Компоненты информационных систем образующих вместе систему хранения и манипулировании данными, следующими:
Базы данных
Концептуальная схема
Информационные процессы
Базы данных – это набор сообщений, которые являются истинными для соответствующей материальной системы, а так же не противоречивы по отношению друг к другу и концептуальной системе.
Концептуальная схема представляет собой описание структуры всех единиц информации хранящихся в базе данных. Под структурой понимается вхождение одних единиц информации в состав других.
Информационные процессы – это механизм, который в ответ на получение команды выполняет операции с базами данных и с концептуальными схемами. Информационные процесс состоит из вычислительной системы и СУБД.
Вычислительная система – это ЭВМ, либо группа ЭВМ, соединенных каналами связи в вычислительную сеть.
СУБД – это комплекс программ, обеспечивающий централизованное хранение, накопление и выдачу данных вращающихся в базе данных.
6. Модели данных и их отличительные особенности.
· данные" в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы.
· Модель данных - это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. В зависимости от вида организации данных различают следующие важнейшие модели БД:
· иерархическую
· сетевую
· реляционную
· объектно-ориентированную
В иерархической БД данные представляются в виде древовидной структуры. Подобная структура БД удобна для работы с данными, упорядоченными иерархически. При оперировании данными со сложными логическими связями иерархическая модель оказывается слишком громоздкой.
В сетевой БД данные организуются в виде графа. Недостатком сетевой структуры является жесткость структуры и сложность ее организации.
Реляционная БД получила свое название от английского термина relation (отношение). Была предложена в 70-м году сотрудником фирмы IBM Эдгаром Коддом. Реляционная БД представляет собой совокупность таблиц, связанных отношениями. Достоинствами реляционной модели данных являются простота, гибкость структуры. Кроме того ее удобно реализовывать на компьютере. Большинство современных БД для персональных компьютеров являются реляционными.
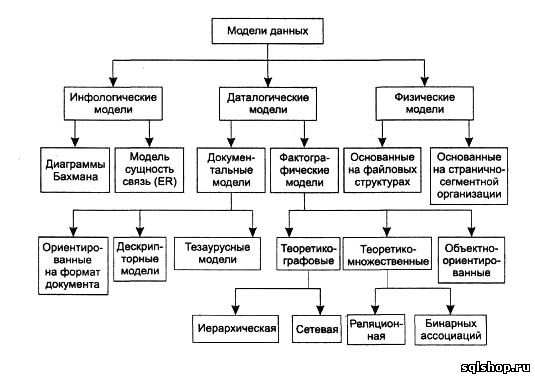
Инфологические модели используются на ранних стадиях проектирования баз данных для формального описания предметной области. Они содержат информацию о классах объектов, их свойствах и взаимосвязях, описания структур данных без привязки к какой-либо конкретной СУБД. Инфологические (или семантические) модели отражают в естественной и удобной для разработчиков и других пользователей форме информацию о предметной области в процессе разработки структуры будущей базы данных.
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных списков. Кроме того, современные СУБД широко используют страничную организацию данных. В этом случае база данных представлена минимальным количеством файлов, а задачи поиска, чтения и записи данных выполняет сама СУБД, а не операционная система. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных. Даталогические модели являются моделями концептуального уровня и разрабатываются для конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, ориентированные на формат документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Гораздо более простой и удобный, чем SGML, язык HTML (HyperText Markup Language – язык разметки гипертекста) позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. В настоящее время все большую популярность приобретает язык XML (eXtensible Markup Language – расширяемый язык разметки), позволяющий описывать документы произвольной структуры и содержания.
Тезаурусные модели основаны на принципе организации словарей. Они содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескриптпорные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имеет жесткую структуру и описывает документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной базе данных. Например, для БД, содержащей описание патентов, дескриптор содержит название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных ведется исключительно по дескрипторам, то есть по тем параметрам, которые характеризуют патент, а не по самому тексту патента.
Теоретико-графовые модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Математической основой таких моделей является теория графов.
Тезаурусные модели - это модели, которые основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике..
Дескрипторные модели - самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД.
