ОСНОВЫРАБОТЫСО СТРУКТУРАМИ.
Структура— это совокупность нескольких переменных, часто различных типов, сгруппированных под единым именем для удобства обращения. Структуры предоставляют возможность хранения большого количества различных значений, объединенных одним общим названием. Это делает программу более модульной, что в свою очередь позволяет легко изменять код, потому что он становится более компактным. Структуры, как правило, используют тогда, когда в программе есть много данных и их нужно сгруппировать вместе — например, такие данные могут использоваться для хранения записей из базы данных.
Давайте представим телефонный справочник в виде структуры, то есть в структуре должна храниться вся необходимая информацию о каждом человеке — имя, адрес, номер телефона, и так далее. Синтаксис объявления структуры:
| struct /*имя структуры*/ { /*переменные-члены структуры*/ }; |
То есть одно единственное имя структуры может объединять различные переменные, они могут отличаться даже типами данных, это могут быть как массивы, строки так и обычные переменные. К примеру, давайте рассмотрим следующее объявление структуры:
| struct home { int rooms; }; struct home home1; // объявляем структуру как обычную переменную, просто вначале дописываем слово struct home1.rooms = 4; //вот так получаем доступ к переменной |
СТРУКТУРЫИ ФУНКЦИИ.
Единственно возможные операции над структурами - это их копирование, присваивание, взятие адреса с помощью & и осуществление доступа к ее элементам. Копирование и присваивание также включают в себя передачу функциям аргументов и возврат ими значений. Структуры нельзя сравнивать. Инициализировать структуру можно списком константных значений ее элементов; автоматическую структуру также можно инициализировать присваиванием.
Чтобы лучше познакомиться со структурами, напишем несколько функций, манипулирующих точками и прямоугольниками. Существует по крайней мере три подхода: передавать компоненты по отдельности, передавать всю структуру целиком и передавать указатель на структуру. Каждый подход имеет свои плюсы и минусы.
Первая функция, makepoint, получает два целых значения и возвращает структуру point.
/* makepoint: формирует точку по компонентам x и y */
struct point makepoint(int х, int у)
{
struct point temp;
temp.x = х;
temp.у = у;
return temp;
}
Заметим: никакого конфликта между именем аргумента и именем элемента структуры не возникает; более того, сходство подчеркивает родство обозначаемых им объектов.
Теперь с помощью makepoint можно выполнять динамическую инициализацию любой структуры или формировать структурные аргументы для той или иной функции:
Функцию makepoint можно использовать для динамической инициализации любой структуры или для передачи аргументов-структур в функции:
struct rect screen;
struct point middle;
struct point makepoint(int, int);
screen.ptl = makepoint(0, 0);
screen.pt2 = makepoint(XMAX, YMAX);
middle = makepoint((screen.ptl.x + screen.pt2.x)/2,
(screen.ptl.у + screen.pt2.y)/2);
Следующим шагом будет создание набора функций для арифметических операций над этими структурами. Вот пример одной из них:
/* addpoint: сложение координат двух точек */
struct point addpoint(struct point pi, struct point p2)
{
pl.x += p2.x;
pi.у + = p2.y;
return pi;
}
Здесь структурами являются как аргументы, так и возвращаемое значение. Вместо
того чтобы помещать результат во временную переменную, мы инкрементировали
компоненты структуры pi, чтобы подчеркнуть тот факт, что параметры-структуры передаются по значениям, как и любые другие параметры.
МАССИВЫСТРУКТУР.
Массивы структур служат для обработки большого объема информации. Они объявляются так же, как обычно, но предварительно (выше) надо объявить саму структуру как новый тип данных. Для обращения к полю структуры также используют точку, но теперь надо указать в квадратных скобках еще номер нужной структуры, например Book A[20];... A[12].pages = 50; for (i = 0; i < 20; i ++) // цикл по всем структурам в массива puts(A[i].title); // вывести название книги
УКАЗАТЕЛИ НА СТРУКТУРЫ.
