Любое статистическое исследования состоит из шести этапов.
Этап 1. Статистическое исследование начинается с формирования первичной статистической информационной базы по выбранному комплексу показателей.
Этап 2. Первичное обобщение и группировка статистических данных.
- Сводки, группировки, гистограммы, полигоны, кумуляты (огивы), графики распределения частот (частостей).
- Формирование рядов динамики и их первичный анализ. Графический прогноз (с концепцией "оптимист", "пессимист", "реалист").
- Расчет моментов К-го порядка (средних, дисперсий, мер скошенности, измерения эксцесса) с целью определения показателей центра расширения показателей вариации, показателей скошенности (асимметрии), показателей эксцесса (островершинности).
- Формирование и первичные расчеты сложных статистических показателей (относительных, сводных многоуровневых).
- Формирование и первичные расчеты индексных показателей.
Этап 3. Следующий этап статистического исследования включает экономическую интерпретацию первичного обобщения.
Этап 4. Компьютерный анализ первичных и обобщенных расширенных (объемных) статистических данных.
Этап 5. Компьютерное прогнозирование по выбранным наиболее важным направлениям.
Этап 6. Обобщенный анализ полученных результатов и проверка их на достоверность по статистическим критериям. Этап 7. Завершающим этапом статистического исследования является принятие управленческого решения.
70. Одной из задач, которые стоят перед исследователем при проведении исследования, является сбор необходимых эмпирических данных об объекте исследования. Множество элементов, составляющих объект исследования, называют генеральной совокупностью (ГС). Наиболее простым, на первый взгляд, способом сбора данных является сплошное обследование ГС. Однако применение сплошного обследования не всегда представляется возможным. В этом случае применяется выборочное обследование. Суть выборочного метода заключена в том, что обследованию подвергается только часть элементов ГС, которая называется выборочной совокупностью (ВС). Выборочный метод позволяет не только сократить временные и материальные затраты на проведения исследования, но и повысить достоверность результатов исследования. Кроме того, выборочный метод имеет более широкую область применения. Широта области применения выборочного метода объясняется тем, что небольшой (по сравнению с ГС) объем выборки позволяет использовать более сложные методы обследования, включая использование различных технических средств (например, видео- и аудиосредства, персональные компьютеры и Интернет, а также сложную измерительную технику).
71. Основа выборки - это описание (перечень) всех единиц наблюдения исходной совокупности, который используется для отбора единиц отбора и наблюдения. Чаще всего понятие применяется к ед. наблюдения.
Основы бывают трех видов:
1. основы, созданные для неисследовательских целей и задач;
2. специально созданные основы (применяются крайне редко);
3. готовые основы, дорабатываемые для исследования (натуробход избирательных участков): банки адресов, списки данных о работниках предприятий, базы данных абонентов телефонных сетей, списки избирателей и т.п.
Основы выборки должны обладать следующими свойствами:
· полнотой (наличие всех единиц исходной совокупности)
· точность (отсутствие дублирования и несущ-х единиц)
· удобство, доступность
· адекватность в соответствии с целями и задами СИ
Чаще всего за основу берутся: списки избирательных участков и избирателей, различные банки адресов, телефонные базы.
72. Ошибки регистрации образуются вследствие неправильного установления фактов в процессе наблюдения, или ошибочной их записи, или того и другого вместе.
Ошибки представительности (репрезентативности) свойственны только несплошному наблюдению (обследование только части единицы совокупности). Отклонение величины изучаемого признака в отобранной для обследования части совокупности от его величины во всей совокупности, называются ошибкой репрезентативности.
73. Для проведения социологического исследования недостаточно просто определить объект исследования. Нерационально опрашивать всех людей, составляющих объект исследования (иногда это могут быть тысячи людей). На это уйдет много времени. Поэтому обычно социологические исследования имеют не сплошной, а выборочный характер. То есть по определенным и строгим правилам исследователь отбирает небольшое (относительно всего объема выборки) число людей, которые по своим социально-демографическим признакам и другим каким-то характеристикам полностью соответствуют структуре изучаемого объекта. Эта операция носит название «выборка». Математики и статистики вывели формулу для определения объема выборки:
n = сигма в квадрате х на t в квадрате / дельта в квадрате
Где n — объем выборки:
сигма — дисперсия, или мера рассеивания исследуемого признака; в генеральной совокупности (степень однородности исследуемых единиц наблюдения);
t — коэффициент доверия (заданная точность);
дельта — предельная ошибка выборки.