Обьектно-ориентированные БД объединяют в себе две модели данных, реляционную и сетевую, и используются для создания крупных БД со сложными структурами данных.
7. Этапы проектирования информационных систем.





Управление данными
8. Архитектура системы управления базой данных.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 1:
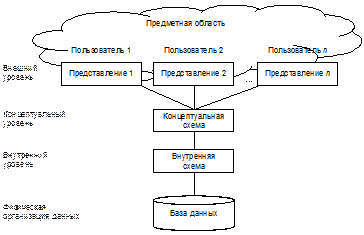
Рис. 1. Трехуровневая модель системы управления базой данных, предложенная ANSI
Архитектура включает три уровня: внутренний, концептуальный и внешний. В общих чертах они представляют собой следующее:
Внутренний - это уровень, наиболее близкий к физическому хранению, т.е. связанный со способами сохранения информации на физических устройствах хранения.
Внешний - наиболее близок к пользователям, т.е. он связан со способами представления данных для отдельных пользователей.
Концептуальный уровень - это промежуточный уровень между двумя первыми; другими словами, это центральное управляющее звено, где БД представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной БД.
1. Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое "видение" данных. Этот уровень определяет точку зрения на БД отдельных пользователей (приложений). Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
2. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира. Концептуальная схема - это определение концептуального представления. В большинстве существующих систем концептуальная схема в действительности представляет собой немного больше, чем простое объединение всех отдельных внешних схем с дополнительными средствами безопасности и правилами обеспечения целостности.
3. Внутреннее представление - это представление нижнего уровня всей БД. Внутреннее представление так же, как внешнее и концептуальное, не связанно с физическим уровнем. Это представление предполагает бесконечное линейное адресное пространство. Внутреннее представление описывается с помощью внутренней схемы, которая определяет не только различные типы хранимых записей, но также существующие индексы, способы представления хранимых полей, физическую последовательность хранимых записей и т.д.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем.
Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
9. Реляционная модель базы данных. Основные определения.


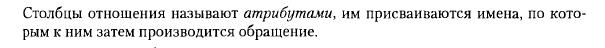
В реляционных базах данных кортеж — это элемент отношения, строка таблицы; упорядоченный набор из N элементов.
10. Принципы инфологического проектирования (модель «сущность-
связь).


Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов.
Основными понятиями ER-диаграммы являются сущность, связь и атрибут. Сущность — это реальный или виртуальный объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению. Связь — это соединение двух сущностей, при котором, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Атрибут является характеристикой сущности, значимой для рассматриваемой предметной области.
11. Операторы выборки данных языка SQL.
Язык запросов (Data Query Language) в SQL состоит из единственного оператора SELECT.
Оператор SELECT является фактически самым важным для пользователя и самым сложным оператором SQL. Он предназначен для выборки данных из таблиц, т.е. он, собственно, и реализует одно их основных назначение базы данных - предоставлять информацию пользователю.
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных.
Результатом выполнения оператора SELECT всегда является таблица. Таким образом, по результатам действий оператор SELECT похож на операторы реляционной алгебры. Любой оператор реляционной алгебры может быть выражен подходящим образом сформулированным оператором SELECT. Сложность оператора SELECT определяется тем, что он содержит в себе все возможности реляционной алгебры, а также дополнительные возможности, которых в реляционной алгебре нет.
Синтаксис оператора SELECT имеет следующий вид:
SELECT[ALL|DISTINCT](<Список полей>|*)FROM <Список таблиц>[WHERE <Предикат-условие выборки или соединения>][GROUP BY <Список полей результата>][HAVING <Предикат-условие для группы>][ORDER BY <Список полей, по которым упорядочить вывод>]Здесь ключевое слово ALL означает, что в результирующий набор строк включаются все строки, удовлетворяющие условиям запроса. Значит, в результирующий набор могут попасть одинаковые строки. И это нарушение принципов теории отношений (в отличие от реляционной алгебры, где по умолчанию предполагается отсутствие дубликатов в каждом результирующем отношении). Ключевое слово DISTINCT означает, что в результирующий набор включаются только различные строки, то есть дубликаты строк результата не включаются в набор.
