Обнаружение знаний в базах данных
Появление технологий DM&KDD обусловлено накоплением огромных объемов информации в компьютерных базах данных, которые стало невыгодно хранить и которыми стало трудно пользоваться традиционными способами. Последнее обстоятельство связано со стремительным развитием вычислительной техники и программных средств для представления и обработки данных. Большие объемы накопленных данных постоянно приходится модифицировать из-за быстрой смены аппаратного и программного обеспечения БД, при этом неизбежны потери и искажение информации. Одним из средств для преодоления подобных трудностей является создание информационных хранилищ данных, доступ к которым не будет сильно зависеть от изменения данных во времени и от используемого программного обеспечения. Другой подход ориентирован на сжатие больших объемов данных путем нахождения некоторых общих закономерностей (знаний) в накопленной информации. Оба направления актуальны с практической точки зрения. Второй подход более интересен для специалистов в области ИИ, так как связан с решением проблемы приобретения новых знаний. Следует заметить, что наиболее плодотворным является сочетание обоих направлений.
Наличие хранилища данных — необходимое условие для успешного проведения всего процесса KDD. Хранилищем данных называют предметно-ориентированное, интегрированное, привязанное ко времени, неизменяемое собрание данных, используемых для поддержки процесса принятия управленческих решений. Предметная ориентация означает, что данные объединены в категории и хранятся в соответствии с теми областями, которые они описывают, а не в соответствии с приложениями, которые их используют. Такой принцип хранения гарантирует, что отчеты, сгенерированные различными аналитиками, будут опираться на одну и ту же совокупность данных. Привязанность ко времени означает, что хранилище можно рассматривать как собрание исторических данных, т.е. конкретные значения данных однозначно связаны с определенными моментами времени. Атрибут времени всегда явно присутствует в структурах хранилищ данных. Данные, занесенные в хранилище, уже не изменяются в отличие от оперативных систем, где присутствуют только последние, постоянно изменяемые версии данных. Для хранилищ данных характерны операции добавления, а не модификации данных. Современные средства администрирования хранилищ данных обеспечивают эффективное взаимодействие с программным инструментарием DM и KDD.
Рассмотрим простой пример, иллюстрирующий технологии DM&KDD. В базах данных можно хранить большую таблицу значений переменных Х и Y, но если удалось установить зависимость между этими переменными, то без существенных потерь информации можно значительно сократить объем занимаемой памяти, поместив туда найденную зависимость, например Y=sin(kX). В общем случае зависимости, выявляемые в базах данных, могут быть представлены правилами, гипотезами, моделями нейронных сетей и т.п. Интеллектуальные средства извлечения информации позволяют почерпнуть из БД более глубокие сведения, чем традиционные системы оперативной обработки транзакций (OLTP — On-Line Transaction Processing) и оперативной аналитической обработки (OLAP). Выведенные из данных закономерности и правила можно применять для описания существующих отношений и закономерностей, а также для принятия решений и прогнозирования их последствий.
Извлечение знаний из БД является одной из разновидностей машинного обучения, специфика которой заключается в том, что реальные БД, как правило, проектируются без учета потребностей извлечения знаний и содержат ошибки.
В технологиях DM&KDD используются различные математические методы и алгоритмы: классификация, кластеризация, регрессия, прогнозирование временных рядов, ассоциация, последовательность.
Классификация — инструмент обобщения. Она позволяет перейти от рассмотрения единичных объектов к обобщенным понятиям, которые характеризуют некоторые совокупности объектов и являются достаточными для распознавания объектов, принадлежащих этим совокупностям (классам). Суть процесса формирования понятий заключается в нахождении закономерностей, свойственных классам. Для описания объектов используются множества различных признаков (атрибутов), Проблема формирования понятий по признаковым описаниям была сформулирована М. М. Бонгартом. Ее решение базируется на применении двух основных процедур: обучения и проверки. В процедурах обучения строится классифицирующее правило на основе обработки обучающего множества объектов. Процедура проверки (экзамена) состоит в использовании полученного классифицирующего правила для распознавания объектов из новой (экзаменационной) выборки. Если результаты проверки признаны удовлетворительными, то процесс обучения заканчивается, в противном случае классифицирующее правило уточняется в процессе повторного обучения.
