Подобно ячейкам динамической, триггеры объединяются в единую матрицу, состоящую из строк (row) и столбцов (column), последние из которых так же называются битами (bit).
В отличии от ячейки динамической памяти, для управления которой достаточно всего одного ключевого транзистора, ячейка статической памяти управляется как минимум двумя. Это не покажется удивительным, если вспомнить, что триггер, в отличии от конденсатора, имеет раздельные входы для записи логического нуля и единицы соответственно. Таким образом, на ячейку статической памяти расходуется целых восемь транзисторов (см. рис.2) - четыре идут, собственно, на сам триггер и еще два - на управляющие "защелки".

Рис. 2. Устройство 6-транзистроной одно-портовой ячейки SRAM-памяти
Причем, шесть транзисторов на ячейку - это еще не предел! Существуют и более сложные конструкции! Основной недостаток шести транзисторной ячейки заключается в том, что в каждый момент времени может обрабатываться всего лишь одна строка матрицы памяти. Параллельное чтение ячеек, расположенных в различных строках одного и того же банка невозможно, равно как невозможно и чтение одной ячейки одновременно с записью другой.
Этого ограничения лишена многопортовая память. Каждая ячейка многопортовой памяти содержит один-единственный триггер, но имеет несколько комплектов управляющих транзисторов, каждый из которых подключен к "своим" линиям ROW и BIT, благодаря чему различные ячейки матрицы могут обрабатываться независимо. Такой подход намного более прогрессивен, чем деление памяти на банки. Ведь, в последнем случае параллелизм достигается лишь при обращении к ячейкам различных банков, что не всегда выполнимо, а много портовая память допускает одновременную обработку любых ячеек, избавляя программиста от необходимости вникать в особенности ее архитектуры.
Наиболее часто встречается двух - портовая память, устройство ячейки которой изображено на рис. 3. (внимание! это совсем не та память которая, в частности, применяется в кэше первого уровня микропроцессоров Intel Pentium). Нетрудно подсчитать, что для создания одной ячейки двух - портовой памяти расходуется восемь транзисторов. Пусть емкость кэш памяти составляет 32 Кб, тогда только на одно ядро уйдет свыше двух миллионов транзисторов! 
Рис. 3. Устройство 8-транзистроной двух портовой ячейки SRAM-памяти
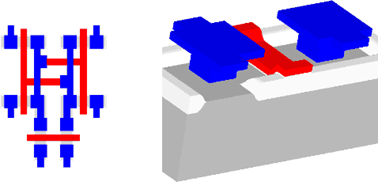
Рис. 3. Ячейка динамической памяти воплощенная в кристалле
Типы статической памяти
Существует как минимум три типа статической памяти: асинхронная, синхронная и конвейерная. Все они практически ничем не отличаются от соответствующих им типов динамической памяти.
Асинхронная статическая память
Асинхронная статическая память работает независимо от контроллера и потому, контроллер не может быть уверен, что окончание цикла обмена совпадет с началом очередного тактового импульса. В результате, цикл обмена удлиняется по крайней мере на один такт, снижая тем самым эффективную производительность. "Благодаря" последнему обстоятельству, в настоящее время асинхронная память практически нигде не применяется (последними компьютерами, на которых она еще использовались в качестве кэша второго уровня, стали "трешки" - машины, построенные на базе процессора Intel 80386).
Синхронная статическая память
Синхронная статическая память выполняет все операции одновременно с тактовыми сигналами, в результате чего время доступа к ячейке укладывается в один-единственный такт. Именно на синхронной статической памяти реализуется кэш первого уровня современных процессоров.
Конвейерная статическая память
Конвейерная статическая память представляет собой синхронную статическую память, оснащенную специальными "защелками", удерживающими линии данных, что позволяет читать (записывать) содержимое одной ячейки параллельно с передачей адреса другой.
Так же, конвейерная память может обрабатывать несколько смежных ячеек за один рабочий цикл. Достаточно передать лишь адрес первой ячейки пакета, а адреса остальных микросхема вычислит самостоятельно, - только успевай подавать (забирать) записывание (считанные) данные!