Символ *. (звездочка) означает, что в результирующий набор включаются все столбцы из исходных таблиц запроса.
В разделе FROM задается перечень исходных отношений (таблиц) запроса.
В разделе WHERE задаются условия отбора строк результата или условия соединения кортежей исходных таблиц, подобно операции условного соединения в реляционной алгебре.
В разделе GROUP BY задается список полей группировки.
В разделе HAVING задаются предикаты-условия, накладываемые на каждую группу.
В части ORDER BY задается список полей упорядочения результата, то есть список полей, который определяет порядок сортировки в результирующем отношении. Например, если первым полем списка будет указана Фамилия, а вторым Номер группы, то в результирующем отношении сначала будут собраны в алфавитном порядке студенты, и если найдутся однофамильцы, то они будут расположены в порядке возрастания номеров групп.
12. Порядок выполнения операторов SQL.
Стадия 1. Выполнение одиночного оператора SELECT
Если в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно:
Шаг 1 (FROM). Вычисляется прямое декартовое произведение всех таблиц, указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A.
Шаг 2 (WHERE). Если в операторе SELECT присутствует раздел WHERE, то сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B.
Шаг 3 (GROUP BY). Если в операторе SELECT присутствует раздел GROUP BY, то строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
Шаг 4 (HAVING). Если в операторе SELECT присутствует раздел HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D.
Шаг 5 (SELECT). Каждая группа, полученная на шаге 4, генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT
Если в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1-й стадии, объединяются, вычитаются или пересекаются.
Стадия 3. Упорядочение результата
Если в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.
Инфокоммуникационные системы и сети
13. Основные показатели качества информационной сети.
качество - это совокупность свойств системы, позволяющих удовлетворять потребностям и ожиданиям потребителя. Рассмотрим основные показатели качества информационно-вычислительных сетей.
1. Полнота выполняемых функций. Сеть должна обеспечивать выполнение всех предусмотренных для нее функций по доступу ко всем ресурсам, по совместной работе узлов и по реализации всех протоколов и стандартов работы.
2. Производительность - среднее количество запросов пользователей сети, исполняемых за единицу времени.
3. Пропускная способность - важная характеристика производительности сети, определяется объемом данных, передаваемых через сеть (или ее звено - сегмент) за единицу времени. Часто используется другое название - скорость передачи данных.
4. Надежность сети - важная ее техническая характеристика, чаще всего характеризующаяся средним временем наработки на отказ.
5. Достоверность результантной информации - важная потребительская характеристика сети.
6. Безопасность информации в сети является важнейшим ее параметром, поскольку современные сети имеют дело с конфиденциальной информацией. Способность сети защитить информацию от несанкционированного доступа и определяет степень ее безопасности.
7. Прозрачность сети - еще одна ее потребительская характеристика, означающая невидимость особенностей внутренней архитектуры сети для пользователя, он должен иметь возможность обращаться к ресурсам сети как к локальным ресурсам своего собственного компьютера.
8. Масштабируемость - это возможность расширения сети без заметного снижения ее производительности.
9. Универсальность сети - возможность подключения к ней разнообразного технического оборудования программного обеспечения от разных производителей.
В состав этих показателей качества сети входят важные технические характеристики, которые могут быть оценены и выражены количественными значениями измеряемых или вычисляемых величин: производительность, пропускная способность, надежность, достоверность результантной информации, безопасность информации.
Производительность ИВС, иначе называемая вычислительной мощностью, определяется тремя характеристиками:
- временем реакции сети на запрос пользователя;
- пропускной способностью сети;
- задержкой передачи.
14. Физическая и логическая структуризация сети.
Физическая структуризация(ФС)
Применяется для увеличения длины сети и количества ее узлов и выполняется с помощью коммутационных устройств повторителей и концентраторов.
Повторитель удлиняет сеть, улучшает качество сигнала перед передачей, соединяет различные сегменты кабеля,
Концентратор - многопортовый повторитель (хаб), соединяет несколько физических сегментов. Концентраторы повторяют сигналы, пришедшие с одного из своих портов на других портах.