Кластеризация — это распределение информации (записей) из БД по группам (кластерам) или сегментам с одновременным определением этих групп. В отличие от классификации здесь для проведения анализа не требуется предварительного задания классов.
Регрессионный анализ используется в том случае, если отношения между атрибутами объектов в БД выражены количественными оценками. Построенные уравнения регрессии позволяют вычислять значения зависимых атрибутов по заданным значениям независимых признаков.
Прогнозирование временных рядов является инструментом для определения тенденций изменения атрибутов рассматриваемых объектов с течением времени. Анализ поведения временных рядов позволяет прогнозировать значения исследуемых характеристик.
Ассоциация позволяет выделить устойчивые группы объектов, между которыми существуют неявно заданные связи. Частота появления отдельного предмета или группы предметов, выраженная в процентах, называется распространенностью. Низкий уровень распространенности (менее одной тысячной процента) говорит о том, что такая ассоциация не существенна.
Типичным примером применения ассоциации является анализ структуры покупок. Например, при проведении исследования в супермаркете можно установить, что 65 % купивших картофельные чипсы берут также и «кока-колу», а при наличии скидки за такой комплект «колу» приобретают в 85 % случаев. Подобные результаты представляют ценность при формировании маркетинговых стратегий.
Последовательность — это метод выявления ассоциаций во времени. В данном случае определяются правила, которые описывают последовательное появление определенных групп событий. Такие правила необходимы для построения сценариев. Кроме того, их можно использовать, например, для формирования типичного набора предшествующих продаж, которые могут повлечь за собой последующие продажи конкретного товара.
К интеллектуальным средствам DM&KDD относятся нейронные сети, деревья решений, индуктивные выводы, методы рассуждения по аналогии, нечеткие логические выводы, генетические алгоритмы, алгоритмы определения ассоциаций и последовательностей, анализ с избирательным действием, логическая регрессия, эволюционное программирование, визуализация данных. Иногда перечисленные методы применяются в различных комбинациях.
Нейронные сети относятся к классу нелинейных адаптивных систем с архитектурой, условно имитирующей нервную ткань, состоящую из нейронов. Математическая модель нейрона представляет собой некий универсальный нелинейный элемент, допускающий возможность изменения и настройки его характеристик. Подробнее вопросы построения моделей нейронных сетей рассмотрены в главе 5. Нейронные сети широко применяются для решения задач классификации. Построенную сеть сначала нужно «обучить» на примерах, для которых известны значения исходных данных и результаты. Процесс «обучения» сети заключается в подборе весов межнейронных связей и модификации внутренних параметров активационной функции нейронов. «Обученная» сеть способна классифицировать новые объекты (или решать другие примеры), однако правила классификации остаются не известными пользователю.
Деревья решений — метод структурирования задачи в виде древовидного графа, вершины которого соответствуют продукционным правилам, позволяющим классифицировать данные или осуществлять анализ последствий решений. Этот метод дает наглядное представление о системе классифицирующих правил, если их не очень много. Простые задачи решаются с помощью этого метода гораздо быстрее, чем с использованием нейронных сетей. Для сложных проблем и для некоторых типов данных деревья решений могут оказаться неприемлемыми. Кроме того, для этого метода характерна проблема значимости. Одним из последствий иерархической кластеризации данных является то, что для многих частных случаев отсутствует достаточное число обучающих примеров, в связи с чем классификацию нельзя считать надежной. Методы деревьев решений реализованы во многих программных средствах, а именно: С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США).
Индуктивные выводы позволяют получить обобщения фактов, хранящихся в БД. В процессе индуктивного обучения может участвовать специалист, поставляющий гипотезы. Такой способ называют обучением с учителем. Поиск правил обобщения может осуществляться без учителя путем автоматической генерации гипотез. В современных программных средствах, как правило, сочетаются оба способа, а для проверки гипотез используются статистические методы. Примером системы с применением индуктивных выводов является XpertRule Miner, разработанная фирмой Attar Software Ltd. (Великобритания).