За счет большей аппаратной сложности конвейерной памяти, время доступа к первой ячейке пакета увеличивается на один такт, однако, это практически не снижает производительности, т.к. все последующие ячейки пакета обрабатываются без задержек.
Конвейерная статическая память используется в частности в кэше второго уровня микропроцессоров Pentium-II и ее формула выглядит так: 2-1-1-1.
Динамическая память.
Все переменные, объявленные в программе, размещаются в одной непрерывной области оперативной памяти, которая называется сегментом данных. Длина сегмента данных определяется архитектурой микропроцессоров 8086 и составляет 65 536 байт, что может вызвать известные затруднения при обработке больших массивов данных.
С другой стороны, объем памяти ПК (обычно не менее 640 Кбайт) достаточен для успешного решения задач с большой размерностью данных. Выходом из положения может служить использование так называемой динамической памяти.
Динамическая память — это оперативная память ПК, предоставляемая программе при ее работе, за вычетом сегмента данных F4 Кбайт), стека (обычно 16 Кбайт) и собственно тела программы.
Размер динамической памяти можно варьировать в широких пределах (см. приложение 1). По умолчанию этот размер определяется всей доступной памятью ПК и, как правило, составляет не менее 200—300 Кбайт. Динамическая память — это фактически единственная возможность обработки массивов данных большой размерности. Без динамической памяти трудно или невозможно решить многие практические задачи.
Такая необходимость возникает, например, при разработке систем автоматизированного проектирования (САПР): размерность математических моделей, используемых в САПР, может значительно отличаться в разных проектах; статическое (т. е. на этапе разработки САПР) распределение памяти в этом случае, как правило, невозможно. Наконец, динамическая память широко применяется для временного запоминания данных при работе с графическими и звуковыми средствами ПК.
Динамическое размещение данных означает использование динамической памяти непосредственно при работе программы. В отличие от этого, статическое размещение осуществляется компилятором Турбо Паскаля в процессе компиляции программы. При динамическом размещении заранее не известны ни тип, ни количество размещаемых данных, к ним нельзя обращаться по именам, как к статическим переменным.
Оперативная память ПК представляет собой совокупность элементарных ячеек для хранения информации — байтов, каждый из которых имеет собственный номер. Эти номера называются адресами, они позволяют обращаться к любому байту памяти.
Турбо Паскаль предоставляет в распоряжение программиста гибкое средство управления динамической памятью — так называемые указатели. Указатель — это переменная, которая в качестве своего значения содержит адрес байта памяти.
В ПК адреса задаются совокупностью двух шестнадцатиразрядных слов, которые называются сегментом и смещением. Сегмент — это участок памяти, имеющий длину 65 536 байт F4 Кбайт) и начинающийся с физического адреса, кратного 16 (т. е. О, 16, 32, 48 и т. д.). Смещение указывает, сколько байтов от начала сегмента необходимо пропустить, чтобы обратиться к нужному адресу. Адресное пространство ПК составляет 1 Мбайт (речь идет о так называемой стандартной памяти ПК; на современных компьютерах с процессорами 80386 и выше адресное пространство составляет 4 Гбайт, однако в Турбо Паскале нет средств, поддерживающих работу с дополнительной памятью; при использовании среды Borland Pascal with Objects 7.0 такая возможность имеется).
Для адресации в пределах 1 Мбайт нужно 20 двоичных разрядов, которые получаются из двух шестнадцатиразрядных слов (сегмента и смещения) следующим образом (рис. 6.1): содержимое сегмента смещается влево на 4 разряда, освободившиеся правые разряды заполняются нулями, результат складывается с содержимым смещения. Фрагмент памяти в 16 байт называется параграфом, поэтому можно сказать, что сегмент адресует память с точностью до параграфа, а смещение — с точностью до байта. Каждому сегменту соответствует непрерывная и отдельно адресуемая область памяти. Сегменты могут следовать в памяти один за другим без промежутков или с некоторым интервалом, или, наконец, перекрывать друг друга. Таким образом, по своей внутренней структуре любой указатель представляет собой совокупность двух слов (данных типа WORD), трактуемых как сег- 154.
