Для решения используется функция «Регрессия» из пакета анализа данных. Ниже - алгоритм решения.
1). Внести в лист Microsoft Excel исходные данные своего варианта.

Рисунок 5.1 – Исходные данные для задачи-1
2). Во вкладке «Данные » выбрать пункт «Анализ данных ». В появившемся окне найти инструмент «Регрессия ».

Рисунок 5.2 – Выбор инструмента анализа данных
3). Задать входные интервалы переменных X и Y и указать интервал вывода итогов регрессионного анализа (указать верхнюю левую ячейку диапазона вывода данных). Выбор пункта «Остатки » позволяет получить данные об остатках (ошибках) регрессии.
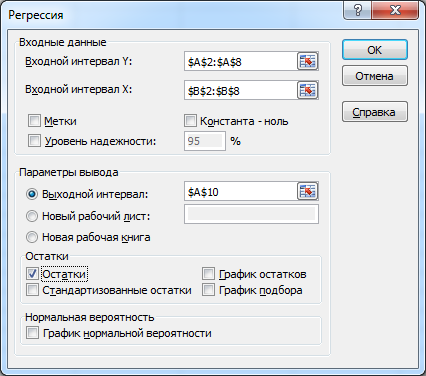
Рисунок 5.3 – Параметры построения парной регрессии
4). Табличный редактор проводит расчеты и выдаёт результаты в виде нескольких таблиц, см. рисунок 6.4.
Расшифруем полученные данные.
а). Таблица «Регрессионная статистика» содержит:
· «Множественный R» – здесь это коэффициент парной корреляции;
· «R-квадрат» – коэффициент детерминации;
· «Нормированный R-квадрат» – коэффициент детерминации, скорректированный на количество степеней свободы;
· «Стандартная ошибка» – квадратный корень из остаточной дисперсии;
· «Наблюдения» - количество наблюдений n.
б). Таблица «Дисперсионный анализ» содержит данные:
· столбец «df» - три числа степеней свободы: для регрессии, остатка и общее;
· столбец «SS» - три суммы квадратов отклонений: для регрессии, остатка и общее;
· столбец «MS » - два числа - дисперсии - на одну степень свободы: для регрессии и остатка;

Рисунок 5.4 –Итоги парного регрессионного анализа
· столбец «F » - значение СВ F, распределённой по ЗР Фишера;
· столбец «Значимость F » - p-значение для СВ F, т.е. вероятность того, что выполняется нулевая гипотеза о случайном отклонении коэффициента Фишера от нуля. В нашем примере p-значение ничтожно мало, поэтому гипотеза Н0 отклоняется.
в). Третья таблица - содержит значения параметров уравнения регрессии. Здесь представлены следующие данные:
· Столбец «Коэффициенты» - значения параметров уравнения регрессии. Строка «Y-пересечение» - параметр b0, строка «Переменная X1» параметр b1;
· столбец «Стандартная ошибка» - стандартные ошибки параметров уравнения регрессии. Строка «Y-пересечение» - стандартная ошибка для параметра b0, строка «Переменная X1» - стандартная ошибка для параметра b1;
· столбец «t-статистика» - значения t-критериев Стьюдента для параметров уравнения регрессии. Строка «Y-пересечение» - значение t-критерия Стьюдента для параметра b0, строка «Переменная X1» - значение t-критерия Стьюдента для параметра b1;
· столбец «p-значение» - p-значения t-критерия Стьюдента для параметров уравнения регрессии. Строка «Y-пересечение» - p-значение t-критерия Стьюдента для параметра b0, строка «Переменная X1» - p-значение t-критерия Стьюдента для параметра b1;
· столбцы «Верхние 95 %» и «Нижние 95 %» - интервалы для параметров уравнения регрессии, построенные с доверительной вероятностью 95 %.
г). Таблица «Вывод остатка» содержит данные:
· «Предсказанное Y» - значения y, рассчитанные по уравнению регрессии (ŷ).
· «Остатки» - разница между предсказанными значениями y и наблюдаемыми значениями y (e).
5). Конец решения.
6). Сохранить полученный результат для использования в письменной отчётной самостоятельной работе.