Концентратор Ethernet повторяет входные сигналы на всех своих портах, кроме того, с которого сигналы поступают.
Концентратор Token Ring повторяет входные сигналы, поступающие с некоторого порта только на одном порту, к которому подключен следующий в кольце компьютер.
ФС с помощью концентратора позволяет повысить надежность сети, т.к. он выполняет роль управляющего узла.
Логическая структуризация(ЛС)
Распространение трафика, предназначенного для узлов некоторого сегмента сети только в пределах этого сегмента наз-ся локализацией трафика.
ЛС – процесс разбиения сети на сегменты с локализованным трафиком.
Для ЛС используются такие коммуникационные устройства как мосты, коммутаторы, маршрутизаторы, шлюзы.
Мост делит разделяемую среду передачи на части – логические сегменты, передавая информацию из одного сегмента в другой, если такая передача необходима, т.е. если адрес узла назначения принадлежит другому сегменту. Этим мост изолирует трафик одной подсети от трафика другой, повышая общую производительность передачи.
Коммутатор является коммутационным мультиплексором, так как каждый его порт оснащен специальным процессором, который обрабатывает кадры по алгоритму моста.
Маршрутизатор изолирует трафик отдельный частей сети друг от друга. Маршрутизаторы образуют логические сегменты посредством явной адресации, т.к. используют составные числовые адреса. В этих адресах имеется поле номера сети, компьютеры, у которых значение этого поля одинаково принадлежат к одному сегменту. Шлюз применяется, когда необходимо объединить сети с разными типами системного и прикладного программного обеспечения. Логическая структуризация сети применяется для повышения производительности и безопасности сети и состоит в разбиении сети на сегменты таким образом, что основная часть трафика компьютеров каждого сегмента не выходит за пределы этого сегмента.
15. Алгоритмы и протоколы маршрутизации.
Для автоматического построения таблиц маршрутизации маршрутизаторы обмениваются информацией о топологии составной сети в соответствии со специальным служебным протоколом. Протоколы этого типа называются протоколами маршрутизации (или маршрутизирующими протоколами). Протоколы маршрутизации (например, RIP, OSPF, NLSP) следует отличать от собственно сетевых протоколов (например, IP, IPX). И те и другие выполняют функции сетевого уровня модели OSI - участвуют в доставке пакетов адресату через разнородную составную сеть. Но в то время как первые собирают и передают по сети чисто служебную информацию, вторые предназначены для передачи пользовательских данных, как это делают протоколы канального уровня. Протоколы маршрутизации используют сетевые протоколы как транспортное средство. При обмене маршрутной информацией пакеты протокола маршрутизации помещаются в поле данных пакетов сетевого уровня или даже транспортного уровня, поэтому с точки зрения вложенности пакетов протоколы маршрутизации формально следовало бы отнести к более высокому уровню, чем сетевой.
В том, что маршрутизаторы для принятия решения о продвижении пакета обращаются к адресным таблицам, можно увидеть их некоторое сходство с мостами и коммутаторами. Однако природа используемых ими адресных таблиц сильно различается. Вместо MAC - адресов в таблицах маршрутизации указываются номера сетей, которые соединяются в интерсеть. Другим отличием таблиц маршрутизации от адресных таблиц мостов является способ их создания. В то время как мост строит таблицу, пассивно наблюдая за проходящими через него информационными кадрами, посылаемыми конечными узлами сети друг другу, маршрутизаторы по своей инициативе обмениваются специальными служебными пакетами, сообщая соседям об известных им сетях в интерсети, маршрутизаторах и о связях этих сетей с маршрутизаторами.
С помощью протоколов маршрутизации маршрутизаторы составляют карту связей сети той или иной степени подробности. На основании этой информации для каждого номера сети принимается решение о том, какому следующему маршрутизатору надо передавать пакеты, направляемые в эту сеть, чтобы маршрут оказался рациональным. Результаты этих решений заносятся в таблицу маршрутизации.
Протоколы маршрутизации могут быть построены на основе разных алгоритмов, отличающихся способами построения таблиц маршрутизации, способами выбора наилучшего маршрута и другими особенностями своей работы.