С помощью указателей можно размещать в динамической памяти любой из известных в Турбо Паскале типов данных. Лишь некоторые из них (BYTE, CHAR, SHORTINT, BOOLEAN) занимают во внутреннем пред- представлении один байт, остальные — несколько смежных. Поэтому на самом деле указатель адресует лишь первый байт данных. 6.3. Объявление указателей.
Как правило, в Турбо Паскале указатель связывается с некоторым типом данных. Такие указатели будем называть типизированными. Для объявления типизированного указателя используется значок л, который помещается перед соответствующим типом, например: var pi AInteger; р2: "Real; type PerconPomter = "PcrconRecord; PerconRecord = record Name: String; Job: String; Next: PerconPomter end; Обратите внимание: при объявлении типа PerconPointer мы сослались на тип PerconRecord, который предварительно в программе объявлен не был. Как уже отмечалось, в Турбо Паскале последовательно проводится в жизнь принцип, в соответствии с которым перед использованием какого-либо идентификатора он должен быть описан. Исключение сделано только для указателей, которые могут ссылаться на еще не объявленный тип данных. Это сделано не случайно.
Динамическая память дает возможность реализовать широко применяемую в некоторых программах организацию данных в виде списков. Каждый элемент списка имеет в своем составе указатель на соседний элемент (рис. 6.2), что обеспечивает возможность просмотра и коррекции списка. Если бы в Турбо Паскале не было этого исключения, реализация списков была бы значительно затруднена. В Турбо Паскале можно объявлять указатель и не связывать его при этом с каким-либо конкретным типом данных. Для этого служит стандартный тип POINTER, например: var р: pointer.
1-й элемент списка Указатель — 2-й элемент списка Последний элемент списка NIL Рис. 6.2. Списочная структура данных Указатели такого рода будем называть нешипизированными. Поскольку нети- пизированные указатели не связаны с конкретным типом, с их помощью удобно динамически размещать данные, структура и тип которых меняются в ходе работы программы.
Как уже говорилось, значениями указателей являются адреса переменных в памяти, поэтому следовало бы ожидать, что значение одного указателя можно передавать другому. На самом деле это не совсем так. В Турбо Паскале можно передавать значения только между указателями, связанными с одним и тем же типом данных. Если, например, объявлены переменные pl,p2; "Integer; рЗ: лЯоа1; рр: pointer; то присваивание pl:= р2; вполне допустимо, в то время как присваивание pl:= рЗ; запрещено, поскольку Р1 и РЗ указывают па разные типы данных. Это огра- ограничение, однако, не распространяется на нетипизированные указатели, по- поэтому мы могли бы записать рр:- рЗ, pl:= рр; и тем самым достичь нужного результата.
Читатель вправе задать вопрос, стоило ли вводить ограничения и тут же давать средства для их обхода. Все дело в том, что любое ограничение, с одной стороны, вводится для повышения надежности программ, а с другой — уменьшает мощность языка, делает его менее пригодным для каких-то Применений.
В Турбо Паскале немногочисленные исключения в отношении типов данных придают языку необходимую гибкость, но их использование требует от программиста дополнительных усилий и таким образом свиде- свидетельствует о вполне осознанном действии.
Выделение и освобождение динамической памяти Вся динамическая память в Турбо Паскале рассматривается как сплошной массив байтов, который называется кучей. Физически куча располагается в старших адресах сразу за областью памяти, которую занимает тело программы. Начало кучи хранится в стандартной переменной HeapOrg (рис. 6.3), ко- конец — в переменной HeapEnd. Текущую границу незанятой динамической памяти содержит переменная Heapptr. Памяхь под любую динамически размещаемую переменную выделяется процедурой NEW. Параметром обращения к этой процедуре является типизированный указатель. В результате обращения указатель приобретает значение, соответствующее динамическому адресу, начиная с которого можно разместить данные, например: var i, j: "Integer; г: AReal; begin New(i); end.
