Кластерный анализ. Основные понятия
Кластерный анализ включает в себя набор различных алгоритмов классификации для организации наблюдаемых данных в наглядные структуры. Задачу классификации можно сформулировать следующим образом.
Имеется некоторое конечное множество объектов произвольной природы, представленных совокупностью соответствующих векторов. Необходимо классифицировать эти объекты, т.е. разбить их множество на заданное или произвольное количество групп (кластеров, классов, таксонов) таким образом, чтобы в каждую группу оказались включенными объекты, близкие между собой в том или ином смысле. Априорная информация о классификации объектов при этом отсутствует. Таким образом, необходимо разбить множество векторов  на
на  попарно не пересекающихся классов
попарно не пересекающихся классов  так, чтобы
так, чтобы  , причем
, причем 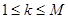 , где
, где  - число векторов.
- число векторов.
Для оценки расстояния между двумя векторами  могут быть использованы следующие меры:
могут быть использованы следующие меры:
1) евклидово расстояние 
 ;
;
2) квадрат евклидова расстояния  ;
;
3) расстояние городских кварталов (манхэттенское расстояние)  ;
;
4) расстояние Чебышева  ;
;
5) степенное расстояние  , где
, где  - параметры, задаваемые пользователем;
- параметры, задаваемые пользователем;
6) процент несогласия 
 .
.
Кластеризация (k-means и g-means)
Кластеризация семействами алгоритмов k-means и g-means используется для решения задач описательной бизнес-аналитики, в частности, для кластеризации (автоматической сегментации) объектов.
В основе работы алгоритма k-means лежит принцип оптимального в определенном смысле разбиения множества данных на k кластеров. Алгоритм пытается сгруппировать данные в кластеры таким образом, чтобы целевая функция алгоритма разбиения достигала экстремума.
Выбор числа k может базироваться на теоретических соображениях или интуиции.
Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера.
Центр кластера - это средние значения переменных объектов, входящих в кластер.
Радиус кластера - максимальное расстояние точек от центра кластера.
Кластеры могут быть перекрывающимися. Такая ситуация возникает, когда обнаруживается перекрытие кластеров. В этом случае невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров. Такие объекты называют спорными.
Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам.
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным.
Неоднозначность данной задачи может быть устранена экспертом или аналитиком.
Алгоритм k-means состоит из двух этапов.
1Первоначальное распределение объектов по кластерам.
Задается число k, и на первом шаге эти точки считаются «центрами» кластеров. Каждому кластеру соответствует один центр. Выбор начальных центров осуществляется случайным образом. В результате каждый объект назначен определенному кластеру.
2Итерационный процесс.
Вычисляются новые центры кластеров и объекты перераспределяются.
Процесс вычисления центров и перераспределения объектов продолжается до тех пор, пока не стабилизируются центры кластеров, т.е. все объекты будут принадлежать кластеру, которому они принадлежали до текущей итерации.
Иллюстрация работы алгоритма k-means приведена на рисунке 1.

Рис.1
Если число кластеров назначить затруднительно, то можно использовать алгоритм g-means. Он определяет число кластеров в модели на основании последовательного выполнения статистического теста на то, что данные внутри каждого кластера подчиняются определенному гауссовскому (Gaussian, отсюда и название алгоритма) закону распределения. Если тест дает отрицательный результат, кластер разбивается на два новых кластера (алгоритмом k-means) с центрами, расположенными на оси главных компонент.
Подготовка обучающей выборки
Для проведения кластеризации готовится обучающая выборка. Ее особенность заключается в том, что выходные поля в такой выборке могут отсутствовать совсем. Даже если в обучающей выборке будут присутствовать выходные поля, они не будут участвовать при кластеризации, однако будут рассчитаны в выходном наборе данных. Как правило, это будет среднее или часто встречаемое значение по кластеру.
Важно помнить, что алгоритмы k-means и g-means ориентированы на гипотезу о компактности, которая предполагает, что данные обучающей выборки в виде многомерных векторов образуют в пространстве компактные сгустки сферической формы. В противном случае (например, вложенные друг в друга шары) кластеры, найденные этими алгоритмами, будут малоинформативными. В этих случаях лучше использовать неметрические алгоритмы, например, на основе смеси распределений (см. узел EM кластеризация).
При подготовке обучающей выборки для кластеризации следует иметь в виду следующее:
- если задач аналитика – сжато описать имеющиеся данные при помощи кластеров, то особого смысла выделять тестовую выборку нет;
- как правило, метрические алгоритмы кластеризации плохо работают с категориальными признаками, измеренными в шкале наименований. Для таких данных лучше использовать специальные алгоритмы, например, CLOPE (см. узел Кластеризация транзакций).
Работа кластерного анализа опирается на предположение о том, что рассматриваемые признаки объекта в принципе допускают желательное разбиение пула (совокупности) объектов на кластеры (сравнимость шкал, в которых измеряются признаки, правильно выбран масштаб измерения/единицы измерения признаков).