Во всех описанных выше примерах при выборе рационального маршрута определялся только следующий (ближайший) маршрутизатор, а не вся последовательность маршрутизаторов от начального до конечного узла. В соответствии с этим подходом маршрутизация выполняется по распределенной схеме - каждый маршрутизатор ответственен за выбор только одного шага маршрута, а окончательный маршрут складывается в результате работы всех маршрутизаторов, через которые проходит данный пакет. Такие алгоритмы маршрутизации называются одношаговыми.
Существует и прямо противоположный, многошаговый подход - маршрутизация от источника. В соответствии с ним узел-источник задает в отправляемом в сеть пакете полный маршрут его следования через все промежуточные маршрутизаторы. При использовании многошаговой маршрутизации нет необходимости строить и анализировать таблицы маршрутизации. Это ускоряет прохождение пакета по сети, разгружает маршрутизаторы, но при этом большая нагрузка ложится на конечные узлы. Эта схема в вычислительных сетях применяется сегодня гораздо реже, чем схема распределенной одношаговой маршрутизации. Однако в новой версии протокола IP наряду с классической одношаговой маршрутизацией будет разрешена и маршрутизация от источника.
Одношаговые алгоритмы в зависимости от способа формирования таблиц маршрутизации делятся на три класса:
- алгоритмы фиксированной (или статической) маршрутизации;
- алгоритмы простой маршрутизации;
-алгоритмы адаптивной (или динамической) маршрутизации.
В алгоритмах фиксированной маршрутизации все записи в таблице маршрутизации являются статическими. Администратор сети сам решает, на какие маршрутизаторы надо передавать пакеты с теми или иными адресами, и вручную (например, с помощью утилиты route ОС Unix или Windows NT) заносит соответствующие записи в таблицу маршрутизации. Таблица, как правило, создается в процессе загрузки, в дальнейшем она используется без изменений до тех пор, пока ее содержимое не будет отредактировано вручную. Различают одномаршрутные таблицы, в которых для каждого адресата задан один путь, и многомаршрутные таблицы, определяющие несколько альтернативных путей для каждого адресата. В многомаршрутных таблицах должно быть задано правило выбора одного из маршрутов. Чаще всего один путь является основным, а остальные - резервными. Понятно, что алгоритм фиксированной маршрутизации с его ручным способом формирования таблиц маршрутизации приемлем только в небольших сетях с простой топологией.
В алгоритмах простой маршрутизации таблица маршрутизации либо вовсе не используется, либо строится без участия протоколов маршрутизации. Выделяют три типа простой маршрутизации:
- случайная маршрутизация, когда прибывший пакет посылается в первом попавшем случайном направлении, кроме исходного;
- лавинная маршрутизация, когда пакет широковещательно посылается по всем возможным направлениям, кроме исходного (аналогично обработке мостами кадров с неизвестным адресом);
- маршрутизация по предыдущему опыту, когда выбор маршрута осуществляется по таблице, но таблица строится по принципу моста путем анализа адресных полей пакетов, появляющихся на входных портах.
- Самыми распространенными являются алгоритмы адаптивной (или динамической) маршрутизации. Эти алгоритмы обеспечивают автоматическое обновление таблиц маршрутизации после изменения конфигурации сети. Протоколы, построенные на основе адаптивных алгоритмов, позволяют всем маршрутизаторам собирать информацию о топологии связей в сети, оперативно отрабатывая все изменения конфигурации связей. В таблицах маршрутизации при адаптивной маршрутизации обычно имеется информация об интервале времени, в течение которого данный маршрут будет оставаться действительным. Это время называют временем жизни маршрута (Time To Live, TTL).
Адаптивные алгоритмы маршрутизации должны отвечать нескольким важным требованиям. Во-первых, они должны обеспечивать, если не оптимальность, то хотя бы рациональность маршрута. Во-вторых, алгоритмы должны быть достаточно простыми, чтобы при их реализации не тратилось слишком много сетевых ресурсов, в частности они не должны требовать слишком большого объема вычислений или порождать интенсивный служебный трафик. И наконец, алгоритмы маршрутизации должны обладать свойством сходимости, то есть всегда приводить к однозначному результату за приемлемое время.
