Обработка и хранение информации
Типы и виды данных, данные транзакций
В современных условиях организации приходится иметь дело с огромным количеством информации. Информация, поступающая в организацию, может быть неструктурированной, слабоструктурированной или структурированной. Если раньше обрабатывающей системой был человек, то сейчас процесс обработки информации почти полностью автоматизирован. Соответственно, чем более структурированы данные, тем проще их обработать.
Структурирование информации осуществляется посредством формирования наборов данных, которые могут быть упорядоченными, неупорядоченными или транзакционными.
Используемые организацией данные могут быть непрерывными и дискретными.
· Непрерывные данные – данные, значения которых могут принимать какое угодно значение в некотором интервале.
· Дискретные данные – значения признака, общее число которых конечно, может быть подсчитано при помощи натуральных чисел
Кроме того, данные могут быть представлены в различных форматах, что также определяет и ограничивает возможности их обработки.
К основным форматам относятся форматы: строковый, вещественный, целый, логический, дата.
Основная часть аналитической информации в большинстве организаций поступает из тех данных, которые уже имеются в наличии, — данных транзакций.
Данные транзакций - это сведения, хранимые с целью отслеживания взаимодействий, или бизнес-транзакций, выполняемых организацией.
Большинству организаций необходимо отслеживать те вещи, с которыми они имеют дело в ходе решения своих задач. Принятые заказы, произведенные товары, оказанные услуги, оплата, полученная от клиентов, выплаты поставщикам — результатом всех этих видов взаимодействия становится одна или несколько записей в некотором хранилище данных. Все эти взаимодействия являются бизнес-транзакциями. Хранение данных транзакций и управление этими данными с помощью компьютера называют оперативной обработкой транзакций, или OLTP-обработкой.
Системы оперативной обработки транзакций (OnLine Transaction Processing, OLTP) служат для хранения данных о выполняемых бизнес-транзакциях и призваны поддерживать повседневную деятельность организации.
Особенности работы OLTP-систем
В OLTP-системах хранятся необработанные данные, необходимые для ведения бизнес-аналитики. Однако при попытке выборки этих данных из OLTP-систем возникают проблемы. Рассмотрим основные.
- Гигантский объем обрабатываемых транзакций. В силу особенностей проектирования OLTP-системы обычно не слишком хорошо подходят для крупномасштабного агрегирования — они просто не предназначены для этого. Чтобы заставить агрегирование работать эффективно, следует обратиться к альтернативным методам оптимизации хранения данных.
Агрегат – это значение, вычисляемое по некоторому множеству детализированных записей. Зачастую представляет собой сумму множества чисел, хотя он также может вычисляться не суммированием, а выполнением каких-либо других арифметических операций или даже подсчетом числа элементов в группе.
- Вмешательство в бизнес-операции. OLTP-системы используются организациями для поддержания их повседневной деятельности. Во многих случаях деятельность организации зависит от производительности этих систем. Если система обработки заказов или система управления связями с клиентами излишне загружена, то работа организации может застопориться.
Если OLTP-системы использовать для вычисления агрегатов, то это приведет к загрузке большой доли вычислительных мощностей и займет значительное время. Возможно также, что в ходе вычисления агрегата будет заблокировано большое число записей, что сделает их участие в транзакциях невозможным. То и другое может серьезно повлиять на эффективность обработки транзакций.
- Архивирование. Поскольку OLTP-системы предназначены для решения повседневных задач, они не слишком приспособлены для долговременного хранения данных. Данные могут храниться в течение года, после чего в ходе закрытия отчетного периода они могут быть удалены из базы или заархивированы в новом формате, в текстовом файле или в резервном файле базы данных. В любом случае доступ к этим данным становится делом достаточно сложным.
Главное требование к OLTP-системам — быстрое обслуживание относительно простых запросов большого числа пользователей, при этом время ожидания выполнения типового запроса не должно превышать несколько секунд.
Рассмотрим характерные черты данного процесса, свойственные в той или иной мере всем OLTP-системам.