После выполнения этого фрагмента указатель 1 приобретет значение, которое перед этим имел указатель кучи HEAPPTR, а сам HEAPPTR увеличит свое значение на 2, т. к. длина внутреннего представления типа INTEGER, с кото- которым связан указатель I, составляет 2 байта (на самом деле это не совсем гак: память под любую переменную выделяется порциями, кратными 8 байтам — см. разд. 6.7). Оператор new (г); вызовет еще раз смещение указателя HEAPPTR, но теперь уже на 6 байт, потому что такова длина внутреннего представления типа REAL Аналогичным образом выделяется память и для переменной любого другого типа. После того как указатель приобрел некоторое значение, т. е. стал указывать на конкретный физический байт памяти, по этому адресу можно разместить любое значение соответствующего типа. Для этого сразу за указателем без каких-либо пробелов ставится значок л, например: i = 2, (В область памяти i помещено значение 2} гл = 2*pi; {В область памяти г помещено значение 6.28}\
Расположение кучи в памяти ПК Таким образом, значение, на которое указывает указатель, т. е. собственно данные, размещенные в куче, обозначаются значком Л, который ставится сразу за указателем. Если за указателем нет значка, то имеется в виду ад- адрес, по которому размещены данные. Имеет смысл еще раз задуматься над только что сказанным: значением любого указателя является адрес, а чтобы указать, что речь идет не об адресе, а о тех данных, которые размещены по этому адресу, за указателем ставится Л. Если вы четко уясните себе это, у вас не будет проблем при работе с динамической памятью. Динамически размещенные данные можно использовать в любом месте программы, где это допустимо для констант и переменных соответствую- соответствующего типа, например: гЛ:<* sqr (rA) + \Л - 17; Разумеется, совершенно недопустим оператор г:= sqr(rA) + iA - 17; т. к. указателю r нельзя присвоить значение вещественного выражения. Точно так же недопустим оператор гл:= sqr (г); поскольку значением указателя r является адрес, и его (в отличие от того значения, которое размещено по этому адресу) нельзя возводить в квадрат. Ошибочным будет и такое присваивание: =х; 158 Ядро Турбо Паскаля т. к. вещественным данным, на которые указывает R, нельзя присвоить значение указателя (адрес).
Динамическую память можно не только забирать из кучи, но и возвращать обратно. Для этого используется процедура DISPOSE. Например, операторы disposed); dispose(i); вернут в кучу 8 байт, которые ранее были выделены указателям 1 и R (см. выше). Отметим, что процедура dtspose (PTR) не изменяет значения указателя PTR, а лишь возвращает в кучу память, ранее связанную с этим указателем. Од- Однако повторное применение процедуры к свободному указателю приведет к возникновению ошибки периода исполнения. Освободившийся указатель программист может пометить зарезервированным словом NIL. Помечен ли какой-либо указатель или нет, можно проверить следующим образом: const р: 4lGal = NIL; begin if p = NIL then new(p); dispose(p); p: NIL; end. Никакие другие операции сравнения над указателями не разрешены. Приведенный выше фрагмент иллюстрирует предпочтительный способ объявления указателя в виде типизированной константы (см. главу 7) с одновременным присвоением ему значения NIL. Следует учесть, что начальное значение указателя (при его объявлении в разделе переменных) может быть произвольным. Использование указателей, которым не присвоено значение процедурой NEW или другим способом, не контролируется системой и может привести к непредсказуемым результатам.
Чередование обращений к процедурам NEW и DISPOSE обычно приводит к "ячеистой" структуре памяти. Дело в том, что все операции с кучей выполняются под управлением особой подпрограммы, которая называется администратором кучи. Она автоматически пристыковывается к вашей программе компоновщиком Турбо Паскаля и ведет учет всех свободных фрагментов в куче. При очередном обращении к процедуре NEW эта подпрограмма отыскивает наименьший свободный фрагмент, в котором еще может разместиться.
Адрес начала найденного фрагмента возвращается в указателе, а сам фрагмент или его часть нужной длины помечается как занятая часть кучи. (Подробнее о работе администратора кучи см. в разд. 6.7). Другая возможность состоит в освобождении целого фрагмента кучи. С этой целью перед началом выделения динамической памяти текущее значение указателя HEAPPTR запоминается в переменной-указателе с помощью процедуры MARK Теперь можно в любой момент освободить фрагмент кучи, на- начиная от того адреса, который запомнила процедура MARK, и до конца дина- динамической памяти.
