Лин регрессия сводится к нахождению уравнения вида y=a+bx+e графически вид: имеет широкое применения в связи с легкостью интерпретации ее параметров параметры  a=
a= 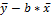
Уравн регрессии всегда дополняется показат тесноты связи. Для линейной функции таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:

Линейный коэффициент корреляции принимает значения от –1 до +1. Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 < rxy < 0.3: слабая;
0.3 0,3< rxy < 0.5: умеренная;
0.5 < rxy < 0.7: заметная;
0.7 < rxy < 0.9: высокая;
0.9 < rxy < 1: весьма высокая; для удобства расчетов:
 , где dy – общая дисперсия, b*dх – факт дисперсия а rxy2- Квадрат коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.(%)
, где dy – общая дисперсия, b*dх – факт дисперсия а rxy2- Квадрат коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.(%)
8.предпосылки МНК
При оценке параметров применяется МНК при этом делаются определенные предпосылки касаемо случ составл e в модели y=a+bx+e e= уфакт-утеор при измен специфик могут меняться, поэтому в звдвчу регр анализа входит также исследование случ остатков e после постр уравн регр проводтся проверка наличия у случ остатков св-в: несмещенность (мат.ожидание =0, если несм.то их можно сравнивать) эффективность (характеризуются наименьшей дисперсией) состоятельность (увеличение точности с увел выборки)
Условия для получения несмещенных,эффективных,состоятельных оценок представляют собой предпосылки МНК:1) случ характер остатков (график зависимости остатков от теор значений, если случайны– мнк оправдан)
2)средняя величина остатков=0, не зависит от х(график зависимости e от х, если зависят модель не адекватна)
3)дисперсия остатков гомоскедастична(для каждого х остатки e имеют одинаковую дисперсию, можно увидеть из поля корреляции) 4)отсутствие автокорреляции остатков(значения остатков e распределены независимо друг от друга) для этого рассчитывается коэфф авткорр остатков  если сильно отличен от 0 то оценки состоятельны и эффективны) при несоблюдении основных предпосылок необходимо менять спецификацию, добавлять и исключать факторы, преобразовывать данные для получения оценок коэфф регрессии которые обладают св-м несмещенности, имеют меньшее значение дисперсии остатков и обеспеч более эфф стат проверку
если сильно отличен от 0 то оценки состоятельны и эффективны) при несоблюдении основных предпосылок необходимо менять спецификацию, добавлять и исключать факторы, преобразовывать данные для получения оценок коэфф регрессии которые обладают св-м несмещенности, имеют меньшее значение дисперсии остатков и обеспеч более эфф стат проверку
9. оценка существенности параметров линейной регрессии и корреляции t-критерий и его связь с F-критерием
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стьюдента. Чтобы проверить, значимы ли параметры, т.е. значимо ли они отличаются от нуля, выдвигается гипотиза H0 и проверяется на основе сравнения табличного значенияс фактическим.Для расчета значимости параметра b и нахождения t-критерия рассчитывается его ст ошибка  величина ошибки совместно с t-критерием стьюдента исп для проверки существенности коэфф регрессии b, где его величина сравнивается с его ст ошибкой т.е опред tфакт
величина ошибки совместно с t-критерием стьюдента исп для проверки существенности коэфф регрессии b, где его величина сравнивается с его ст ошибкой т.е опред tфакт

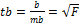 сравнивается с tтабл если больше табличного значения tкрит (n-m-1;α/2) – то коэффициент регрессии/параметр b является существенным и значимым
сравнивается с tтабл если больше табличного значения tкрит (n-m-1;α/2) – то коэффициент регрессии/параметр b является существенным и значимым
Значимость коэфф корр на основе величины ошибки  tr=tb=
tr=tb= 
10.Интервалы прогноза по линейному уравнению регрессии
В прогнозных расчетах по ур регрессии опред упредск путем подстановки х в уравнение, но точечный прогноз явно нереален поэтому рассчитывается ст ошибка упредск и интервальн оценка прогнозного значения у*
Утеор-myтеор£у*£утеор+ myтеор
Подставив знач а в уравн регрессии видим что ст ошибка утеор зависит от ошибки уср и ошибки b

¯

Эта формула ст ошибки при заданном значении xp характ ошибку полож линии регрессии величина ош мин, когда хср=хр и возр по мере того как удаляется от хср
Для упрогн интервал: 

