Рассмотрим некоторые приложения кластерного анализа.
Деление стран на группы по уровню развития.
Изучались 65 стран по 31 показателю (национальный доход на душу населения, доля населения занятого в промышленности в %, накопления на душу населения, доля населения, занятого в сельском хозяйстве в %, средняя продолжительность жизни, число автомашин на 1 тыс. жителей, численность вооруженных сил на 1 млн. жителей, доля ВВП промышленности в %, доля ВВП сельского хозяйства в %, и т.д.)
Каждая из стран выступает в данном рассмотрении как объект, характеризуемый определенными значениями 31 показателя. Соответственно они могут быть представлены в качестве точек в 31-мерном пространстве. Такое пространство обычно называется пространством свойств изучаемых объектов. Сравнение расстояния между этими точками будет отражать степень близости рассматриваемых стран, их сходство друг с другом. Социально-экономический смысл подобного понимания сходства означает, что страны считаются тем более похожими, чем меньше различия между одноименными показателями, с помощью которых они описываются.
Первый шаг подобного анализа заключается в выявлении пары народных хозяйств, учтенных в матрице сходства, расстояние между которыми является наименьшим. Это, очевидно, будут наиболее сходные, похожие экономики. В последующем рассмотрении обе эти страны считаются единой группой, единым кластером. Соответственно исходная матрица преобразуется так, что ее элементами становятся расстояния между всеми возможными парами уже не 65, а 64 объектами – 63 экономики и вновь преобразованного кластера – условного объединения двух наиболее похожих стран. Из исходной матрицы сходства выбрасываются строки и столбцы, соответствующие расстояниям от пары стран, вошедших в объедение, до всех остальных, но зато добавляются строка и столбец, содержащие расстояние между кластером, полученным при объединении и прочими странами.
Расстояние между вновь полученным кластером и странами полагается равным среднему из расстояний между последними и двумя странами, которые составляют новый кластер. Иными словами, объединенная группа стран рассматривается как целое с характеристиками, примерно равными средним из характеристик входящих в него стран.
Второй шаг анализа заключается в рассмотрении преобразованной таким путем матрицы с 64 строками и столбцами. Снова выявляется пара экономик, расстояние между которыми имеет наименьшее значение, и они, так же как в первом случае, сводятся воедино. При этом наименьшее расстояние может оказаться как между парой стран, так и между какой-либо страной и объединением стран, полученным на предыдущем этапе.
Дальнейшие процедуры аналогичны описанным выше: на каждом этапе матрица преобразуется так, что из нее исключаются два столбца и две строки, содержащие расстояние до объектов (пар стран или объединений – кластеров), сведенных воедино на предыдущей стадии; исключенные строки и столбцы заменяются столбцом и строкой, содержащими расстояния от новых объединений до остальных объектов; далее в измененной матрице выявляется пара наиболее близких объектов. Анализ продолжается до полного исчерпания матрицы (т. е. до тех пор, пока все страны не окажутся сведенными в одно целое). Обобщенные результаты анализа матрицы можно представить в виде дерева сходства (дендограммы), подобного описанному выше, с той лишь разницей, что дерево сходства, отражающее относительную близость всех рассматриваемых нами 65 стран, много сложнее схемы, в которой фигурирует только пять народных хозяйств. Это дерево в соответствии с числом сопоставляемых объектов включает 65 уровней. Первый (нижний) уровень содержит точки, соответствующие каждых стране в отдельности. Соединение двух этих точек на втором уровне показывает пару стран, наиболее близких по общему типу народных хозяйств. На третьем уровне отмечается следующее по сходству парное соотношение стран (как уже упоминалось, в таком соотношении может находиться либо новая пара стран, либо новая страна и уже выявленная пара сходных стран). И так далее до последнего уровня, на котором все изучаемые страны выступают как единая совокупность.
В результате применения кластерного анализа были получены следующие пять групп стран:
афро-азиатская группа;
латино-азиатская группа;
латино-среднеземнаморская группа;
группа развитых капиталистических стран (без США)
США
Введение новых индикаторов сверх используемого здесь 31 показателя или замена их другими, естественно, приводят к изменению результатов классификации стран.
2. Деление стран по критерию близости культуры.
Как известно маркетинг должен учитывать культуру стран (обычаи, традиции, и т.д.).
Посредством кластеризации были получены следующие группы стран:
арабские;
ближневосточные;
скандинавские;
германоязычные;
англоязычные;
романские европейские;
латиноамериканские;
дальневосточные.
3. Разработка прогноза конъюнктуры рынка цинка.
Кластерный анализ играет важную роль на этапе редукции экономико-математической модели товарной конъюнктуры, способствуя облегчению и упрощению вычислительных процедур, обеспечению большей компактности получаемых результатов при одновременном сохранении необходимой точности. Применение кластерного анализа дает возможность разбить всю исходную совокупность показателей конъюнктуры на группы (кластеры) по соответствующим критериям, облегчая тем самым выбор наиболее репрезентативных показателей.
Кластерный анализ широко используется для моделирования рыночной конъюнктуры. Практически основное большинство задач прогнозирования опирается на использование кластерного анализа.
