Отладка грамматики – это процесс преобразования грамматики к виду, удовлетворяющему используемый метод синтаксического анализа.
В исходной грамматике 42 конфликта. Среди них встречаются конфликты трех типов:
Конфликты типа =<
 |

| uslovie | |
| ( | =< |
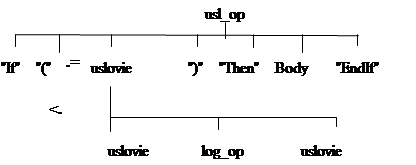
Рис. 13. Конфликт типа =<
Для того, чтобы показать как отладить этот конфликт, рассмотрим его на примере:
Из рисунка 3.13 видно, что между терминальным символом «(» и нетерминальным uslovie конфликт типа =<. Чтобы его отладить необходимо опустить нетерминал uslovie вниз по дереву.
Таким образом, между символами «(» и uslovie осталось только отношение <.
Все остальные конфликты этого типа разрешаются аналогично.
Конфликт типа =>
Чтобы показать как разрешаются конфликты этого типа, разрешим конфликт между символами Вody и Еnd. Этот конфликт изображен на рисунке 15.

| End | |
| Вody | => |
Рис. 15. Конфликт типа =>
Синтаксический анализ
В процессе синтаксического анализа требуется для нескольких предложений входного языка построить синтаксическое дерево, провести синтаксический разбор методом простого предшествования.
Задачи синтаксического анализатора:
1) выделение синтаксических единиц;
2) определение всех синтаксических ошибок (если они есть);
3) преобразование таблицы стандартных символов (ТСС) в некоторую внутреннюю форму представления программы(ВФПП).
Схема программы синтаксического анализатора
Схема программы синтаксического анализа методом простого предшествования приведена в графическом приложении (лист1).
Принятые обозначения:
X – массив символов анализируемой цепочки;
MP – матрица простого предшествованя;
P – множество правил грамматики, которые описывают язык;
ST – стек для определения хвоста основы;
ST1 – стек для определения головы основы;
TL – текущая литера;
NTL – номер текущей литеры;
OSN – массив, в котором будет накапливаться основа;
NOSN – количество символов в массиве OSN (текущее количество символов в основе);
A->, где – правая часть правила, которая совпадает с массивом OSN, A – левая часть правила, на которую заменяется основа;
REZ – результат.
Чтобы выделить основу необходимо сначала найти конец основы, а затем ее начало, после чего выделяется основа (блоки J2 – O8).
Если после выделения строки OSN находится правило, у которого правая часть правила совпадает с OSN то, переменной REZ присваивается 1, если такого правила нет – ошибка, синтаксический анализ может быть прекращен или нужно исправить ошибку (блок R8).
Операции выполняемые над строковыми переменными:
st.push(i) – поместить элемент i в стек;
st.pop() – удалить элемент из стека;
st.top() – получить доступ к вершине стека;
st.nst() – определить количество элементов в стеке.
Работа данного алгоритма представлена в таблице синтаксического анализа в графическом приложении (лист1).
Заключение
В процессе выполнения курсовой работы были разработаны синтаксический и лексический анализаторы, семантические процедуры для сканера, а также был разработан алгоритм, реализующий синтаксический анализ методом простого предшествования. В целом язык оправдал надежды, возложенные на него в начале работы, и получился довольно стройным и гибким.