Рассмотрим Ι = (Ι1, Ι2, … Ιn) как множество кластеров {Ι1}, {Ι2},…{Ιn}. Выберем два из них, например, Ι i и Ι j, которые в некотором смысле более близки друг к другу и объединим их в один кластер. Новое множество кластеров, состоящее уже из n-1 кластеров, будет:
{Ι1}, {Ι2}…, {Ι i, Ι j}, …, {Ιn}.
Повторяя процесс, получим последовательные множества кластеров, состоящие из (n-2), (n-3), (n–4) и т.д. кластеров. В конце процедуры можно получить кластер, состоящий из n объектов и совпадающий с первоначальным множеством Ι = (Ι1, Ι2, … Ιn).
В качестве меры расстояния возьмем квадрат евклидовой метрики di j2. и вычислим матрицу D = {di j2}, где di j2 - квадрат расстояния между
Ι i и Ι j:
| Ι1 | Ι2 | Ι3 | …. | Ιn | |
| Ι1 | d122 | d132 | …. | d1n2 | |
| Ι2 | d232 | …. | d2n2 | ||
| Ι3 | …. | d3n2 | |||
| …. | …. | …. | |||
| Ιn |
Пусть расстояние между Ι i и Ι j будет минимальным:
di j2 = min {di j2, i ¹ j}. Образуем с помощью Ι i и Ι j новый кластер
{Ι i, Ι j}. Построим новую ((n-1), (n-1)) матрицу расстояния
| {Ι i, Ι j} | Ι1 | Ι2 | Ι3 | …. | Ιn | |
| {Ι i; Ι j} | di j21 | di j22 | di j23 | …. | di j2n | |
| Ι1 | d122 | d13 | …. | d12n | ||
| Ι2 | di j21 | …. | d2n | |||
| Ι3 | …. | d3n | ||||
| Ιn |
(n-2) строки для последней матрицы взяты из предыдущей, а первая строка вычислена заново. Вычисления могут быть сведены к минимуму, если удастся выразить di j2k,k = 1, 2,…, n; (k ¹ i ¹ j) через элементы первоначальной матрицы.
Исходно определено расстояние лишь между одноэлементными кластерами, но надо определять расстояния и между кластерами, содержащими более чем один элемент. Это можно сделать различными способами, и в зависимости от выбранного способа мы получают алгоритмы кластер анализа с различными свойствами. Можно, например, положить расстояние между кластером i + j и некоторым другим кластером k, равным среднему арифметическому из расстояний между кластерами i и k и кластерами j и k:
di+j,k = ½ (di k + dj k).
Но можно также определить di+j,k как минимальное из этих двух расстояний:
di+j,k = min (di k + dj k).
Таким образом, описан первый шаг работы агломеративного иерархического алгоритма. Последующие шаги аналогичны.
Довольно широкий класс алгоритмов может быть получен, если для перерасчета расстояний использовать следующую общую формулу:
di+j,k = A(w) min(dik djk) + B(w) max(dik djk), где
A(w) =  , если dik £ djk
, если dik £ djk
A(w) =  , если dik > djk
, если dik > djk
B(w) =  , если dik £ djk
, если dik £ djk
B(w) =  , если dik > djk
, если dik > djk
где ni и nj - число элементов в кластерах i и j, а w – свободный параметр, выбор которого определяет конкретный алгоритм. Например, при w = 1 мы получаем, так называемый, алгоритм «средней связи», для которого формула перерасчета расстояний принимает вид:
di+j,k = 
В данном случае расстояние между двумя кластерами на каждом шаге работы алгоритма оказывается равным среднему арифметическому из расстояний между всеми такими парами элементов, что один элемент пары принадлежит к одному кластеру, другой - к другому.
Наглядный смысл параметра w становится понятным, если положить w ® ¥. Формула пересчета расстояний принимает вид:
di+j,k = min (di,k djk)
Это будет так называемый алгоритм «ближайшего соседа», позволяющий выделять кластеры сколь угодно сложной формы при условии, что различные части таких кластеров соединены цепочками близких друг к другу элементов. В данном случае расстояние между двумя кластерами на каждом шаге работы алгоритма оказывается равным расстоянию между двумя самыми близкими элементами, принадлежащими к этим двум кластерам.
