Тема 4. Множественная регрессия.
Вопросы
1. Модель множественной регрессии. Оценка параметров множественной регрессии методом наименьших квадратов (МНК).
2. Предпосылки применения метода наименьших квадратов (МНК).
3. Свойства оценок метода наименьших квадратов (МНК).
4. Проверка качества многофакторных регрессионных моделей
5. Оценка существенности параметров линейной регрессии.
6. Мультиколлинеарность. Последствия мультиколлинеарности. Способы обнаружения мультиколлинеарности. Способы избавления от мультиколлинеарности.
7. Отбор факторов при построении множественной регрессии. Процедура пошагового отбора переменных.
8. Оценка влияния факторов на зависимую переменную (коэффициенты эластичности, бета коэффициенты).
9.Анализ экономических объектов и прогнозирование с помощью модели множественной регрессии.
Материал к этой лекции изложен в учебном пособии [1] на стр. 207 – 241.
Функция 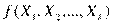 , оп исывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии 1. Уравнение регрессии показывает ожидаемое значение зависимой переменной
, оп исывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии 1. Уравнение регрессии показывает ожидаемое значение зависимой переменной 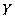 при определенных значениях зависимых переменных
при определенных значениях зависимых переменных 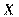 .
.
В зависимости от количества включенных в модель факторов Х модели делятся на однофакторные (парная модель регрессии) и многофакторные (модель множественной регрессии).
В зависимости от вида функции 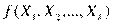 модели делятся на линейные и нелинейные.
модели делятся на линейные и нелинейные.
Модель множественной линейной регрессии имеет вид:
y i a= 0 a+ 1x i 1 a+2x i 2 a+…+ k x i k e+ i 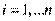 (2.1)
(2.1)
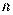 - количество наблюдений.
- количество наблюдений.
коэффициент регрессии a j показывает, на какую величину в среднем изменится результативный признак  , если переменную xj увеличить на единицу измерения, т. е. a j является нормативным коэффициентом.
, если переменную xj увеличить на единицу измерения, т. е. a j является нормативным коэффициентом.
Коэффициент 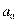 может быть отрицательным. Это означает, что область существования показателя не включает нулевых значений параметров. Если же а 0>0, то область существования показателя включает нулевые значения параметров, а сам коэффициент характеризует среднее значение показателя при отсутствии воздействий параметров.
может быть отрицательным. Это означает, что область существования показателя не включает нулевых значений параметров. Если же а 0>0, то область существования показателя включает нулевые значения параметров, а сам коэффициент характеризует среднее значение показателя при отсутствии воздействий параметров.
Анализ уравнения (2.1) и методика определения параметров становятся более наглядными, а расчетные процедуры существенно упрощаются, если воспользоваться матричной формой записи:
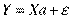 (2.2).
(2.2).
Где – вектор зависимой переменной размерности п ´ 1, представляющий собой п наблюдений значений  .
.
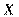 - матрица п наблюдений независимых переменных
- матрица п наблюдений независимых переменных 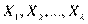 , размерность матрицы
, размерность матрицы 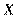 равна п ´ (k+1). Дополнительный фактор
равна п ´ (k+1). Дополнительный фактор 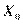 , состоящий из единиц, вводится для вычисления свободного члена. В качестве исходных данных могут быть временные ряды или пространственная выборка.
, состоящий из единиц, вводится для вычисления свободного члена. В качестве исходных данных могут быть временные ряды или пространственная выборка.
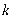 - количество факторов, включенных в модель.
- количество факторов, включенных в модель.
a — подлежащий оцениванию вектор неизвестных параметров размерности (k+1) ´ 1;
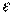 — вектор случайных отклонений (возмущений) размерности п ´ 1.
— вектор случайных отклонений (возмущений) размерности п ´ 1. 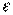 отражает тот факт, что изменение
отражает тот факт, что изменение  будет неточно описываться изменением объясняющих переменных
будет неточно описываться изменением объясняющих переменных 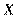 , так как существуют и другие факторы, неучтенные в данной модели.
, так как существуют и другие факторы, неучтенные в данной модели.
Таким образом,
Y = 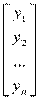 , X =
, X = 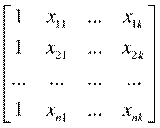 ,
,  , a =
, a =  .
.
