Структура файловой системы

Возможная структура файловой системы
Все что до "Загрузочного блока" и включая его одинаково у всех ОС. Дальше начинаются различия.
Суперблок - содержит ключевые параметры файловой системы.
Реализация файлов
Основная проблема - сколько, и какие блоки диска принадлежат тому или иному файлу.
Непрерывные файлы
Выделяется каждому файлу последовательность соседних блоков.

5 непрерывных файлов на диске и состояние после удаления двух файлов
Преимущества такой системы:
o Простота - нужно знать всего два числа, это номер первого блока и число блоков.
o Высокая производительность - требуется только одна операция поиска, и файл может быть прочитан за одну операцию
Недостатки:
o Диск сильно фрагментируется
Сейчас такая запись почти не используется, только на CD-дисках и магнитных лентах.
Связные списки
Файлы хранятся в разных не последовательных блоках, и с помощью связных списков можно собрать последовательно файл.
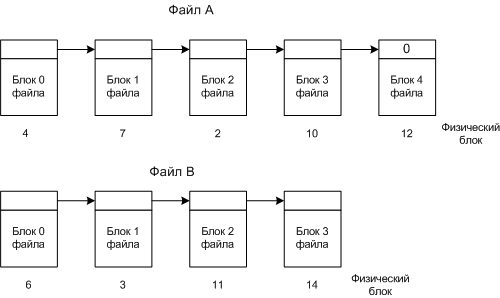
Размещение файла в виде связного списка блоков диска
Номер следующего блока хранится в текущем блоке.
Преимущества:
o Нет потерь дискового пространства на фрагментацию
o Нужно хранить информацию только о первом блоке
Недостатки:
o Уменьшение быстродействия - для того чтобы получить информацию о всех блоках надо перебрать все блоки.
o Уменьшается размер блока из-за хранения служебной информации
Связные списки при помощи таблиц в памяти
Чтобы избежать два предыдущих недостатка, стали хранить всю информацию о блоках в специальной таблице загружаемой в память.
FAT (File Allocation Table) - таблица размещения файлов загружаемая в память.
Рассмотри предыдущий пример, но в виде таблицы.

Таблица размещения файлов
Здесь тоже надо собирать блоки по указателям, но работает быстрее, т.к. таблица загружена в память.
Основной не достаток этого метода - всю таблицу надо хранить в памяти. Например, для 20Гбайт диска, с блоком 1Кбайт (20 млн. блоков), потребовалась бы таблица в 80 Мбайт (при записи в таблице в 4 байта).
Такие таблицы используются в MS-DOS и Windows.
I - узлы
С каждым файлом связывается структура данных, называемая i-узлом (index-node- индекс узел), содержащие атрибуты файла и адреса всех блоков файла.
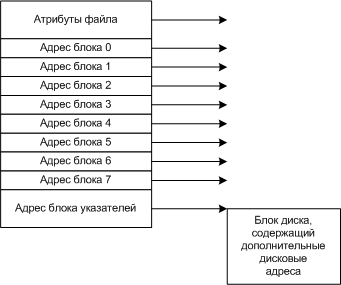
Примеры i-узла
Преимущества:
o Быстродействие - имея i-узел можно получить информацию о всех блоках файла, не надо собирать указатели.
o Меньший объем, занимаемый в памяти. В память нужно загружать только те узлы, файлы которых используются.
Если каждому файлу выделять фиксированное количество адресов на диске, то со временем этого может не хватить, поэтому последняя запись в узле является указателем на дополнительный блок адресов и т.д..
Такие узлы используются в UNIX.
Реализация каталогов
При открытии файла используется имя пути, чтобы найти запись в каталоге. Запись в каталоге указывает на адреса блоков диска.
В зависимости от системы это может быть:
o дисковый адрес всего файла (для непрерывных файлов)
o номер первого блока (связные списки)
o номер i-узла
Одна из основных задач каталоговой системы преобразование ASCII-имени в информацию, необходимую для нахождения данных.
Также она хранит атрибуты файлов.
Варианты хранения атрибутов:
o В каталоговой записи (MS-DOS)
o В i-узлах (UNIX)

Варианты реализации каталогов
Реализация длинных имен файлов
Раньше операционные системы использовали короткие имена файлов, MS-DOS до 8 символов, в UNIX Version 7 до 14 символов. Теперь используются более длинные имена файлов (до 255 символов и больше).
Методы реализации длинных имен файлов:
o Просто выделить место под длинные имена, увеличив записи каталога. Но это займет много места, большинство имен все же меньше 255.
o Применить записи с фиксированной частью (атрибуты) и динамической записью (имя файла).
Второй метод можно реализовать двумя методами:
o Имена записываются сразу после заголовка (длина записи и атрибутов)
o Имена записываются в конце каталога после всех заголовков (указателя на файл и атрибутов)

Реализация длинных имен файлов
Ускорение поиска файлов
Если каталог очень большой (несколько тысяч файлов), последовательное чтение каталога мало эффективно.