Довольно часто предполагают, что первоначальные расстояния (различия) между группируемыми элементами заданы. В некоторых задачах это действительно так. Однако, задаются только объекты и их характеристики и матрицу расстояний строят исходя из этих данных. В зависимости от того, вычисляются ли расстояния между объектами или между характеристиками объектов, используются разные способы.
В случае кластер анализа объектов наиболее часто мерой различия служит либо квадрат евклидова расстояния

(где xih, xjh - значения h-го признака для i-го и j-го объектов, а m - число характеристик), либо само евклидово расстояние. Если признакам приписывается разный вес, то эти веса можно учесть при вычислении расстояния
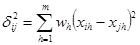
Иногда в качестве меры различия используется расстояние, вычисляемое по формуле:

которые называют: "хэмминговым", "манхэттенским" или "сити-блок" расстоянием.
Естественной мерой сходства характеристик объектов во многих задачах является коэффициент корреляции между ними

где mi,mj,di,dj - соответственно средние и среднеквадратичные отклонения для характеристик i и j. Мерой различия между характеристиками может служить величина 1 - r. В некоторых задачах знак коэффициента корреляции несуществен и зависит лишь от выбора единицы измерения. В этом случае в качестве меры различия между характеристиками используется ô1 - ri j ô
Число кластеров.
Очень важным вопросом является проблема выбора необходимого числа кластеров. Иногда можно m число кластеров выбирать априорно. Однако в общем случае это число определяется в процессе разбиения множества на кластеры.
Проводились исследования Фортьером и Соломоном, и было установлено, что число кластеров должно быть принято для достижения вероятности a того, что найдено наилучшее разбиение. Таким образом, оптимальное число разбиений является функцией заданной доли b наилучших или в некотором смысле допустимых разбиений во множестве всех возможных. Общее рассеяние будет тем больше, чем выше доля b допустимых разбиений. Фортьер и Соломон разработали таблицу, по которой можно найти число необходимых разбиений. S(a, b) в зависимости от a и b (где a - вероятность того, что найдено наилучшее разбиение, b - доля наилучших разбиений в общем числе разбиений) Причем в качестве меры разнородности используется не мера рассеяния, а мера принадлежности, введенная Хользенгером и Харманом. Таблица значений S(a, b) приводится ниже.
Таблица значений S(a, b)
| b \ a | 0.20 | 0.10 | 0.05 | 0.01 | 0.001 | 0.0001 |
| 0.20 | ||||||
| 0.10 | ||||||
| 0.05 | ||||||
| 0.01 | ||||||
| 0.001 | ||||||
| 0.0001 |
Довольно часто критерием объединения (числа кластеров) становится изменение соответствующей функции. Например, суммы квадратов отклонений: 
Процессу группировки должно соответствовать здесь последовательное минимальное возрастание значения критерия E. Наличие резкого скачка в значении E можно интерпретировать как характеристику числа кластеров, объективно существующих в исследуемой совокупности.
Итак, второй способ определения наилучшего числа кластеров сводится к выявлению скачков, определяемых фазовым переходом от сильно связанного к слабосвязанному состоянию объектов.
Дендограммы.
Наиболее известный метод представления матрицы расстояний или сходства основан на идее дендограммы или диаграммы дерева. Дендограмму можно определить как графическое изображение результатов процесса последовательной кластеризации, которая осуществляется в терминах матрицы расстояний. С помощью дендограммы можно графически или геометрически изобразить процедуру кластеризации при условии, что эта процедура оперирует только с элементами матрицы расстояний или сходства.
Существует много способов построения дендограмм. В дендограмме объекты располагаются вертикально слева, результаты кластеризации – справа. Значения расстояний или сходства, отвечающие строению новых кластеров, изображаются по горизонтальной прямой поверх дендограмм.

Рис1
На рисунке 1 показан один из примеров дендограммы. Рис 1 соответствует случаю шести объектов (n=6) и k характеристик (признаков). Объекты А и С наиболее близки и поэтому объединяются в один кластер на уровне близости, равном 0,9. Объекты D и Е объединяются при уровне 0,8. Теперь имеем 4 кластера:
(А, С), (F), (D, E), (B).