11. Нелинейная регрессия и корреляция
Если между эк явл существуют нелин соотн, то они выраж с помощью соотв нелинейных ф-й. Различают два класса нелинейных регрессий:1. Регрессии, нелинейные относительно включенных в анализ
объясняющих переменных, но линейные по оцениваемым параметрам,
например
– полиномы различных степеней yx = a + bx + cx2,
равносторонняя гипербола – y=a+b/x
полулогарифм ф-ии y=a+b*lnx
2. Регрессии, нелинейные по оцениваемым параметрам, например
– степенная – y = axb;
– показательная – y = a b x;
– экспоненциальная – y = ea+bx.
Регрессии нелин по вкл переменным приводятся к лин виду простой заменой переменных, а дальнейшая оценка параметров производится с помощью МНК. Парабола второй степени y = a + bx + cx2 приводится к линейному виду с помощью замены:
x1 = x, x2 = x2. В результате приходим к двухфакторному уравнению
y Х 1 2 = a + b × x1 + c × x2
Равносторонняя гипербола y = a + b/x гипербола приводится к линейному уравнению простойзаменой: z = 1/ x Аналог способом замены приводятся др функции Несколько иначе обстоит дело с регрессиями нелинейными пооцениваемым параметрам, которые делятся на два типа: нелинейные моделивнутренне линейные (приводятся к линейному и модели внутренне нелинейные (к линейному виду не приводятся).К внутренне линейным моделям относятся, например, Степенная Y(X)=A0*X1A1*X2A2*…*XKAK Показательная Y(X)=eA0+A1*X1+A2*X2+…+Ak*Xk обратная  . Для оценки параметров функции линеаризируются путем логарифмирования и для МНК применяются уже преобразованные данные, после этого функция потенцируется. Для оценки тесноты связи нелинейной регрессии служит индекс корреляции:
. Для оценки параметров функции линеаризируются путем логарифмирования и для МНК применяются уже преобразованные данные, после этого функция потенцируется. Для оценки тесноты связи нелинейной регрессии служит индекс корреляции:  принимает значения от –1 до +1. Связи между признаками могут быть 0<слабыми <0,3 и 0,8<сильными (тесными) Квадрат Рху – индекс детерминации, доля дисперсии у обьясн регрессией в доле общ дисперсии. Инд дет можно сравнить с коэф дет для обоснования возможности применения лин функции чем больше кривизна линии тем r<p,близость показ говорит о том, что можно исп лин ф-ю и не сложнять модель.индекс дет можно исп для проверки сущ уравн регр по F-крит 12.Средняя ошибка аппроксимации факт значения у отличаются от теоретических и чем меньше это отличие тем лучше качество модели. Величина отклон у факт от у теорет по каждому набл – ошибка аппроксимации, их число соотв обьему совок
принимает значения от –1 до +1. Связи между признаками могут быть 0<слабыми <0,3 и 0,8<сильными (тесными) Квадрат Рху – индекс детерминации, доля дисперсии у обьясн регрессией в доле общ дисперсии. Инд дет можно сравнить с коэф дет для обоснования возможности применения лин функции чем больше кривизна линии тем r<p,близость показ говорит о том, что можно исп лин ф-ю и не сложнять модель.индекс дет можно исп для проверки сущ уравн регр по F-крит 12.Средняя ошибка аппроксимации факт значения у отличаются от теоретических и чем меньше это отличие тем лучше качество модели. Величина отклон у факт от у теорет по каждому набл – ошибка аппроксимации, их число соотв обьему совок  относ ошибка.чтобы судить о кач-ве модели необх рассчитать среднюю ош апрокс ош апрокс в пределах 5-7% свид о хорошем подборе модели
относ ошибка.чтобы судить о кач-ве модели необх рассчитать среднюю ош апрокс ош апрокс в пределах 5-7% свид о хорошем подборе модели
12. Средняя ошибка аппроксимации и ее роль в эконометрическом исследовании. УЧЕБНИК СТР 106
Для оценки качества однофакторной модели в эконометрике используют коэффициент детерминации и среднюю ошибку аппроксимации. Средняя ошибка аппроксимации определяется как среднее отклонение полученных значений от фактических.
Показатель средней ошибки аппроксимации рассчитывается по формуле:

Если величина данного показателя составляет менее 6-7%, то качество построенной модели регрессии считается хорошим. Максимально допустимым значением показателя средней ошибки аппроксимации считается 12-15 %.