После того, как указаны входные и, при необходимости, выходные поля, следует нормализация данных в обучающей выборке. Целью нормализации значений полей является преобразование данных к виду, наиболее подходящему для обработки алгоритмом. Нормализация (стандартизация) приводит значения всех преобразованных переменных к единому диапазону значений путем выражения через отношение этих значений к некой величине, отражающей определенные свойства конкретного признака. Для узлов, решающих задачи описательной или предсказательной аналитики, данные, поступающие на вход, должны иметь числовой тип, а их значения должны быть распределены в определенном диапазоне.
Нормализатор может преобразовать дискретные данные к набору уникальных индексов или значения, лежащие в произвольном диапазоне к диапазону [0..1]. Для узла «Кластеризация» доступны следующие виды нормализации полей.
1 Линейная нормализация. Используется только для непрерывных числовых полей.
Позволяет привести числа к диапазону [min..max], то есть минимальному числу из исходного диапазона будет соответствовать min, а максимальному – max. Остальные значения распределяются между min и max. В алгоритмах кластеризации приведение к диапазону не используется, поэтому все настройки неактивны.
2 Уникальные значения. Используется для дискретных значений. Такими являются строки, числа или даты, заданные дискретно. Чтобы привести непрерывные числа в дискретные, можно, например, воспользоваться обработкой «Квантование». Так следует поступать для величин, для которых можно задать отношение порядка, то есть, если для двух любых дискретных значений можно указать, какое больше, а какое меньше. Тогда все значения необходимо расположить в порядке возрастания. Далее они нумеруются по порядку, и значения заменяются их порядковым номером.
3 Битовая маска. Используется для дискретных значений. Этот вид нормализации следует использовать для величин, которые можно только сравнивать на равенство или неравенство, но нельзя сказать, какое больше, а какое меньше. Все значения заменяются порядковыми номерами, а номер рассматривается в двоичном виде или в виде маски из нулей и единиц. Тогда каждая позиция маски рассматривается как отдельное поле, содержащее ноль или единицу. К такому полю можно применить линейную нормализацию, то есть заменить ноль некоторым минимальным значением, а единицу – максимальным.
После такой нормализации на вход узла будет подаваться не одно это поле, а столько полей, сколько разрядов в маске.
Пример нормализации полей
1. Линейная нормализация. Приведем значения к диапазону [0..1].
| Поле до нормализации | Поле после нормализации |
| -5 | |
| 2,3 | 0,81111 |
| 1,1 | 0,67778 |
| 3,5 | 0,94444 |
Графически такое преобразование можно представить так.

Рис.2
2. Уникальные значения.
| Поле до нормализации | Поле после нормализации |
| Маленький | |
| Средний | |
| Большой | |
| Огромный |
3. Битовая маска (по схеме «Комбинация битов»). Заменим значения битовой маской и приведем к диапазону [-1..1].
| Поле до нормализации | Маска | Поля после нормализации | |
| Москва | -1 | -1 | |
| Воронеж | -1 | ||
| Рязань | -1 | ||
| Тула |
Кроме того, существует настройка нормализации полей по умолчанию, т.е. этап нормализации можно пропустить. В этом случае нормализация будет произведена автоматически в зависимости от вида данных полей:
1 Дискретный – нормализация битовой маской со способом кодирования – комбинация битов.
2 Непрерывный – линейная нормализация, для алгоритмов кластеризации без приведения в какой –либо диапазон.
В качестве функции расстояния k-means в Deductor использует:
- для непрерывных числовых полей, а также упорядоченных категориальных признаков – евклидово расстояние;
- для неупорядоченных категориальных признаков – функцию отличия.
Дополнительно
Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году, включает в себя более 100 различных алгоритмов.
В отличие от задач классификации, кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных (по интервальным данным, частотам, бинарным данным). При этом необходимо помнить, что переменные должны измеряться в сравнимых шкалах.
Кластерный анализ позволяет сокращать размерность данных, делать ее наглядной.
Кластерный анализ может применяться к совокупностям временных рядов, здесь могут выделяться периоды схожести некоторых показателей и определяться группы временных рядов со схожей динамикой.
Кластерный анализ параллельно развивался в нескольких направлениях, таких как биология, психология, др., поэтому у большинства методов существует по два и более названий. Это существенно затрудняет работу при использовании кластерного анализа.
Задачи кластерного анализа можно объединить в следующие группы:
1. Разработка типологии или классификации.
2. Исследование полезных концептуальных схем группирования объектов.
3. Представление гипотез на основе исследования данных.
4. Проверка гипотез или исследований для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Как правило, при практическом использовании кластерного анализа одновременно решается несколько из указанных задач.
Рассмотрим пример процедуры кластерного анализа.
Допустим, мы имеем набор данных А, состоящий из 14-ти примеров, у которых имеется по два признака X и Y. Данные по ним приведены в таблице 1
| Таблица 1. Набор данных А | ||
| № примера | признак X | признак Y |
Данные в табличной форме не носят информативный характер. Представим переменные X и Y в виде диаграммы рассеивания, изображенной на рисунке 3.
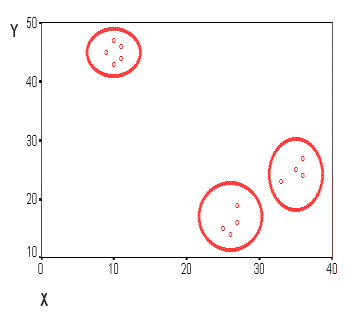
Рис. 3. Диаграмма рассеивания переменных X и Y
На рисунке мы видим несколько групп "похожих" примеров. Примеры (объекты), которые по значениям X и Y "похожи" друг на друга, принадлежат к одной группе (кластеру); объекты из разных кластеров не похожи друг на друга.
Критерием для определения схожести и различия кластеров является расстояние между точками на диаграмме рассеивания. Это сходство можно "измерить", оно равно расстоянию между точками на графике. Способов определения меры расстояния между кластерами, называемой еще мерой близости, существует несколько. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда известны их координаты X и Y:
 , (1)
, (1)
Примечание: чтобы узнать расстояние между двумя точками, надо взять разницу их координат по каждой оси, возвести ее в квадрат, сложить полученные значения для всех осей и извлечь квадратный корень из суммы.
Когда осей больше, чем две, расстояние рассчитывается таким образом: сумма квадратов разницы координат состоит из стольких слагаемых, сколько осей (измерений) присутствует в нашем пространстве. Например, если нам нужно найти расстояние между двумя точками в пространстве трех измерений формула (1) приобретает вид:
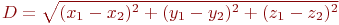 , (2)
, (2)

Рис. 4. Расстояние между двумя точками в пространстве трех измерений