Рассуждения на основе аналогичных случаев (Case-based reasoning — CBR) основаны на поиске в БД ситуаций, описания которых сходны по ряду признаков с заданной ситуацией. Принцип аналогии позволяет предполагать, что результаты похожих ситуаций также будут близки между собой. Недостаток этого подхода заключается в том, что здесь не создается каких-либо моделей или правил, обобщающих предыдущий опыт. Кроме того, надежность выводимых результатов зависит от полноты описания ситуаций, как и в процессах индуктивного вывода. Примерами систем, использующих CBR, являются: KATE Tools (Acknosoft, Франция), Pattern Recognition Workbench (Unica, США).
Нечеткая логика применяется для обработки данных с размытыми значениями истинности, которые могут быть представлены разнообразными лингвистическими переменными. Нечеткое представление знаний широко применяется в системах с логическими выводами (дедуктивными, индуктивными, абдуктивными) для решения задач классификации и прогнозирования, например в системе XpertRule Miner (Attar Software Ltd., Великобритания), а также в AIS и NeuFuz и др..
Генетические алгоритмы входят в инструментарий DM&KDD как мощное средство решения комбинаторных и оптимизационных задач. Они часто применяются в сочетании с нейронными сетями (см. главу 6). В задачах извлечения знаний применение генетических алгоритмов сопряжено со сложностью оценки статистической значимости полученных решений и с трудностями построения критериев отбора удачных решений. Представителем пакетов из этой категории является GeneHunter фирмы Ward Systems Group. Генетические алгоритмы используются также в пакете XpertRule Miner и др.
Логическая (логистическая) регрессия используется для предсказания вероятности появления того или иного значения дискретной целевой переменной. Дискретная зависимая (целевая) переменная не может быть смоделирована методами обычной многофакторной линейной регрессии. Тем не менее вероятность результата может быть представлена как функция входных переменных, что позволяет получить количественные оценки влияния этих параметров на зависимую переменную. Полученные вероятности могут использоваться и для оценки шансов. Логическая регрессия — это, с одной стороны, инструмент классификации, который используется для предсказания значений категориальных переменных, с другой стороны — регрессионный инструмент, позволяющий оценить степень влияния входных факторов на результат.
Эволюционное программирование — самая новая и наиболее перспективная ветвь DM&KDD. Суть метода заключается в том, что гипотезы о форме зависимости целевой переменной от других переменных формулируются компьютерной системой в виде программ на определенном внутреннем языке программирования. Если это универсальный язык, то теоретически он способен выразить зависимости произвольной формы. Процесс построения таких программ организован как эволюция в мире программ. Когда система находит программу, достаточно точно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных дочерних программ те, которые являются наиболее точными. Затем найденные зависимости переводятся с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и т.п.). При этом активно используются средства визуализации. Методы эволюционного программирования реализованы в системе PolyAnalyst (Unica, США).
Обнаружение знаний в базах данных
Knowledge Discovery in Databases
Процесс обнаружения полезных знаний в базах данных. Эти знания могут быть представлены в виде закономерностей, правил, прогнозов, связей между элементами данных и др. Главным инструментом поиска знаний в процессе KDD являются аналитические технологии Data Mining, реализующие задачи классификации, кластеризации, регрессии, прогнозирования, предсказания и т.д.
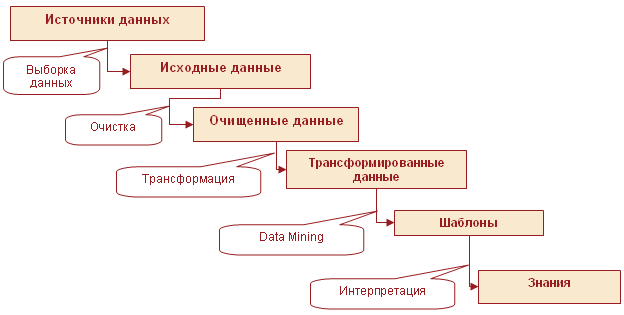
Однако в соответствии с концепцией KDD эффективный процесс поиска знаний не ограничивается их анализом. KDD включает последовательность операций, необходимых для поддержки аналитического процесса. К ним относятся:
1. Консолидация данных
Консолидация
Consolidation
Комплекс методов и процедур, направленных на извлечение данных из различных источников, обеспечение необходимого уровня их информативности и качества, преобразование к единому формату, в котором они могут быть загружены в хранилище данных или аналитическую систему.