Задачи автоматизации проектирования и производства связаны с хранением значительного объема информации в виде единообразных записей и сравнительно простой их обработкой для извлечения новой информации в удобной для пользователя форме. Предназначенные для этого программные средства обычно объединяются под общим названием системы управления базами данных (СУБД), в котором под базой данных понимается совокупность взаимосвязанных и хранящихся в удобном для использования виде данных.
Наилучшая форма организации данных зависит как от их содержания, так и от того, как эти данные должны использоваться. Например, существуют немало СУБД, предназначенных для обработки списков, содержащих разные сведения о перечисленных в этих списках людях. Эти СУБД существенно различаются в зависимости от того, какие сведения о каждом лице имеются в списке (в зависимости от логической структуры данных), и от того, как осуществляется поиск того или иного лица.
Вообще, логической структурой данных принято называть конкретные логические взаимосвязи между данными, обусловленные содержанием этих данных. Например, логической структурой стипендиальной ведомости студенческой группы является взаимосвязь каждой фамилии студента с величиной его стипендии и взаимосвязь всех перечисленных в ведомости фамилий с номером группы.
Совокупность количества взаимосвязанных данных (или, как их еще называют, полей) принято называть логической записью, а совокупность логических записей данного вида — файлом. Таким образом, каждая точка стипендиальной ведомости образует отдельную логическую запись, состоящую из двух полей — фамилии и величины стипендии (например, ИВАНОВ 9000), а вся ведомость образует файл.
В базе данных может одновременно храниться много различных файлов, поэтому пользователь присваивает каждому файлу свое имя. Всякая БД должна храниться в ЗУ ЭВМ. Поэтому форма организации данных зависит не только от логической структуры, но и от ее физического представления, т. е. от способа хранения данных в памяти ЭВМ. Порцию данных, которую СУБД считывает из ЗУ или записывает в ЗУ как единое целое, принято называть физической записью.
Одной из самых важных функций СУБД является поиск логической записи в файле. Поиск производится по ключу, который может состоять из поля, части поля, из комбинации полей. Например, при поиске величины стипендии студента по фамилии ИВАНОВ ключом является фамилия ИВАНОВ.
Категории баз данных
По характеру связи между логическими записями, полями и ключами все БД делятся на три категории: иерархические, сетевые и реляционные.
Иерархическая БД — в ней существует упорядоченность полей внутри каждой логической записи: одно поле считается главным, а другие поля ему подчинены (рис. 2.11). Группы логических записей упорядочиваются в определенную последовательность как ступеньки лестницы, и поиск данных ключей осуществляется прохождением по этой лестнице в соответствии с порядком, определенным последовательностью главных полей. В качестве примера рассмотрим данные о размерах стипендии всех студентов института.
Первый уровень в организации логической структуры такой базы может включать таблицу, содержащую название факультетов, численность студентов этих факультетов, получающих стипендию, и стипендиальный фонд факультетов. Название факультета выступает в качестве главного поля и, выбрав нужный факультет, можно получить доступ к таблице второго уровня.
Второй уровень иерархии может включать таблицы, содержащие перечни специализаций каждого факультета. При этом в качестве главного поля выступает название специализации.
В таблицах следующих уровней может содержаться информация о номере студенческих групп (главное поле) по каждой специализации, их численности и о размерах стипендии, получаемых студентами каждой группы. Последовательно пройдя через несколько уровней иерархии, можно отыскать нужную информацию, такую, например, как размер стипендии студента по фамилии Иванов. В результате для многоуровневой иерархической БД время ответа на запрос может быть весьма большим.
Сетевая база данных
Сетевая база данных обладает несколько большей гибкостью по сравнению с иерархической, поскольку в сетевой БД можно установить связи не только между файлами соседних уровней, но и перескакивать через один или несколько уровней.