• Запросы и отчеты полностью регламентированы. Оператор не может сформировать собственный запрос, чтобы уточнить или проанализировать какую-либо информацию.
• Как только перелет завершился, информация об обслуживании данного клиента теряет смысл, становится неактуальной и подлежит удалению по прошествии определенного времени (то есть исторические данные не поддерживаются).
• Операции производятся над данными с максимальным уровнем детализации, то есть по каждому клиенту в отдельности.
Со временем в таких системах начали аккумулироваться большие объемы данных — документы, сведения о банковских операциях, информация о клиентах, заключенных сделках, оказанных услугах и т. д.
Постепенно возникло понимание того, что сбор данных не самоцель. Собранная информация может оказаться весьма полезной в процессе управления организацией, поиска путей совершенствования деятельности и получения посредством этого конкурентных преимуществ. Но для этого нужны системы, которые позволяли бы выполнять не только простейшие действия над данными: подсчитывать суммы, средние, максимальные и минимальные значения. Появилась потребность в информационных системах, которые позволяли бы проводить глубокую аналитическую обработку, для чего необходимо решать такие задачи, как поиск скрытых структур и закономерностей в массивах данных, вывод из них правил, которым подчиняется данная предметная область, стратегическое и оперативное планирование, формирование не регламентированных запросов, принятие решений и прогнозирование их последствий.
Понимание преимуществ, которые способен дать интеллектуальный анализ, привело к появлению нового класса систем — информационных систем поддержки принятия решений (информационных СППР), ориентированных на аналитическую обработку данных с целью получения знаний, необходимых для разработки решений в области управления. Дополнительным стимулом совершенствования этих систем стали такие факторы, как снижение стоимости высокопроизводительных компьютеров и расходов на хранение больших объемов информации, появление возможности обработки больших массивов данных и развитие соответствующих математических методов. Обобщенная структурная схема информационной СППР:
В основе работы с такой СППР лежат запросы, с которыми к ней обращается пользователь (лицо, принимающее решение (ЛПР) — менеджер, эксперт или аналитик). При этом запросы, допустимые в традиционных системах оперативной обработки данных, очень примитивны. Например, для банка это может быть запрос типа «Сколько денег на счету клиента?» или «Сколько денег клиент потратил за последний месяц?». Очевидно, что ценность информации, полученной с помощью подобного запроса, невелика. В то же время аналитическая система может ответить на гораздо более сложные запросы, например: «Определить среднее время между выставлением и оплатой счета для каждой категории клиентов».
В процессе разработки систем анализа информации и методологии их применения обнаружилось, что для эффективного функционирования такие системы должны быть организованы несколько иным способом, чем тот, который применяется в OLTP-системах.
Сравнение OLTP-систем и СППР
В связи с этим можно выделить ряд принципиальных отличий СППР и OLTP-систем.
| Свойство | OLTP-система | СППР |
| Цели использования данных | Быстрый поиск, простейшие алгоритмы обработки | Аналитическая обработка с целью поиска скрытых закономерностей, построения прогнозов и моделей и т. д. |
| Уровень обобщения (детализации) данных | Детализированные | Как детализированные, так и обобщенные (агрегированные) |
| Требования к качеству данных | Возможны некорректные данные (ошибки регистрации, ввода и т. д.) | Ошибки в данных не допускаются, поскольку могут привести к некорректной работе аналитических алгоритмов |
| Формат хранения данных | Данные могут храниться в различных форматах в зависимости от приложения, в котором они были созданы | Данные хранятся и обрабатываются в едином формате |
| Время хранения данных | Как правило, не более года (в пределах отчетного периода) | Годы, десятилетия |
| Изменение данных | Данные могут добавляться, изменяться и удаляться | Допускается только пополнение; ранее добавленные данные изменяться не должны, что позволяет обеспечить их хронологию |
| Периодичность обновления | Часто, но в небольших объемах | Редко, но в больших объемах |
| Доступ к данным | Должен быть обеспечен доступ ко всем текущим (оперативным) данным | Должен быть обеспечен доступ к историческим (то есть накопленным за достаточно длительный период времени) данным с соблюдением их хронологии |
| Характер выполняемых запросов | Стандартные, настроенные заранее | Нерегламентированные, формируемые аналитиком «на лету» в зависимости от требуемого анализа |
| Время выполнения запроса | Несколько секунд | До нескольких минут |
В СППР используются специализированные базы данных, которые называются хранилищами данных (ХД). Хранилища данных ориентированы на аналитическую обработку и удовлетворяют требованиям, предъявляемым к системам поддержки принятия решений.