74. Предельные теоремы теории вероятностей позволяют определять размер случайных ошибок выборки. Различают среднюю (стандартную) и предельную ошибку выборки. Под средней (стандартной) ошибкой выборки понимают расхождение между средней выборочной и генеральной совокупностей. Предельной ошибкой выборки принято считать максимально возможное расхождение, т. е. максимум ошибки при заданной вероятности ее появления.
В математической теории выборочного метода сравниваются средние характеристики признаков выборочной и генеральной совокупностей и доказывается, что с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются. Чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик. На основании теоремы, доказанной П. Л. Чебышевым, величину средней (стандартной) ошибки повторной простой случайной выборки при достаточно большом объеме выборки (n) можно определить по формуле:
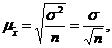
где 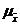 - стандартная ошибка.
- стандартная ошибка.
Из этой формулы средней (стандартной) ошибки повторной простой случайной выборки видно, что величина зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
75. https://www.ekozona.ru/statistika/1339-tri-vida-stratificirovannoj-vyborki.html
77. Под малой выборкой понимается такое выборочное наблюдение, численность единиц которого не превышает 30.
При оценке результатов малой выборки величина генеральной дисперсии в расчетах не используется. Для определения возможных пределов ошибки пользуются так называемым критерием Стьюдента:
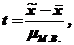 где
где 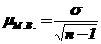 . – мера случайных колебаний выборочной средней в малой выборке.
. – мера случайных колебаний выборочной средней в малой выборке.
Величина σ вычисляется на основе данных выборочного наблюдения:
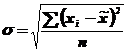
Предельная ошибка малой выборки рассчитывается аналогичным образом:

Но, в данном случае, вероятная оценка зависит не только от величины t, но и от объема выборки. Величина коэффициента доверия t при различных объемах малой выборки представлена в таблице 9.3.
78. При серийной выборке величина ошибки выборки зависит не от числа исследуемых единиц, а от числа обследованных серий (s) и от величины межгрупповой дисперсии:
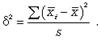
Серийная выборка, как правило, проводится как бесповторная, и формула ошибки выборки в этом случае имеет вид 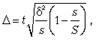 где
где 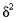 - межсерийная дисперсия; s - число отобранных серий; S - число серий в генеральной совокупности.
- межсерийная дисперсия; s - число отобранных серий; S - число серий в генеральной совокупности.
79. ДИСПЕРСИОННЫЙ АНАЛИЗ [variance analysis] — раздел математической статистики, посвященный методам выявления влияния отдельных факторов на результат эксперимента (физического, производственного, экономического эксперимента). Д. а. возник как средство обработки результатов агрономических опытов, с помощью которых выявлялись наиболее благоприятные условия для сортов сельскохозяйственных культур.
При этом исходят из положения о том, что существенность фактора в определенных условиях характеризуется его вкладом в дисперсию результата. Английский статистик Р. Фишер, разработавший этот метод, определил его как “отделение дисперсии, приписываемой одной группе причин, от дисперсии, приписываемой другим группам”16.
Анализ производится следующим образом. Сначала группируют совокупность наблюдений по факторному признаку, находят среднее значение результата и дисперсию по каждой группе. Затем определяют общую дисперсию и вычисляют, какая доля ее зависит от условий, общих для всех групп, какая — от исследуемого фактора, а какая — от случайных причин. И наконец, с помощью специального критерия определяют, насколько существенны различия между группами наблюдений и, следовательно, можно ли считать ощутимым влияние тех или иных факторов.
Д. а. применяется в планировании эксперимента и в ряде областей экономических исследований, где он служит, в частности, предварительным этапом к регрессионному анализу статистических данных, поскольку позволяет выделить относительно небольшое (но достаточное для целей исследования) количество параметров регрессии
80. Для этих выборок предполагают, что они имеют разные выборочные средние и одинаковые выборочные дисперсии. Поэтому необходимо ответить на вопрос, оказал ли этот фактор существенное влияние на разброс выборочных средних или разброс является следствием случайностей, вызванных небольшими объемами выборок. Другими словами если выборки принадлежат одной и той же генеральной совокупности, то разброс данных между выборками (между группами) должен быть не больше, чем разброс данных внутри этих выборок (внутри групп).