Для этого используется процедура RELEASE Например: var p,pl,р?, рЗ,р4,р5: ЛInteger; begin new(pi); new (p.°); mark(p); new (pi); new(p4); new(p5) release (p) f end. В этом примере процедурой MARK{P) в указатель р было помещено текущее значение HEAPPTR, однако память под переменную не резервировалась. Обращение RELEASE (P) освободило динамическую память от помеченного места до конца кучи. На рис. 6.4 проиллюстрирован механизм работы процедур NEW—DISPOSE И NEW—MARK—RELEASE ДЛЯ рассмотренного Примера и для случая, когда вместо оператора RELEASE (Р) используется, например, DISPOSE (РЗ). Следует учесть, что вызов RELEASE уничтожает список свободных фрагментов в куче, созданных до этого процедурой DISPOSE, поэтому совместное использование обоих механизмов освобождения памяти в рамках одной программы не рекомендуется.
Как уже отмечалось, параметром процедуры NEW может быть только типизированный указатель. Для работы с нетипизированными указателями служат процедуры: GETMEM (P, SIZE) — резервирование памяти; О FREEMEM(P, SIZE) освобождение памяти.
Понятно, что наличие нетипизированных указателей в Турбо Паскале (в стандартном Паскале их нет) открывает широкие возможности неявного преобразования типов. К сожалению, трудно обнаруживаемые ошибки в программе, связанные с некорректно используемыми обращениями к про- процедурам NEW и DISPOSE, также могут привести к нежелательному преобразо- преобразованию типов. В самом деле, пусть имеется программа: {i:- HeapOrg; HeapPtr;-- HeapOrg + 2} {j:- HeapOrg) {HeapPtr;- HeapOrg} {r:= HeapOrg; HeapPtr -•¦» HeapOrg + бу! i ~i * r: " begin new(i); j:= i; Y:= 2 dispose new(r); Integer; Real; r (i); гл:= pi; end.
Что будет выведено на экран дисплея? Чтобы ответить на этот вопрос, про- проследим за значениями указателя HEAPPTR.
Перед исполнением программы этот указатель имел значение адреса начала кучи HEAPORG, которое и было передано указателю I, а затем и J. После выполнения DISPOSE (I) указатель кучи вновь приобрел значение HEAPORG, этот адрес передан указателю R в процедуре NEW(R).
После того как по адресу R разместилось вещественное число я = 3,14159, первые 2 байта кучи оказались заняты под часть внутрен- внутреннего представления этого числа. В то же время j все еще сохраняет адрес HEAPORG, поэтому оператор WRITELN(OT) будет рассматривать 2 байта числа л как внутреннее представление целого числа (ведь j — это указатель на тип INTEGER) и выведет 8578. 6.5. Использование указателей Подведем некоторые итоги. Итак, динамическая память составляет 200— 300 Кбайт или больше, ее начало хранится в переменной HEAPORG, а конец соответствует адресу переменной HEAPEND.
Текущий адрес свободного участка динамической памяти хранится в указателе HEAPPTR Посмотрим, как можно использовать динамическую память для размещения крупных массивов данных. Пусть, например, требуется обеспечить доступ к элементам прямоугольной матрицы 100x200 типа EXTENDED Для размещения такого массива требуется память размером 200 000 байт A00x200x10). Казалось бы, эту проблему можно решить следующим образом: var i,j: Integer; PtrArr: array [1..100, 1..200] of AReal; begin for l:= 1 to 100 do for j:= 1 to 200 do new(PtiArr[i,]l); and. Теперь к любому элементу вновь созданного динамического массива можно обратиться по адресу, например: PtrArr[1,11Л:- 0; if PtrArr[I,j*2JA > 1 then Вспомним, однако, что длина внутреннего представления указателя состав- составляет 4 байта, поэтому для размещения массива PTRARR потребуется ЮОх х200х4 = 80 000 байт, что превышает размер сегмента данных F5 536 байт), доступный, как уже отмечалось, программе для статического размещения данных.
Выходом из положения могла бы послужить адресная арифметика, т. е. арифметика над указателями, потому что в этом случае можно было бы от- отказаться от создания массива указателей ptrarr и вычислять адрес любого элемента прямоугольной матрицы непосредственно перед обращением к нему.