Для иллюстрации некоторых моментов, касающихся указателей на структуры и массивов структур, перепишем программу подсчета ключевых слов, пользуясь для получения элементов массива вместо индексов указателями.
Внешнее объявление массива keytab остается без изменения, a main и binsearch нужно модифицировать.
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
int getword(char *, int);
struct key *binsearch(char *, struct key *, int);
/* подсчет ключевых слов Си: версия с указателями */
main()
{
char word[MAXWORD];
struct key *p;
while (getword(word, MAXWORD)!= EOF)
if (isalpha(word[0]))
if ((p = binsearch(word, keytab, NKEYS))!= NULL)
p->count++;
for (p = keytab; p < keytab + NKEYS; p++)
if (p->count > 0)
printf("%4d %s\n", p->count, p->word);
return 0;
}
/* binsearch: найти слово word в tab[0]...tab[n-1] */
struct key *binsearch(char *word, struct key *tab, int n)
{
int cond;
struct key *low = &tab[0];
struct key *high = &tab[n];
struct key *mid;
while (low < high) {
mid = low + (high - low) / 2;
if ((cond = strcmp(word, mid->word)) < 0)
high = mid;
else if (cond > 0)
low = mid + 1;
else
return mid;
}
return NULL;
}
Во-первых, описание функции binsearch должно отражать тот факт, что она возвращает указатель на struct key, а не целое, это объявлено как в прототипе функции, так и в функции binsearch. Если binsearch находит слово, то она выдает указатель на него, в противном случае она возвращает NULL. Во-вторых, к элементам keytab доступ в нашей программе осуществляется через указатели. Это потребовало значительных изменений в binsearch. Инициализаторами для low и high теперь служат указатели на начало и на место сразу после конца массива. Вычисление положения среднего элемента с помощью формулы
mid = (low + high) / 2 /* НЕВЕРНО */
не годится, поскольку указатели нельзя складывать. Однако к ним можно применить операцию вычитания, и так как high-low есть число элементов, присваивание
mid = low + (high-low) / 2
превратит mid в указатель на элемент, лежащий посередине между low и high.
СТРУКТУРЫСО ССЫЛКАМИ НА СЕБЯ.
Один из способов - постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Делать это передвижкой слов в линейном массиве не следует, - хотя бы потому, что указанная процедура тоже слишком долгая. Вместо этого мы воспользуемся структурой данных, называемой бинарным деревом.
В дереве на каждое отдельное слово предусмотрен "узел", который содержит:
- указатель на текст слова;
- счетчик числа встречаемости;
- указатель на левый сыновний узел;
- указатель на правый сыновний узел.
У каждого узла может быть один или два сына, или узел вообще может не иметь сыновей.
Узлы в дереве располагаются так, что по отношению к любому узлу левое поддерево содержит только те слова, которые лексикографически меньше, чем слово данного узла, а правое - слова, которые больше него. Вот как выглядит дерево, построенное для фразы " now is the time for all good men to come to the aid of their party " ("настало время всем добрым людям помочь своей партии"), по завершении процесса, в котором для каждого нового слова в него добавлялся новый узел:

Вернемся к описанию узла, которое удобно представить в виде структуры с четырьмя компонентами:
struct tnode { /* узел дерева */
char *word; /* указатель на текст */
int count; /* число вхождений */
struct tnode *left; /* левый сын */
struct tnode *right; /* правый сын */
};
Приведенное рекурсивное определение узла может показаться рискованным, но оно правильное. Структура не может включать саму себя, но ведь
struct tnode *left;
объявляет left как указатель на tnode, а не сам tnode.
ПОИСК В ТАБЛИЦЕ.
