I. Понятие сортировки
Сортировка - перестановка элементов в подмножестве данных по какому-либо критерию. Чаще всего в качестве критерия используется некоторое числовое поле, называемое ключевым.
Цель сортировки — облегчить последующий поиск элементов в отсортированном множестве при обработке данных.
Все алгоритмы сортировки делятся на:
· алгоритмы внутренней сортировки (сортировка массивов);
· алгоритмы внешней сортировки (сортировка файлов).
Внутренняя сортировка оперирует массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно упорядочиваются на том же месте без дополнительных затрат. (Примечание: В современных архитектурах персональных компьютеров широко применяется подкачка и кэширование памяти. Алгоритм сортировки должен хорошо сочетаться с применяемыми алгоритмами кэширования и подкачки).
Внутренняя сортировка – это алгоритм сортировки, который в процессе упорядочивания данных использует только оперативную память (ОЗУ) компьютера.
Внешняя сортировка – это алгоритм сортировки, который при проведении упорядочивания данных использует внешнюю память, как правило, жесткие диски. Внешняя сортировка разработана для обработки больших списков данных, которые не помещаются в оперативную память. Обращение к различным носителям накладывает некоторые дополнительные ограничения на данный алгоритм: доступ к носителю осуществляется последовательным образом, то есть в каждый момент времени можно считать или записать только элемент, следующий за текущим; объем данных не позволяет им разместиться в ОЗУ.
Внешняя сортировка – это алгоритм сортировки, который при проведении упорядочивания данных использует внешнюю память, как правило, жесткие диски.
Метод «Разделяй и властвуй» (англ. divide and conquer) в информатике — важная парадигма разработки алгоритмов, заключающаяся в рекурсивном разбиении решаемой задачи на две или более подзадачи того же типа, но меньшего размера, и комбинировании их решений для получения ответа к исходной задаче; разбиения выполняются до тех пор, пока все подзадачи не окажутся элементарными.
II. Методы сортировки
A. Внутренние сортировки
I. Сортировка слиянием
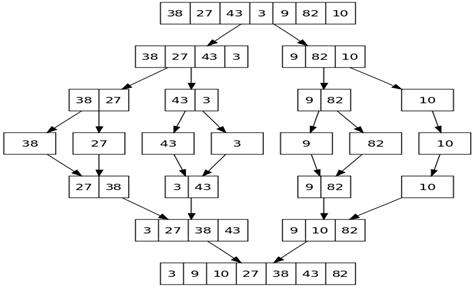
Сортировка слиянием (англ. merge sort) — алгоритм сортировки, который упорядочивает списки (или другие структуры данных, доступ к элементам которых можно получать только последовательно) в определённом порядке.
Для решения задачи сортировки эти три этапа выглядят так:
- Сортируемый массив разбивается на две части примерно одинакового размера;
- Каждая из получившихся частей сортируется отдельно, например — тем же самым алгоритмом;
- Два упорядоченных массива половинного размера соединяются в один.
1.1. — 2.1. Рекурсивное разбиение задачи на меньшие происходит до тех пор, пока размер массива не достигнет единицы (любой массив длины 1 можно считать упорядоченным).
3.1. Соединение двух упорядоченных массивов в один.
Основную идею слияния двух отсортированных массивов можно объяснить на следующем примере. Пусть мы имеем два уже отсортированных по неубыванию подмассива. Тогда:
3.2. Слияние двух подмассивов в третий результирующий массив.
На каждом шаге мы берём меньший из двух первых элементов подмассивов и записываем его в результирующий массив. Счётчики номеров элементов результирующего массива и подмассива, из которого был взят элемент, увеличиваем на 1.
3.3. «Прицепление» остатка.
Когда один из подмассивов закончился, мы добавляем все оставшиеся элементы второго подмассива в результирующий массив.
Реализация на С++ (сортировка по возрастанию):
const int nmax = 1000;
void Merge(int* arr, int begin, int end)
{
int i = begin,
t = 0,
mid = begin + (end - begin) / 2,
j = mid + 1,
d[nmax];
while (i <= mid && j <= end) {
if (arr[i] <= arr[j]) {
d[t] = arr[i]; i++;
}
else {
d[t] = arr[j]; j++;
}
t++;
}
while (i <= mid) {
d[t] = arr[i]; i++; t++;
}
while (j <= end) {
d[t] = arr[j]; j++; t++;
}
for (i = 0; i < t; i++)
arr[begin + i] = d[i];
}
void MergeSort(int *arr, int left, int right)
{
int temp;
if (left<right)
if (right - left == 1) {
if (arr[right]<arr[left]) {
temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
else {
MergeSort(arr, left, left + (right - left) / 2);
MergeSort(arr, left + (right - left) / 2 + 1, right);
Merge(arr, left, right);
}
}
Достоинства:
· Работает даже на структурах данных последовательного доступа.
· Хорошо сочетается с подкачкой и кэшированием памяти.
· Неплохо работает в параллельном варианте: легко разбить задачи между процессорами поровну, но трудно сделать так, чтобы другие процессоры взяли на себя работу, в случае если один процессор задержится.