Далее образуются кластеры (А, С, F) и (E, D, B), соответствующие уровню близости, равному 0,7 и 0,6. Окончательно все объекты группируются в один кластер при уровне 0,5.
Вид дендограммы зависит от выбора меры сходства или расстояния между объектом и кластером и метода кластеризации. Наиболее важным моментом является выбор меры сходства или меры расстояния между объектом и кластером.
Число алгоритмов кластерного анализа слишком велико. Все их можно подразделить на иерархические и неиерархические.
Иерархические алгоритмы связаны с построением дендограмм и делятся на:
а) агломеративные, характеризуемые последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров;
б) дивизимные (делимые), в которых число кластеров возрастает, начиная с одного, в результате чего образуется последовательность расщепляющих групп.
Алгоритмы кластерного анализа имеют сегодня хорошую программную реализацию, которая позволяет решить задачи самой большой размерности.
Данные
Кластерный анализ можно применять к интервальным данным, частотам, бинарными данным. Важно, чтобы переменные изменялись в сравнимых шкалах.
Неоднородность единиц измерения и вытекающая отсюда невозможность обоснованного выражения значений различных показателей в одном масштабе приводит к тому, что величина расстояний между точками, отражающими положение объектов в пространстве их свойств, оказывается зависящей от произвольно избираемого масштаба. Чтобы устранить неоднородность измерения исходных данных, все их значения предварительно нормируются, т.е. выражаются через отношение этих значений к некоторой величине, отражающей определенные свойства данного показателя. Нормирование исходных данных для кластерного анализа иногда проводится посредством деления исходных величин на среднеквадратичное отклонение соответствующих показателей. Другой способ сводиться к вычислению, так называемого, стандартизованного вклада. Его еще называют Z-вкладом.
Z-вклад показывает, сколько стандартных отклонений отделяет данное наблюдение от среднего значения:
 , где xi – значение данного наблюдения, – среднее, S – стандартное отклонение.
, где xi – значение данного наблюдения, – среднее, S – стандартное отклонение.
Среднее для Z-вкладов является нулевым и стандартное отклонение равно 1.
Стандартизация позволяет сравнивать наблюдения из различных распределений. Если распределение переменной является нормальным (или близким к нормальному), и средняя и дисперсия известны или оцениваются по большим выборным, то Z-вклад для наблюдения обеспечивает более специфическую информацию о его расположении.
Заметим, что методы нормирования означают признание всех признаков равноценными с точки зрения выяснения сходства рассматриваемых объектов. Уже отмечалось, что применительно к экономике признание равноценности различных показателей кажется оправданным отнюдь не всегда. Было бы, желательным наряду с нормированием придать каждому из показателей вес, отражающий его значимость в ходе установления сходств и различий объектов.
В этой ситуации приходится прибегать к способу определения весов отдельных показателей – опросу экспертов. Например, при решении задачи о классификации стран по уровню экономического развития использовались результаты опроса 40 ведущих московских специалистов по проблемам развитых стран по десятибалльной шкале:
обобщенные показатели социально-экономического развития – 9 баллов;
показатели отраслевого распределения занятого населения – 7 баллов;
показатели распространенности наемного труда – 6 баллов;
показатели, характеризующие человеческий элемент производительных сил – 6 баллов;
показатели развития материальных производительных сил – 8 баллов;
показатель государственных расходов – 4балла;
«военно-экономические» показатели – 3 балла;
социально-демографические показатели – 4 балла.
Оценки экспертов отличались сравнительно высокой устойчивостью.
Экспертные оценки дают известное основание для определения важности индикаторов, входящих в ту или иную группу показателей. Умножение нормированных значений показателей на коэффициент, соответствующий среднему баллу оценки, позволяет рассчитывать расстояния между точками, отражающими положение стран в многомерном пространстве, с учетом неодинакового веса их признаков.
Довольно часто при решении подобных задач используют не один, а два расчета: первый, в котором все признаки считаются равнозначными, второй, где им придаются различные веса в соответствии со средними значениями экспертных оценок.