Консолидация данных
Обычно руководителям приходится сталкиваться со следующей ситуацией. Во-первых, данные на предприятии расположены в различных источниках самых разнообразных форматов и типов — в отдельных файлах офисных документов (Excel, Word, обычных текстовых файлах), в учетных системах («1С:Предприятие», «Парус» и др.), в базах данных (Oracle, Access, dBase и др.). Во-вторых, данные могут быть избыточными или, наоборот, недостаточными. А в-третьих, данные являются «грязными», то есть содержат факторы, мешающие их правильной обработке и анализу (пропуски, аномальные значения, дубликаты и противоречия). Таким образом, необходимо обработать получаемую информацию. Цель обработки информации в целом определяется целью функционирования некоторой системы, с которой связан рассматриваемый информационный процесс
Консолидация — комплекс методов и процедур, направленных на извлечение данных из Различных источников, обеспечение необходимого уровня их информативности и качества, преобразование в единый формат, в котором они могут быть загружены в хранилище данных или аналитическую систему.
Сопутствующими задачами консолидации являются оценка качества данных и их обогащение.
Основные критерии оптимальности с точки зрения консолидации данных:
□ обеспечение высокой скорости доступа к данным;
□ компактность хранения;
□ автоматическая поддержка целостности структуры данных;
□ контроль непротиворечивости данных.
Ключевым понятием консолидации является источник данных — объект, содержащий структурированные данные, которые могут оказаться полезными для решения аналитической задачи.
Аналитические приложения, как правило, не содержат развитых средств ввода и редактирования данных, а работают с уже сформированными выборками. Таким образом, формирование массивов данных для анализа в большинстве случаев ложится на плечи заказчиков аналитических решений.
В процессе консолидации данных решаются следующие задачи:
□ выбор источников данных;
□ разработка стратегии консолидации;
□ оценка качества данных;
□ обогащение;
□ очистка;
□ перенос в хранилище данных.
Сначала осуществляется выбор источников, содержащих данные, которые могут иметь отношение к решаемой задаче, затем определяются тип источников и методика организации доступа к ним. В связи с этим можно выделить три основных подхода к организации хранения данных.
Данные, хранящиеся в отдельных (локальных) файлах, например в текстовых файлах с разделителями, документах Word, Excel и т. д. Такого рода источником может быть любой файл, данные в котором организованы в виде столбцов и записей. Столбцы должны быть типизированы, то есть содержать данные одного типа, например только текстовые или только числовые. Преимущество таких источников в том, что они могут создаваться и редактироваться с помощью простых и популярных офисных приложений, работа с которыми не требует от персонала специальной подготовки. К недостаткам следует отнести то, что они далеко не всегда оптимальны с точки зрения скорости доступа к ним, компактности представления данных и поддержки их структурной целостности. Например, ничто не мешает пользователю табличного процессора разместить в одном столбце данные различных типов (числовые и текстовые), что впоследствии обязательно приведет к проблемам при их обработке.
Базы данных (БД) различных СУБД, таких как Oracle, SQL Server, Firebird, dBase, FoxPro, Access и т. д. Файлы БД лучше поддерживают целостность структуры данных, поскольку тип и свойства их полей жестко задаются при построении таблиц. Однако для создания и администрирования БД требуются специалисты с более высоким уровнем подготовки, чем для работы с популярными офисными приложениями.