81. Пусть 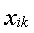 – i – элемент (
– i – элемент (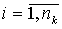 )
) 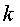 -выборки (
-выборки ( ), где m – число выборок, n k – число данных в -выборке. Тогда
), где m – число выборок, n k – число данных в -выборке. Тогда 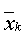 – выборочное среднее -выборки определяется по формуле
– выборочное среднее -выборки определяется по формуле
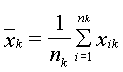 .
.
Общее среднее вычисляется по формуле
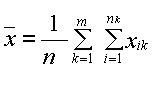 , где
, где 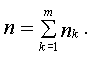
Основное тождество дисперсионного анализа имеет следующий вид:
 ,
,
где Q 1 – сумма квадратов отклонений выборочных средних  от общего среднего
от общего среднего 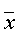 (сумма квадратов отклонений между группами); Q 2 – сумма квадратов отклонений наблюдаемых значений
(сумма квадратов отклонений между группами); Q 2 – сумма квадратов отклонений наблюдаемых значений 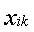 от выборочной средней (сумма квадратов отклонений внутри групп); Q – общая сумма квадратов отклонений наблюдаемых значений от общего среднего
от выборочной средней (сумма квадратов отклонений внутри групп); Q – общая сумма квадратов отклонений наблюдаемых значений от общего среднего  .
.
Расчет этих сумм квадратов отклонений осуществляется по следующим формулам:
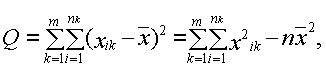


В качестве критерия необходимо воспользоваться критерием Фишера:
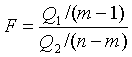 .
.
Если расчетное значение критерия Фишера будет меньше, чем табличное значение  – нет оснований считать, что независимый фактор оказывает влияние на разброс средних значений, в противном случае, независимый фактор оказывает существенное влияние на разброс средних значений (λ– уровень значимости, уровень риска, обычно для экономических задач λ=0,05).
– нет оснований считать, что независимый фактор оказывает влияние на разброс средних значений, в противном случае, независимый фактор оказывает существенное влияние на разброс средних значений (λ– уровень значимости, уровень риска, обычно для экономических задач λ=0,05).
83. Парные коэффициенты корреляции. Для измерения тесноты связи между двумя из рассматриваемых переменных (без учета их взаимодействия с другими переменными) применяются парные коэффициенты корреляции. Методика расчета таких коэффициентов и их интерпретации аналогичны линейному коэффициенту корреляции в случае однофакторной связи.
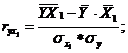

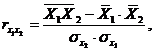
где  - среднее квадратическое отклонение факторного признака;
- среднее квадратическое отклонение факторного признака;
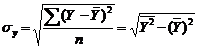 - среднее квадратическое отклонение результативного признака.
- среднее квадратическое отклонение результативного признака.
84. Смысл регрессионного анализа – построение функциональных зависимостей между двумя группами переменных величин Х1, Х2, … Хр и Y. При этом речь идет о влиянии переменных Х (это будут аргументы функций) на значения переменной Y (значение функции). Переменные Х мы будем называть факторами, а Y – откликом.Наиболее простой случай – установление зависимости одного отклика y от одного фактора х. Такой случай называется парной (простой) регрессией.
Парная регрессия – уравнение связи двух переменных у и x:
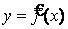 ,
,
где у – зависимая переменная (результативный признак);
х – независимая, объясняющая переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Линейная регрессия:  .
.
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
85. Отбор факторов обычно осуществляется в две стадии:
- отбираются факторы, исходя из сущности проблемы
- на основе матрицы показателей корреляции определяют t-статистики для параметров регрессии.
Коэффициенты интеркорреляции (т.е. корреляции между объясняющими переменными) позволяют исключать из модели дублирующие факторы. Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если rxixj³0,7.
Поскольку одним из условий построения уравнения множественной регрессии является независимость действия факторов, т.е. Rxixj=0, то коллинеарность факторов нарушает это условие. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами.