Однако в Турбо Паскале над указателями не определены никакие операции, кроме операций присваивания и отношения. Тем не менее, решить указанную задачу все-таки можно. Как мы уже знаем, любой указатель состоит из двух слов типа WORD, в которых хранятся сегмент и смещение. В Турбо Паскале определены две встроенные функции типа WORD, позволяющие получить содержимое этих слов:? SEG(X) — возвращает сегментную часть адреса;? OFS (X) — возвращает смещение. Аргументом х при обращении к этим функциям может служить любая пере- переменная, в том числе и та, на которую указывает указатель Например, если имеем р: begin new(p); pn:= 3.14; end. то функция seg(P) вернет сегментную часть адреса, по которому располага- располагается 4-баЙтный указатель р, в то время как seg(P") — сегмент 6-байтного участка кучи, в котором хранится число 3,14.
Таким образом, возможна такая последовательность действий. Вначале процедурой getmem из кучи забираются несколько фрагментов подходящей дли- длины (напомню, что за одно обращение к процедуре можно зарезервировать не более 65 521 байт динамической памяти). Для рассматриваемого примера удобно резервировать фрагменты такой длины, чтобы в них могли, напри- например, разместиться строки прямоугольной матрицы, т. е. 200x10 = 2000 байт. Начало каждого фрагмента, т. е. фактически начало размещения в памяти каждой строки, запоминается в массиве PTRSTR, состоящем из 100 указателей. Теперь для доступа к любому элементу строки нужно вычислить смещение этого элемента от начала строки и сформировать соответствующий указатель: var Integer; array A,.100J of pointer; PtrStr pr const SizeOfReal begin for l:= 1 to 100 do GetMem(PtrStr[i]rSizeOfReal*200); 6; /Обращение к элементу матрицы [i,j]} pr:= ptr(seg(PtrStr[i]"), ofs(PtrStr[i.]") + [j-l) *SizeOtReal); if pr" > 1 then end.
Поскольку оператор вычисления адреса PR: = PTR... будет, судя по всему, использоваться в программе неоднократно, полезно ввести вспомогательную функцию GETR, возвращающую значение элемента матрицы, и процедуру PUTR, устанавливающую новое значение элемента (правила объявления про- процедур и функций изложены в главе 8).
Каждая из них, в свою очередь, обращается к функции ADDRR для вычисления адреса. В примере 6.1 приводится программа, создающая в памяти матрицу из NxM случайных чисел и вычисляющая их среднее значение. const SizeOfReal = 6; N = 100; М = 200; var l, ]: Integer; PtrStr: array [1..N] of pointer; s: Reel; (Длина переменной типа REAL} {Количество столбцов} {Количество строк} /64 type RealPomt = ~Rcal; {— --) Function AddrR (i,j: word}: RealPoint; {По сегменту i и смещению j выдает адрес вещественной перемерной} begin AddrR:= ptr (seg (PtrStr [1] л), ofs (PtrStr [i]'v) + (j-l) \SizeOfReal) end {AddrR I; { 1 Function GetRA,j: Integer): Real; {Выдает ¦значение вещественной переменной по сегменту i и смещению j ее адреса} begin GetR:= AddrR (i.,])A end I GetR); {- ¦-- I Procepure PiitR(i,j - Integer; x- Rpal); {Помещает в переменную, адрес которой имеет сегмент i и смещение j, вещественное значение у] begin AddrR (x, j) " -.= х end {PutR); {- } begin (Main! for i:=] to N do begin GetMem(PtrStr[i],M^SizeOfRea!); for j •= 1 to M do PutR(i, j. Random) end; s:= 0; fcr l:= 1 to N do for j:= 1 to M do s:= s + GetR(i, j); WriteLn(S / (N * M): 12:10) end {Mam}.
В рассмотренном примере предполагается, что каждая строка размещается в куче, начиная с границы параграфа, и смещение для каждого указателя PTRSTR равно нулю. В действительности при последовательных обращениях к процедуре GF.TMEM начало очередного фрагмента следует сразу за концом предыдущего и может не попасть на границу сегмента. В результате, при размещении фрагментов максимальной длины F5 521 байт) может возникнуть переполнение при вычислении смещения последнего байта.