Специализированные хранилища данных (ХД) являются наиболее предпочтительным решением, поскольку их структура и функционирование специально оптимизируются для работы с аналитической платформой. Большинство ХД обеспечивают высокую скорость обмена данными с аналитическими приложениями, автоматически поддерживают целостность и непротиворечивость данных. Главное преимущество ХД перед остальными типами источников данных — наличие семантического слоя, который дает пользователю возможность оперировать терминами предметной области для формирования аналитических запросов к хранилищу.
Другой важной задачей, которую требуется решить в рамках консолидации, является оценка качества данных с точки зрения их пригодности для обработки с помощью различных аналитических алгоритмов и методов. В большинстве случаев исходные данные являются «грязными», то есть содержат факторы, не позволяющие их корректно анализировать, обнаруживать скрытые структуры и закономерности, устанавливать связи между элементами данных и выполнять другие действия, которые могут потребоваться для получения аналитического решения. К таким факторам относятся ошибки ввода, пропуски, аномальные значения, шумы, противоречия и т. д. Поэтому перед тем, как приступить к анализу данных, необходимо оценить их качество и соответствие требованиям, предъявляемым аналитической платформой. Если в процессе оценки качества будут выявлены факторы, которые не позволяют корректно применить к данным те или иные аналитические методы, необходимо выполнить соответствующую очистку данных.
Очистка данных — комплекс методов и процедур, направленных на устранение причин, мешающих корректной обработке: аномалий, пропусков, дубликатов, противоречий, шумов и т. д.
Еще одной операцией, которая может понадобиться при консолидации данных, является их обогащение.
Обогащение — процесс дополнения данных некоторой информацией, позволяющей повысить эффективность решения аналитических задач.
Обогащение позволяет более эффективно использовать консолидированные данные. Его необходимо применять в тех случаях, когда данные содержат недостаточно информации для удовлетворительного решения определенной задачи анализа. Обогащение данных позволяет повысить их информационную насыщенность и, как следствие, значимость для решения аналитической задачи.
Обобщенная схема процесса консолидации:
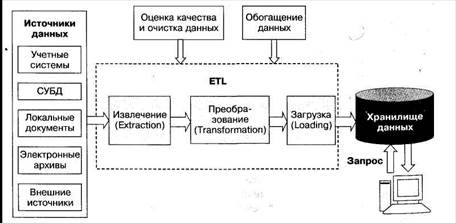
В основе процедуры консолидации лежит процесс ETL (extraction, transformation, loading). Процесс ETL решает задачи извлечения данных из разнотипных источников, их преобразования к виду, пригодному для хранения в определенной структуре, а также загрузки в соответствующую базу или хранилище данных. Если у аналитика возникают сомнения в качестве и информативности исходных данных, то при необходимости он может задействовать процедуры оценки их качества, очистки или богащения, которые также являются составными частями процесса консолидации данных..
Процесс сбора, хранения и оперативной обработки данных на типичном предприятии обычно содержит несколько уровней. На верхнем уровне располагаются реляционные SQL-ориентированные СУБД типа SQL Server, Oracle и т. д. На втором — файловые серверы с некоторой системой оперативной обработки или сетевые версии персональных СУБД типа R-Base, FoxPro, Access и т. д. И наконец, на самом нижнем уровне расположены локальные ПК отдельных пользователей с персональными источниками данных. Чаще всего информация на них собирается в виде файлов офисных приложений — Word, Excel, текстовых файлов и т. д.
Из источников данных всех перечисленных уровней информация в соответствии с некоторым регламентом должна перемещаться в ХД. Для этого необходимо обеспечить выгрузку данных из источников, провести их преобразование к виду, соответствующему структуре ХД, а при необходимости выполнить их обогащение и очистку.
Таким образом, консолидация данных является сложной многоступенчатой процедурой и важнейшей составляющей аналитического процесса, обеспечивающей высокий уровень аналитических решений.