Адаптивные протоколы обмена маршрутной информацией, применяемые в настоящее время в вычислительных сетях, в свою очередь делятся на две группы, каждая из которых связана с одним из следующих типов алгоритмов:
- дистанционно-векторные алгоритмы (Distance Vector Algorithms, DVA);
- алгоритмы состояния связей (Link State Algorithms, LSA).
В алгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор, компонентами которого являются расстояния от данного маршрутизатора до всех известных ему сетей. Под расстоянием обычно понимается число хопов. Возможна и другая метрика, учитывающая не только число промежуточных маршрутизаторов, но и время прохождения пакетов по сети между соседними маршрутизаторами. При получении вектора от соседа маршрутизатор наращивает расстояния до указанных в векторе сетей на расстояние до данного соседа. Получив вектор от соседнего маршрутизатора, каждый маршрутизатор добавляет к нему информацию об известных ему других сетях, о которых он узнал непосредственно (если они подключены к его портам) или из аналогичных объявлений других маршрутизаторов, а затем снова рассылает новое значение вектора по сети. В конце концов, каждый маршрутизатор узнает информацию обо всех имеющихся в интерсети сетях и о расстоянии до них через соседние маршрутизаторы.
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях, В больших сетях они засоряют линии связи интенсивным широковещательным трафиком, к тому же изменения конфигурации могут отрабатываться по этому алгоритму не всегда корректно, так как маршрутизаторы не имеют точного представления о топологии связей в сети, а располагают только обобщенной информацией - вектором дистанций, к тому же полученной через посредников.
Алгоритмы состояния связей обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации. «Широковещательная» рассылка (то есть передача пакета всем непосредственным соседям маршрутизатора) используется здесь только при изменениях состояния связей, что происходит в надежных сетях не так часто. Вершинами графа являются как маршрутизаторы, так и объединяемые ими сети. Распространяемая по сети информация состоит из описания связей различных типов: маршрутизатор - маршрутизатор, маршрутизатор — сеть.
Чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами HELLO со своими ближайшими соседями. Этот служебный трафик также засоряет сеть, но не в такой степени как, например, RIP-пакеты, так как пакеты HELLO имеют намного меньший объем.
16. Техническое обеспечение информационных сетей.
Техническое обеспечение ИС составляют компьютеры, обслуживающие сети различных уровней (например, обрабатывающие запросы к поисковой машине в Интернет), средства связи компьютеров между собой и сетей друг с другом. Дело в том, что сети различаются по занимаемой ими позиции в иерархической структуре, вершиной которой является сеть Интернет. Сеть образуют соединенные каналами связи узлы. В узлах сетей могут располагаться следующие виды устройств.
Рабочая станция (workstation) – это так называемый клиент сети, т.е. компьютер через который пользователь получает доступ к ресурсам сети (информационным, вычислительным и пр.).
Сетевой компьютер (Net PC) – клиент сети, работа которого возможна только при наличии в сети сервера приложений. Он не имеет собственной внешней памяти, аппаратное обеспечение такого компьютера максимально упрощено и удешевлено. NetPC комплектуется монитором, клавиатурой, «мышью», сетевая карта поддерживает режим BootROM, т.е. удаленную загрузку (загрузку по сети). Задача такого ПК отправлять запрос на сервер приложений, который его обрабатывает и передает данные обратно на Net PC.
Сервер (server) – это высокопроизводительный и очень надежный компьютер, выделенный для координации работы узлов сети, т.е. он выполняет все перечисленные нами задачи ИВС. Сервер часто имеет узкую специализацию, т.е. задействован под конкретное приложение и тогда он называется сервером приложений.
Устройство, к которому подключается множество кабелей от других устройств, удобно называть концентратором. Разъем подключения кабеля к устройству называется портом. Устройством может выполнять функции повторителя, коммутатора и маршрутизатора.
Повторитель (hub) – обеспечивает трансляцию принятого сигнала на одном порту на все остальные порты.
Коммутатор (switch) – транслирует кадры, руководствуясь их адресн