Уравнение (2.2) содержит значения неизвестных параметров a0a,1a,2a,…,k  . Эти величины оцениваются на основе выборочных наблюдений, поэтому полученные расчетные показатели не являются истинными, а представляют собой лишь их статистические оценки. Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки (а именно такие регрессии и применяются на практике), имеет вид
. Эти величины оцениваются на основе выборочных наблюдений, поэтому полученные расчетные показатели не являются истинными, а представляют собой лишь их статистические оценки. Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки (а именно такие регрессии и применяются на практике), имеет вид
 , (2.3)
, (2.3)
где A — вектор оценок параметров; е — вектор «оцененных» отклонений регрессии, остатки регрессии е = Y - ХА;  —оценка значений Y, равная ХА.
—оценка значений Y, равная ХА.
Построение уравнения регрессии осуществляется, как правило, методом наименьших квадратов (МНК), суть которого состоит в минимизации суммы квадратов отклонений фактических значений результатного признака от его расчетных значений, т.е.:
 .
.
Формулу для вычисления параметров регрессионного уравнения по методу наименьших квадратов приведем без вывода
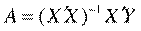 (2.4).
(2.4).
Для того чтобы регрессионный анализ, основанный на обычном методе наименьших квадратов, давал наилучшие из всех возможных результаты, должны выполняться следующие условия, известные как условия Гаусса – Маркова.
Первое условие. Математическое ожидание случайной составляющей в любом наблюдении должно быть равно нулю. Иногда случайная составляющая будет положительной, иногда отрицательной, но она не должна иметь систематического смещения ни в одном из двух возможных направлений.
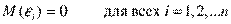
Фактически если уравнение регрессии включает постоянный член, то обычно это условие выполняется автоматически, так как роль константы состоит в определении любой систематической тенденции , которую не учитывают объясняющие переменные, включенные в уравнение регрессии.
Второеусловие означает, что дисперсия случайной составляющей должна быть постоянна для всех наблюдений. Иногда случайная составляющая будет больше, иногда меньше, однако не должно быть априорной причины для того, чтобы она порождала большую ошибку в одних наблюдениях, чем в других.
Эта постоянная дисперсия обычно обозначается 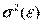 , или часто в более краткой форме
, или часто в более краткой форме 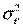 , а условие записывается следующим образом:
, а условие записывается следующим образом:
 .
.
Выполнимость данного условия называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью, (непостоянством дисперсии отклонений).
Третье условие предполагает отсутствие систематической связи между значениями случайной составляющейв любых двух наблюдениях. Например, если случайная составляющая велика и положительна в одном наблюдении, это не должно обусловливать систематическую тенденцию к тому, что она будет большой и положительной в следующем наблюдении. Случайные составляющие должны быть независимы друг от друга.
В силу того, что 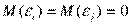 , данное условие можно записать следующим образом:
, данное условие можно записать следующим образом:

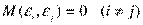
Возмущения  не коррелированны (условие независимости случайных составляющих в различных наблюдениях).
не коррелированны (условие независимости случайных составляющих в различных наблюдениях).
Это условие означает, что отклонения регрессии (а значит, и сама зависимая переменная) не коррелируют. Условие некоррелируемости ограничительно, например, в случае временного ряда 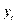 . Тогда третье условиеозначает отсутствие автокорреляции ряда
. Тогда третье условиеозначает отсутствие автокорреляции ряда 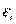 .
.
Четвертое условие состоит в том, что в модели (2.1) возмущение 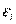 (или зависимая переменная
(или зависимая переменная 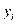 ) есть величина случайная, а объясняющая переменная
) есть величина случайная, а объясняющая переменная 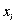 - величина неслучайная.
- величина неслучайная.
Если это условие выполнено, то теоретическая ковариация между независимой переменной и случайным членом равна нулю.
Наряду с условиями Гаусса— Маркова обычно также предполагается нормальность распределения случайного члена.
В тех случаях, когда выполняются предпосылки, оценки, полученные по МНК, будут обладать свойствами несмещенности, состоятельности и эффективности.
^ Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков - 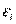 .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Качество модели регрессии оценивается по следующим направлениям:
1.
проверка качества всего уравнения регрессии;
2.
проверка значимости всего уравнения регрессии;
3.
проверка статистической значимости коэффициентов уравнения регрессии;
4.
проверка выполнения предпосылок МНК.
При анализе качества модели регрессии, в первую очередь, используется коэффициент детерминации, который определяется следующим образом:
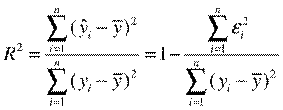 , (2.5)
, (2.5)
где 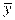 - среднее значение зависимой переменной,
- среднее значение зависимой переменной,
 - предсказанное (расчетное) значение зависимой переменной.
- предсказанное (расчетное) значение зависимой переменной.
^ Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе  к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R = 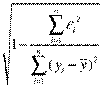 =
= 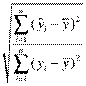 (2.6)
(2.6)
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Важным моментом является проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет.