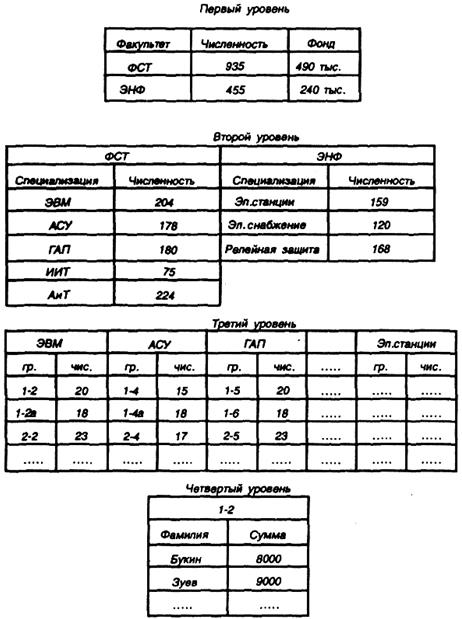
Рис. 2.11 – Структурная схема иерархической БД
Так, в БД связь может быть установлена между списком факультетов и таблицей номеров студенческих групп, и тогда станет возможным отыскать номер студенческой группы без предварительного поиска промежуточной таблицы, содержащей перечень специализации данного факультета.
Реляционная база данных
Эта БД обладает наиболее гибкой логической структурой. При иерархической (или сетевой) организации БД ответы на одни виды запросов занимают значительно меньше времени, чем на другие. Более того, сказать, на какие запросы идет много времени, а на какие мало, можно только после того, как база данных уже создана.
Например, в иерархической БД наибольшее время займет ответ на запрос о размере стипендии конкретного студента, поскольку поле «сумма», содержащее размер стипендии, находится в таблице самого последнего уровня.

Рис. 2.12 – Пример логической записи в БД
К тому же лишь только после затраты большого труда на создание такой БД может выясниться, что «неудобные» для базы запросы, требующие большого времени на ответ, поступают чаще всего. От подобной неприятности избавлена реляционная БД, потому что все поля в логических записях такой базы равноправны: нет главного поля и подчиненных ему полей. Например, если преобразовать иерархическую БД в реляционную, то получится файл, содержащий 935 + 455 = 1390 логических записей (по одной записи на каждого студента). Каждая из этих записей может содержать, например, следующие поля: факультет, специализация, группа, фамилия, сумма. Так, студенту ИВАНОВУ из группы ФСТ-3-2 соответствует следующая логическая запись (рис. 2.12).
Не следует думать, что не возникает проблем при поиске информации в реляционной БД. Если 1390 логических записей, подобных этой, не подчиняются никакому заранее установленному в файле порядку, то ответ на запрос о размере стипендии студента ИВАНОВ связан со сплошным просматриванием всех записей файла. С увеличением общего количества записей в файле такая процедура поиска потребует весьма большого времени. Чтобы ускорить процесс поиска, записи в файле можно упорядочить, например, по алфавитному порядку фамилий студентов. Упорядочение записей позволяет ускорить их поиск с помощью, так называемой двоичной схемы или двоичного поиска.
Согласно двоичной схеме выбирается запись, находящаяся посредине файла. По фамилии студента в этой записи легко судить, в какой из двух половин файла находится искомая запись. Затем процесс повторяется до тех пор, пока не будет найдена нужная запись. Пусть, например, в самой середине файла оказалась запись с фамилией ОСОКИН. Сравнивая первые буквы этой фамилии и искомой фамилией ИВАНОВ, легко понять, что искомая запись находится в первой половине файла. Пусть далее записью, которая делит первую половину файла пополам, оказалась запись (рис. 2.13). Тогда искомая запись находится во второй четверти файла. Продолжая далее точно так же деление второй половины файла пополам, получим 1/8 и 1/16 части файла и т. д. В конце концов будет найдена нужная запись и дан ответ на запрос о размере стипендии студента ИВАНОВ.
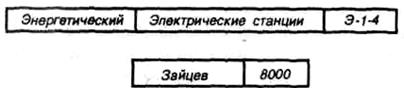
Рис. 2.13 – Запись делящая файл БД пополам
Двоичный поиск ведется быстрее, чем поиск просмотром. Пусть файл, в котором ведется поиск, включает N логических записей. Если эти записи не упорядочены, то окажется, что среднее арифметическое количество записей, которое нужно просмотреть, чтобы ответить на большое количество запросов, приближается к N/2 с ростом числа запросов. Если записи упорядочены, то при двоичном поиске количество просмотренных при ответе на любой запрос записей не будет превышать числа log2 N, округленного до ближайшего целого.