В этом параграфе, чтобы проиллюстрировать новые аспекты применения структур, мы напишем ядро пакета программ, осуществляющих вставку элементов в таблицы и их поиск внутри таблиц. Этот пакет - типичный набор программ, с помощью которых работают с таблицами имен в любом макропроцессоре или компиляторе. Рассмотрим, например, инструкцию #define. Когда встречается строка вида
#define IN 1
имя IN и замещающий его текст 1 должны запоминаться в таблице. Если затем имя IN встретится в инструкции, например в
state = IN;
это должно быть заменено на 1.
Существуют две программы, манипулирующие с именами и замещающими их текстами. Это install(s,t), которая записывает имя s и замещающий его текст t в таблицу, где s и t - строки, и lookup(s), осуществляющая поиск s в таблице и возвращающая указатель на место, где имя s было найдено, или NULL, если s в таблице не оказалось.
Алгоритм основан на хэш-поиске: поступающее имя свертывается в неотрицательное число (хэш-код), которое затем используется в качестве индекса в массиве указателей. Каждый элемент этого массива является указателем на начало связанного списка блоков, описывающих имена с данным хэш-кодом. Если элемент массива равен NULL, это значит, что имен с соответствующим хэш-кодом нет.
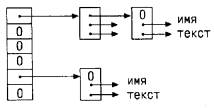
Блок в списке - это структура, содержащая указатели на имя, на замещающий текст и на следующий блок в списке; значение NULL в указателе на следующий блок означает конец списка.
struct nlist { /* элемент таблицы */
struct nlist *next; /* указатель на следующий элемент */
char *name; /* определенное имя */
char *defn; /* замещающий текст */
};
А вот как записывается определение массива указателей:
#define HASHSIZE 101
static struct nlist *hashtab[HASHSIZE]; /* таблица указателей */
Функция хэширования, используемая в lookup и install, суммирует коды символов в строке и в качестве результата выдаст остаток от деления полученной суммы на размер массива указателей. Это не самая лучшая функция хэширования, но достаточно лаконичная и эффективная.
/* hash: получает хэш-код для строки s */
unsigned hash(char *s)
{
unsigned hashval;
for (hashval = 0; *s!= '\0'; s++)
hashval = *s + 31 * hashval;
return hashval % HASHSIZE;
}
Беззнаковая арифметика гарантирует, что хэш-код будет неотрицательным.
Хэширование порождает стартовый индекс для массива hashtab; если соответствующая строка в таблице есть, она может быть обнаружена только в списке блоков, на начало которого указывает элемент массива hashtab с этим индексом. Поиск осуществляется с помощью lookup. Если lookup находит элемент с заданной строкой, то возвращает указатель на нее, если не находит, то возвращает NULL.
/* lookup: ищет s */
struct nlist *lookup(char *s)
{
struct nlist *np;
for (np = hashtab[hash(s)]; np!= NULL; np = np->next)
if (strcmp(s, np->name) == 0)
return np; /* нашли */
return NULL; /* не нашли */
}
В for -цикле функции lookup для просмотра списка используется стандартная конструкция
for (ptr = head; ptr!= NULL; ptr = ptr->next)
...
Функция install обращается к lookup, чтобы определить, имеется ли уже вставляемое имя. Если это так, то старое определение будет заменено новым. В противном случае будет образован новый элемент. Если запрос памяти для нового элемента не может быть удовлетворен, функция install выдает NULL.
struct nlist *lookup(char *);
char *strdup(char *);
/* install: заносит имя и текст (name, defn) в таблицу */
struct nlist *install(char *name, char *defn)
{
struct nlist *np;
unsigned hashval;
if ((np = lookup(name)) == NULL) { /* не найден */
np = (struct nlist *) malloc(sizeof(*np));
if (np == NULL || (np->name = strdup(name)) == NULL)
return NULL;
hashval = hash(name);
np->next = hashtab[hashval];
hashtab[hashval] = np;
} else /* уже имеется */
free((void *) np->defn); /* освобождаем прежний defn */
if ((np->defn = strdup(defn)) == NULL)
return NULL;
return np;
}