заданного числа наблюдений n, числа независимых переменных модели k при уровня значимости ɑ (обычно 0,95). По этим значениям промежуток [0;4] разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью (1-ɑ) представлено на след: рисунке:
| Есть положит. автокорреляция остатков. Н0 отклоняется. С вер-тью Р=1-ɑ принимается Н1. | Зона неопределенности. | Нет оснований отклонять Н0 (автокорреляция остатков отсутствует). | Зона неопределенности. | Есть отриц. автокорреляция остатков. Н0 отклоняется. С вер-тью Р=1-ɑ принимается Н1. | ||||||||
| dL | du | 4- du | 4- dL | |||||||||
| + есть | ? | НЕТ | ? | - есть | ||||||
| dL | du | 4- du | 4- dL | |||||||
Если фактич. значение критерия Дарбина - Уотсона попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и гипотезу Н0 отклоняют.
34. Выбор наилучшего варианта модели регрессии.


35. Нелинейные модели множественной регрессии, их общая характеристика.
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы 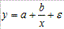 , параболы второй степени
, параболы второй степени 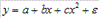 и д.р.
и д.р.
Различают два класса нелинейных регрессий:
• регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
• регрессии, нелинейные по оцениваемым параметрам.
Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
- полиномы разных степеней
- равносторонняя гипербола
К нелинейным регрессиям по оцениваемым параметрам относятся функции:
- степенная
- показательная
- экспоненциальна я
36. Модели гиперболического типа. Кривые Энгеля, кривая Филипса, и другие примеры использования моделей данного типа.
Кривые Энгеля (Engel curve) иллюстрируют зависимость между объемом потребления благ (C) и доходом потребителя (I) при неизменных ценах и предпочтениях. Названа в честь немецкого статистика Эрнста Энгеля, занимавшегося анализом влияния изменения дохода на структуру потребительских расходов.

|
| Кривые Энгеля |
На оси абсцисс откладывается уровень дохода потребителя, а на оси ординат — расходы на потребление данного блага.
На графике показан примерный вид кривых Энгеля:
- E1 — кривая для нормальных товаров;
- E2 — кривая для предметов роскоши;
- E3 — кривая для низкокачественных товаров.
Кривая филипса отражает взаимосвязь между темпами инфляции ибезработицы.
Кейнсианская модель экономики показывает, что в экономике может возникнуть либо безработица (вызванная спадом производства, следовательно уменьшением спроса на рабочую силу), либо инфляция (если экономика функционирует в состоянии полной занятости).
Одновременно высокая инфляция и высокая безработица существовать не могут.

Кривая Филипса была построена А.У. Филлипсом на основе данных заработной платы и безработицы в Великобритании за 1861-1957 годы.
Следуя кривой Филлипса государство может выстроить свою экономическую политику. Государство с помощью стимулирования совокупного спроса может увеличить инфляцию и снизить безработицу и наоборот.
Кривая Филипса была полностью верна до середины 70х годов. В этот период случилась стагнация (одновременный рост инфляции и безработицы), которую кривая филипса не смогла объяснить.
Применение Кривой Филипса
Кривая Филипса применяется для построения кривой совокупного предложения. Совокупное предложение выражает зависимость реального объема выпуска от уровня цен. А объем производства напрямую зависит от числа занятых в эконо