Поскольку log2 N во всяком случае намного меньше N/2 при большом N, то максимальное время, необходимое для ответа на запрос при двоичном поиске, значительно меньше среднего времени ответа при поиске в неупорядоченном файле.
Однако упорядоченный файл имеет и недостатки, во-первых, при большом количестве логических записей пополнение такого файла новыми записями связано с перемещением старых записей, чтобы не нарушать упорядоченность файла в целом, во-вторых, всякая запись упорядоченного файла может быть найдена только по значению того поля, по которому упорядочены все записи файла. Например, если бы все 1390 записей в примере были упорядочены в файле не по фамилиям, а скажем по номерам студенческих групп, то найти размер стипендии студента ИВАНОВА (с помощью двоичного поиска, не зная номера группы этого студента) было невозможно. Конечно, можно создать несколько дубликатов одного и того же файла, упорядоченных по значению разных полей, но для этого потребуется много дополнительного места в памяти ЭВМ. Еще более гибкая (двоичная схема), процедура связана с хешированием (перемешивание — англ.).
Согласно этой процедуре, каждой логической записи в файле по некоторому правилу ставится в соответствие число, которое аналогично адресу этой записи в памяти компьютера. Например, если пронумеровать все буквы русского алфавита, то отдельные буквы фамилии студента ИВАНОВ будут иметь соответственно двухрядные номера: 10, 03, 01, 15, 16, 03. Составленное из этих номеров число 100301151603 порождает адрес логической записи в памяти ЭВМ.
Сложность такого подхода заключается в том, что адреса логических записей будут получаться очень большими (например, адрес записи с фамилией ИВАНОВ получится больше 100 млрд.!), так что для размещения этих записей потребуется невероятно большой объем памяти компьютера, а при этом память может оставаться очень слабо заполненной, поскольку большинство комбинаций букв не образуют фамилий.
Выход из этого затруднения можно найти, если предложить другое правило вычисления адреса логической записи, например, если сложить номера (10 + 3 + 1 + 15+16 + 3 = 48) букв фамилии ИВАНОВ, то полученную сумму 48 тоже можно рассматривать, как адрес записи и разместить эту запись в 48-й ячейке памяти.
Как видим, здесь адрес не является очень большим числом, а для размещения записи уже не требуется, чтобы память компьютера имела большой объем. Однако такой метод приводит иногда к ситуациям, когда в двух записях получится один и тот же адрес. Например, для записи, соответствующей студенту по фамилии ИВАНОВ, тоже получится адрес 48.
Вообще, всякий метод вычисления адреса логической записи по ее содержимому называется хеш-функцией. Практически никакая хеш-функция не гарантирует от конфликтов, поэтому на случай конфликтов договариваются использовать некоторую другую (дополнительную), хеш-функцию. Этого бывает достаточно для устранения всех конфликтов. Если хеш-функция выбрана удачно, то логические записи распределяются более или менее равномерно по ячейкам памяти компьютера (точнее, по той области памяти, которая отведена на данный файл), и конфликты будут встречаться редко. Если бы, например, заданию была известна относительная доля появления каждой буквы алфавита в большом количестве фамилий студентов, то можно было бы раз и навсегда сконструировать самую удачную из всех возможных хеш-функций. Однако такой благоприятной ситуации не бывает.
При хешировании значение хеш-функции, т. е. адрес логической записи, вычисляется всякий раз при поиске этой записи в файле. Вычислить хеш-функцию несложно, и когда ее значение, т. е. адрес искомой ячейки, известно, выбор нужной логической записи осуществляется прямо по адресу хеширования — чрезвычайно быстрый метод поиска. При использовании хеширования дополнение файла новыми логическими записями тоже эффективно, поскольку при этом не сохраняют какую-либо упорядоченность файла в целом.
Все рассмотренные методы поиска информации в настоящее время получили широкое распространение в системах управления небольшими БД для ПЭВМ. Для СУБД, создаваемых на мощных компьютерах, разработаны другие, более сложные методы поиска, требующие более сложных, но зато и более эффективных программ.