Для проверки значимости модели регрессии используется F-критерий Фишера n. Если расчетное значение с 1= k nи 2 = (n - k - 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.
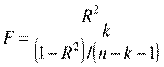 (2.7)
(2.7)
В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины ( ) называется стандартной ошибкой:
) называется стандартной ошибкой:
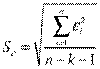 (2.8)
(2.8)
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
 , (2.9)
, (2.9)
где S aj — это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии aj. Величина Saj представляет собой квадратный корень из произведения несмещенной оценки дисперсии 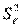 и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
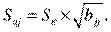
где 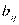 - диагональный элемент матрицы
- диагональный элемент матрицы 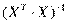 .
.
Если расчетное значение t-критерия с (n - k - 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
^ Проверка выполнения предпосылок МНК.
Рассмотрим выполнение предпосылки гомоскедастичности, или равноизменчивости случайной составляющей (возмущения).
Невыполнение этой предпосылки, т.е. нарушение условия гомоскедастичности возмущений означает, что дисперсия возмущения зависит от значений факторов. Такие регрессионные модели называются моделями с гетероскедастичностью возмущений.
^ Обнаружение гетероскедастичности
Для обнаружения гетероскедастичности обычно используют тесты, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда - Квандта, тест Глейзера, двусторонний критерий Фишера и другие [ 2 ].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта.
Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая 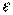 распределена нормально.
распределена нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда - Квандта необходимо выполнить следующие шаги.
1.
Упорядочение п наблюдений по мере возрастания переменной х.
2.
Исключение 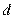 средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
3.
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора 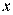 ) и определение по каждой из групп уравнений регрессии.
) и определение по каждой из групп уравнений регрессии.
4.
Определение остаточной суммы квадратов для первой регрессии 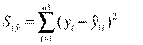 и второй регрессии
и второй регрессии 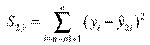 .
.
5.
Вычисление отношений 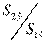 (или
(или 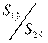 ). В числителе должна быть большая сумма квадратов.
). В числителе должна быть большая сумма квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-k и k2=n-n1-k, (k– число оцениваемых параметров в уравнении регрессии).
Если 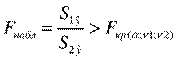 , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
^ Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b - коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты b(j).
Эластичность Y по отношению к Х(j) определяется как процентное изменение Y, отнесенное к соответствующему процентному изменению Х. В общем случае эластичности не постоянны, они различаются, если измерены для различных точек на линии регрессии. По умолчанию стандартные программы, оценивающие эластичность, вычисляют ее в точках средних значений:
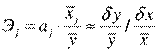
Эластичность ненормирована и может изменяться от - 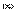 до + . Важно, что она безразмерна, так что интерпретация эластичности
до + . Важно, что она безразмерна, так что интерпретация эластичности 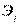 =2.0 означает, что если
=2.0 означает, что если 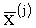 изменится на 1%, то это приведет к изменению
изменится на 1%, то это приведет к изменению 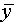 на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
Высокий уровень эластичности означает сильное влияние независимой переменной на объясняемую переменную.

где Sx j — среднеквадратическое отклонение фактора j
где 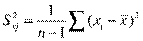
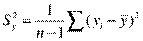 .
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта - коэффициентов (D j):
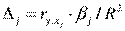
где 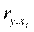 — коэффициент парной корреляции между фактором j (j = 1,...,m) и зависимой переменной.
— коэффициент парной корреляции между фактором j (j = 1,...,m) и зависимой переменной.
^ Прогнозирование с помощью модели множественной регрессии.
Уравнение регрессии применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т.е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза.
Для того чтобы определить область возможных значений результативного показателя, при рассчитанных значениях факторов следует учитывать два возможных источника ошибок: рассеивание наблюдений относительно линии регрессии и ошибки, обусловленные математическим аппаратом построения самой линии регрессии. Ошибки первого рода измеряются с помощью характеристик точности, в частности, величиной  . Ошибки второго рода обусловлены фиксацией численного значения коэффициентов регрессии, в то время как они в действительности являются случайными, нормально распределенными.
. Ошибки второго рода обусловлены фиксацией численного значения коэффициентов регрессии, в то время как они в действительности являются случайными, нормально распределенными.
Для линейной модели регрессии доверительный интервал рассчитывается следующим образом. Оценивается величина отклонения от линии регрессии (обозначим ее U):.
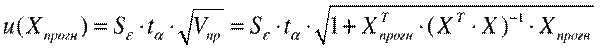 (2.10). где
(2.10). где 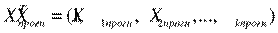 .
.
^