· Не имеет «трудных» входных данных.
· Устойчивая - сохраняет порядок равных элементов (принадлежащих одному классу эквивалентности по сравнению).
Недостатки:
· На «почти отсортированных» массивах работает столь же долго, как на хаотичных.
· Требует дополнительной памяти по размеру исходного массива.
ii. Пирамидальная сортировка
Пирамидальная сортировка (Heapsort, сортировка кучей) подходит для работы с полными бинарными деревьями в массиве. В ней используется структура данных, называемая кучей. Пирамида (сортирующее дерево, двоичная куча) – это двоичное дерево с упорядоченными листьями, в корне которого расположен максимальный или минимальный элемент. Пирамидой (кучей) называется двоичное дерево такое, что
a[i] ≤ a[2i+1];
a[i] ≤ a[2i+2].
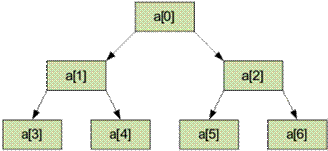
Общая идея пирамидальной сортировки заключается в том, что сначала строится пирамида из элементов исходного массива, а затем осуществляется сортировка элементов. Алгоритм основан на одном из свойств кучи — в голове (или вершине) кучи находится самый (максимальный) элемент. Просеивание – это построение новой пирамиды посредством спуска вниз элемента из вершины дерева в соответствии с ключом сортировки
Алгоритм
1. Построим из требуемого массива кучу
2. Меняем местами первый и последний элемент в куче
3. Уменьшаем размер рассматриваемой кучи на 1
4. Вызвать процедуру нормализации кучи в корне кучи
5. Вернуться в шаг 2 и продолжать выполнять алгоритм, пока куча имеет больше одного элемента
Выполнение алгоритма разбивается на два этапа.
1 этап Построение пирамиды.
2 этап Сортировка на построенной пирамиде.
Реализация на С++ (сортировка по возрастанию):
// Функция "просеивания" через кучу - формирование кучи
void siftDown(int *numbers, int root, int bottom)
{
int maxChild; // индекс максимального потомка
int done = 0; // флаг того, что куча сформирована
// Пока не дошли до последнего ряда
while ((root * 2+1 <= bottom) && (!done))
{
if (root * 2+1 == bottom) // если мы в последнем ряду,
maxChild = root * 2; // запоминаем левый потомок
// иначе запоминаем больший потомок из двух
else if (numbers[root * 2+1] > numbers[root * 2 + 2])
maxChild = root * 2+1;
else
maxChild = root * 2 + 2;
// если элемент вершины меньше максимального потомка
if (numbers[root] < numbers[maxChild])
{
int temp = numbers[root]; // меняем их местами
numbers[root] = numbers[maxChild];
numbers[maxChild] = temp;
root = maxChild;
}
else // иначе
done = 1; // пирамида сформирована
}
}
// Функция сортировки на куче
void heapSort(int *numbers, int array_size)
{
// Формируем нижний ряд пирамиды
for (int i = (array_size / 2) - 1; i >= 0; i--)
siftDown(numbers, i, array_size);
// Просеиваем через пирамиду остальные элементы
for (int i = array_size - 1; i >= 1; i--)
{
int temp = numbers[0];
numbers[0] = numbers[i];
numbers[i] = temp;
siftDown(numbers, 0, i - 1);
}
}
Iii. Метод Хоара
Сортировка Хоара – это одна из разновидностей быстрых сортировок, основанная на упорядочивании подмножеств массива относительно опорных элементов.
Быстрая сортировка, сортировка Хоара (англ. quicksort), часто называемая qsort (по имени в стандартной библиотеке языка Си) — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром во время его работы в МГУ в 1960 году.
Один из самых быстрых известных универсальных алгоритмов сортировки массивов: в среднем O(n\log n) обменов при упорядочении n элементов.
На входе массив a[0]...a[N] и опорный элемент x, по которому будет производиться разделение.
1. Введем два указателя: i и j. В начале алгоритма они указывают, соответственно, на левый и правый конец последовательности.
2. Будем двигать указатель i с шагом в 1 элемент по направлению к концу массива, пока не будет найден элемент a[i] >= x. Затем аналогичным образом начнем двигать указатель j от конца массива к началу, пока не будет найден a[j] <= x.
3.  Далее, если i <= j, меняем a[i] и a[j] местами и продолжаем двигать i,j по тем же правилам...
Далее, если i <= j, меняем a[i] и a[j] местами и продолжаем двигать i,j по тем же правилам...
4. Повторяем шаг 3, пока i <= j.
Реализация на С++:
void qs(int* s_arr, int first, int last)
{
int i = first, j = last, x = s_arr[(first + last) / 2];
do {
while (s_arr[i] < x) i++;
while (s_arr[j] > x) j--;
if(i <= j) {
if (s_arr[i] > s_arr[j]) swap(s_arr[i], s_arr[j]);
i++;
j--;
}
} while (i <= j);
if (i < last)
qs(s_arr, i, last);
if (first < j)
qs(s_arr, first, j);
}