Тема: Основные понятия корреляционно-регрессионного анализа.
Регрессионный анализ – раздел математической статистики, связанный с построением функциональных зависимостей между случайной величиной Y и одной или несколькими случайными величинами (X1, X2, …, Xn).

Виды зависимостей.
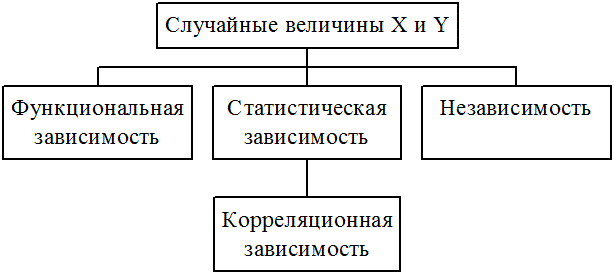
 Функциональная зависимость: Y = j(Х) Если каждому возможному значению случайной величины Х соответствует одно возможное значение случайной величины Y, то случайное величина Х имеет распределение f(Х). Если Y = j(Х) – строго монотонная функция, следовательно существует обратная функция Х = Y(Y), то плотность случайной величины Y имеет вид: g (Y) = f(Y(Y))×Y¢(Y). Строгая функциональная зависимость реализуется редко.
Функциональная зависимость: Y = j(Х) Если каждому возможному значению случайной величины Х соответствует одно возможное значение случайной величины Y, то случайное величина Х имеет распределение f(Х). Если Y = j(Х) – строго монотонная функция, следовательно существует обратная функция Х = Y(Y), то плотность случайной величины Y имеет вид: g (Y) = f(Y(Y))×Y¢(Y). Строгая функциональная зависимость реализуется редко.
Статистической зависимостью называется зависимость, при которой изменение одной из величин влечёт изменение распределения других величин.
Частным случаем статистической зависимости является корреляционная зависимость, при которой изменение одной из величин изменяет среднее значение других.
Зависимая величина Y называется откликом, а величины X – факторами, влияющими на отклик.
Независимые переменные связаны с зависимой посредством функции линейной или нелинейной. Линейная функция называется парной (множественной) линейной регрессией.
Регрессионный анализ используется для: 1) описания зависимости между переменными с целью установления наличия возможной причинной связи; 2) получения предиктора для зависимой переменной.


Коэффициент ковариации. Коэффициент корреляции.
Свойство дисперсии случайной величины: дисперсия суммы случайных величин:
D(X ± Y) = M[(X ± Y)²] - [M(X ± Y)]² = M(X² ± 2XY + Y²) – M(X² ± 2XY + Y²) =
= M(X²) – [M(X)]² + M(Y²) – [M(Y)]² ± 2(M(XY) - M(X)M(Y)) = D(X) + D(Y) ±
± 2cov(X, Y),
где cov(X, Y) = M[(X - M(X))(Y - M(Y)] = M(XY) - M(X)M(Y) – коэффициент ковариации (совместной вариации) случайных величин Х и Y.
Для независимых случайных величин cov(X,Y)=0. Для случайных величин, имеющих тенденцию колебаться в одну сторону – положителен. Для случайных величин, имеющих тенденцию колебаться в разные стороны – отрицателен. Коэффициент ковариации может принимать значения по всей числовой прямой и имеет размерность.
Поэтому вводят нормированный коэффициент ковариации, или коэффициент корреляции:

Коэффициент корреляции меняется от –1 до +1, т.е. ½R½ £ 1:
1` R =0 для независимых случайных величин
2` 0 < ½R½ < 0,3 слабая зависимость
3` 0,3 £ ½R½ < 0,6 средняя зависимость
4` 0,6 £ ½R½ < 0,9 сильная зависимость
5` 0,9 £ ½R½ < 1 очень сильная зависимость
6` R = ±1 функциональная зависимость
Если R = 0, то это не всегда означает независимость случайной величины (лучше говорить некоррелированности). Для нормальных случайных величин независимость Û некоррелированность.
2. Диаграммы рассеяния и корреляционная таблица.
 В психологических исследованиях (как и в биологических, медицинских и т. д.) имеет место статистический разброс данных: при одном и том же значении одной величины другая величина принимает несколько значений и наоборот. Графическое изображение экспериментальных данных называется диаграммой рассеяния.
В психологических исследованиях (как и в биологических, медицинских и т. д.) имеет место статистический разброс данных: при одном и том же значении одной величины другая величина принимает несколько значений и наоборот. Графическое изображение экспериментальных данных называется диаграммой рассеяния.
Необходимо ответить на вопросы:
1) какой вид имеет тенденция;
2) какая теснота между тенденцией и разбросом данных.
Для этого необходимо несгруппированные данные подвергнуть первичной обработке.
Не сгруппированные:
| N п/п | хi | уi |
| х1 | у1 | |
| х2 | у2 | |
| … | … | … |
| п | хп | уп |

| 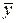
|
Сгруппированные:
Корреляционная таблица (двумерная гистограмма)
| x1 | x2 | … | xk | пyj | |
| у1 | п11 | п21 | … | nk1 | ny2 |
| у2 | п12 | п22 | … | nk2 | ny2 |
| … | … | … | … | … | … |
| уе | п1е | п2e | … | nke | nye |
| пхi | пх1 | пх2 | … | nхk | N |
xi, yj – середины интервалов

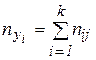 N =
N = 
Уравнение регрессии и их выборочные оценки
Рассмотрим не сгруппированные данные и их графическое представление (диаграмму рассеяния):
 Вопросы: Каков вид зависимости? Как найти? Как точно описывает? и т.д.
Вопросы: Каков вид зависимости? Как найти? Как точно описывает? и т.д.
Ответы: Существует несколько вариантов, но они сводятся к одному – аппроксимация (квадратическая, тригонометрическая, полиномиальная, сплайн и т.д.).
Наиболее простой вариант – квадратическая аппроксимация, которая обосновывает метод наименьших квадратов.
Суть его состоит в том, что сумма квадратов отклонений между экспериментальным и теоретическим значениями должна быть минимальной:

Если утеор = f(х, а, в, с, …), тогда

Из теории функции нескольких переменных известно, что для минимума необходимо равенство нулю всех частных производных:

Решив данную систему относительно неизвестных коэффициентов а, b, с, … мы получим уравнения, которые называются уравнениями регрессии:

Для линейной зависимости:

где rу/х и rх/у – выборочные коэффициенты Y на X и X на Y
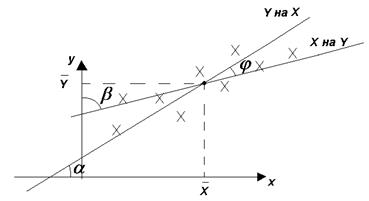 tga = rу/х
tga = rу/х
tgb = rх/у
j ¹ 0
Для независимых случайных величин j = p / 2.
Уравнения регрессии (линейной зависимости) лучше записать в виде:

Как вычислить  ?
?
Существует два способа:
1) найти частные производные и решить полученную систему;
2) составить систему нормальных уравнений и решить её.
Используем второй способ для простой линейной зависимости у=ах+b
Зная yi=axi+b, умножив на xi, получим xiyi = axi2 + bxi и просуммировав по всем i от 1 до п, получим систему нормальных уравнений:

Разделив на п оба уравнения и введя обозначения средних величин, получим систему:


Умножив второе уравнение на 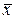 и вычтя его из первого, имеем:
и вычтя его из первого, имеем:

Формулы для нахождения средних величин:




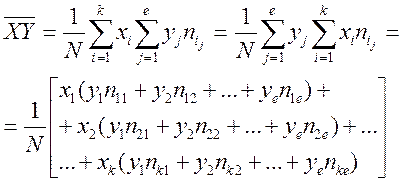
Используются данные корреляционной таблицы.