Например, задача разработки прогноза конъюнктуры рынка цинка.
Первоначально было отобрано 30 основных показателей мирового рынка цинка:
Х1 - время
Показатели производства:
Х2 - в мире
Х3 - США
Х4 - Европе
Х5 - Канаде
Х6 - Японии
Х7 - Австралии
Показатели потребления:
Х8 - в мире
Х9 - США
Х10 - Европе
Х11 - Канаде
Х12 - Японии
Х13 - Австралии
Запасы цинка у производителей:
Х14 - в мире
Х15 - США
Х16 - Европе
Х17 - других странах
Запасы цинка у потребителей:
Х18 - в США
Х19 - в Англии
Х10 - в Японии
Импорт цинковых руд и концентратов (тыс. тонн)
Х21 - в США
Х22 - в Японии
Х23 - в ФРГ
Экспорт цинковых руд и концентратов (тыс. тонн)
Х24 - из Канады
Х25 - из Австралии
Импорт цинка (тыс. тонн)
Х26 - в США
Х27 - в Англию
Х28 - в ФРГ
Экспорт цинка (тыс. Тонн)
Х29 - из Канады
Х30 - из Австралии
Для определения конкретных зависимостей был использован аппарат корреляционно-регрессионного анализа. Анализ связей производился на основе матрицы парных коэффициентов корреляции. Здесь принималась гипотеза о нормальном распределении анализируемых показателей конъюнктуры. Ясно, что rij являются не единственно возможным показателем связи используемых показателей. Необходимость использования кластерного анализа связано в этой задаче с тем, что число показателей влияющих на цену цинка очень велико. Возникает необходимость их сократить по целому ряду следующих причин:
а) отсутствие полных статистических данных по всем переменным;
б) резкое усложнение вычислительных процедур при введении в модель большого числа переменных;
в) оптимальное использование методов регрессионного анализа требует превышения числа наблюдаемых значений над числом переменных не менее, чем в 6-8 раз;
г) стремление к использованию в модели статистически независимых переменных и пр.
Проводить такой анализ непосредственно на сравнительно громоздкой матрице коэффициентов корреляции весьма затруднительно. С помощью кластерного анализа всю совокупность конъюнктурных переменных можно разбить на группы таким образом, чтобы элементы каждого кластера сильно коррелировали между собой, а представители разных групп характеризовались слабой коррелированностью.
Для решения этой задачи был применен один из агломеративных иерархических алгоритмов кластерного анализа. На каждом шаге число кластеров уменьшается на один за счет оптимального, в определенном смысле, объединения двух групп. Критерием объединения является изменение соответствующей функции. В качестве функции такой были использованы значения сумм квадратов отклонений вычисляемые по следующим формулам:

(j = 1, 2, …, m),
где j - номер кластера, n - число элементов в кластере.
rij - коэффициент парной корреляции.
Таким образом, процессу группировки должно соответствовать последовательное минимальное возрастание значения критерия E.
На первом этапе первоначальный массив данных представляется в виде множества, состоящего из кластеров, включающих в себя по одному элементу. Процесс группировки начинается с объединения такой пары кластеров, которое приводит к минимальному возрастанию суммы квадратов отклонений. Это требует оценки значений суммы квадратов отклонений для каждого из возможных  объединений кластеров. На следующем этапе рассматриваются значения сумм квадратов отклонений уже для
объединений кластеров. На следующем этапе рассматриваются значения сумм квадратов отклонений уже для 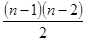 кластеров и т.д. Этот процесс будет остановлен на некотором шаге. Для этого нужно следить за величиной суммы квадратов отклонений. Рассматривая последовательность возрастающих величин, можно уловить скачок (один или несколько) в ее динамике, который можно интерпретировать как характеристику числа групп «объективно» существующих в исследуемой совокупности. В приведенном примере скачки имели место при числе кластеров равном 7 и 5. Далее снижать число групп не следует, т.к. это приводит к снижению качества модели. После получения кластеров происходит выбор переменных наиболее важных в экономическом смысле и наиболее тесно связанных с выбранным критерием конъюнктуры - в данном случае с котировками Лондонской биржи металлов на цинк. Этот подход позволяет сохранить значительную часть информации, содержащейся в первоначальном наборе исходных показателей конъюнктуры.
кластеров и т.д. Этот процесс будет остановлен на некотором шаге. Для этого нужно следить за величиной суммы квадратов отклонений. Рассматривая последовательность возрастающих величин, можно уловить скачок (один или несколько) в ее динамике, который можно интерпретировать как характеристику числа групп «объективно» существующих в исследуемой совокупности. В приведенном примере скачки имели место при числе кластеров равном 7 и 5. Далее снижать число групп не следует, т.к. это приводит к снижению качества модели. После получения кластеров происходит выбор переменных наиболее важных в экономическом смысле и наиболее тесно связанных с выбранным критерием конъюнктуры - в данном случае с котировками Лондонской биржи металлов на цинк. Этот подход позволяет сохранить значительную часть информации, содержащейся в первоначальном наборе исходных показателей конъюнктуры.