При рассмотрении экономических процессов чаще всего приходится обращаться к моделям, содержащим более одного фактора-признака. Таким образом, следует включить в модель не один фактор, а несколько, т.е. построить уравнение множественной регрессии. Уравнение множественной регрессии имеет вид:
y=f(x1,x2,…,xk)
Простейшая функция для построения множественной регрессионной модели – линейная:
y = a + b1x1 + b2x2 +…+ bkxk +ε.
Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и целого ряда других вопросов эконометрики. В настоящее время множественная регрессия – один из наиболее распространенных методов в эконометрике. Основная цель – построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также их совокупное воздействие на моделируемый показатель.
86. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
В общем виде задача статистики в области изучения взаимосвязей состоит не только в количественной оценке их наличия, направления и силы связи, но и в определении формы (аналитического выражения) влияния факторных признаков на результативные.
Задачами регрессионного анализа являются выбор типа модели (формы связи), установление степени влияния независимых переменных на зависимую и определение расчётных значений зависимой переменной (функции регрессии). Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии.
87. Пусть требуется оценить прогнозное значение признака-результата для заданного значения признака-фактора  .
.
Прогнозируемое значение признака-результата с доверительной вероятностью равной (1-a) принадлежит интервалу прогноза:
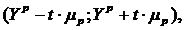
где 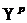 - точечный прогноз;
- точечный прогноз;
t - коэффициент доверия, определяемый по таблицам распределения Стьюдента в зависимости от уровня значимости a и числа степеней свободы (n-2);
 - средняя ошибка прогноза.
- средняя ошибка прогноза.
Точечный прогноз рассчитывается по линейному уравнению регрессии:
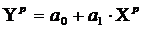 .
.
Средняя ошибка прогноза в свою очередь:
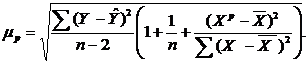
88. Для определения вклада конкретных ценных бумаг в риск хорошо диверсифицированного портфеля необходимо оценить степень рыночного, а не общего риска каждой из них, а затем определить его чувствительность к рыночным изменениям. Эту чувствительность называют β-коэффициентом.
β-коэффициент представляет собой индекс изменчивости доходности данного актива по отношению к изменчивости доходности в среднем на рынке. Сам рынок представляет собой портфель из всех акций, и β-коэффициент его «средней» акции составляет 1,0. Если β-коэффициент акций i больше 1,0, то их изменчивость превышает изменчивость рынка. Если 0 < в < 1, то доходность акций изменяется в том же направлении, что и доходность рынка, но в меньшей степени.
89. Среди нелинейных моделей наиболее часто используется степенная функция  , которая приводится к линейному виду логарифмированием:
, которая приводится к линейному виду логарифмированием:
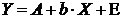 ,
,
где 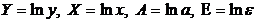 . Т.е. МНК мы применяем для преобразованных данных:
. Т.е. МНК мы применяем для преобразованных данных:
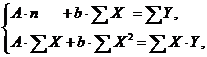
а затем потенцированием находим искомое уравнение.
Широкое использование степенной функции связано с тем, что параметр 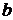 в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности.
в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности.
Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%. Формула для расчета коэффициента эластичности имеет вид:
 . (1.19)
. (1.19)
Так как для остальных функций коэффициент эластичности не является постоянной величиной, а зависит от соответствующего значения фактора  , то обычно рассчитывается средний коэффициент эластичности:
, то обычно рассчитывается средний коэффициент эластичности:
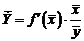 . (1.20)
. (1.20)
90. В регрессионном анализе изучается односторонняя зависимость переменной Y от одной или нескольких переменных Х1 …., Хk. Основная задача регрессионного анализа – установление формы зависимости между зависимой (Y) и независимыми (Х1 …., Хk) переменными и анализ достоверности параметров этой зависимости. Такие переменные, как расходы на рекламу, транспорт, численность населения и т.п. являются независимыми переменными, а те переменные, которые мы пытаемся оценить (например, объем продаж), являются зависимыми переменными. Схема составления прогноза заключается в сборе данных о значениях зависимых и независимых переменных, их анализе на предмет наличия связи (корреляция) и выведении математического уравнения, описывающего эту связь (регрессия).