Если не усложнять и всё такое, а анализ следует сделать уже, грубо говоря, завтра, то вкратце опишу, что да как в этой непонятной пучине регрессионного анализа. Заранее предупреждаю, что анализ в Excel'e мягко говоря, поверхностный – Excelпользуется лишь методом наименьших квадратов (МНК), который не всегда уместен, однако является одним из наиболее простых. Более подходящим он является для данных, представленных в виде пространственной выборки (данные по ряду домохозяйств, предприятий, регионов, стран). Для временных рядов (данные о показателях, представленные за определённый период) чаще подходят другие методы оценки, которые являются более сложными.
Итак, регрессионный анализ – это метод, с помощью которого можно исследовать влияние определённых переменных (их называют регрессорами, предикторами, независимыми переменными; их обозначаем как X) на выбранную нами зависимую переменную (её обозначают Y). Таким образом, в результате оценки у нас должно будет получиться уравнение вида y = a0 + a1x1+a2x2 … и так далее. К подробным пояснениям чуть позже.
Суть анализа примерно такая: на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Цели регрессионного анализа на редкость прекрасно представлены в Википедии. Оттуда и копирую, собственно:
1. Определение степени детерминированностивариации зависимой переменной предикторами (независимыми переменными);
2. Предсказание значения зависимой переменной с помощью независимой(-ых);
3. Определение вклада отдельных независимых переменных в вариацию зависимой.
Тут же Вики подчёркивает важность того, что регрессионный анализ не является способом определения СУЩЕСТВОВАНИЯ ВЗАИМОСВЯЗЕЙ. То, что взаимосвязь существует – это предпосылка к тому, чтобы проводить регрессионный анализ. Соответственно, проводя подобный анализ мы должны иметь предположения о том, что выбранный регрессор действительно должен оказывать то или иное влияние на зависимую переменную.
Для проведения анализа необходимо представить данные в Excel, расположив их следующим образом (рис. 1)

Рисунок 1
Для вычисления методом МНК оценок уравнения регрессии необходимо выбрать вкладку «Данные» и в правой части (подвкладка «Анализ») выбрать «Анализ данных». Нажав на неё, появится окошечко, в котором необходимо выбрать «Регрессия».
Если же такого пункта у Вас нет, тоВам предстоит целое путешествие по вкладкам программы. Нажми вкладку «Файл» в Excel(самая левая вкладка), там выберите «Параметры», а затем, во всплывшем окне «Надстройки», в «Управление» найдите «Надстройки Excel», нажмите «перейти» и поставьте галочку напротив пакетов анализа.
Теперь найдите ту самую заветную «Регрессию» там, где указано ранее (рис. 2)

Рисунок 2
Во входом интервале Yпросто выделяем весь столбец для Y. Входной интервал X – область со всеми регрессорами (иначе говоря, от С2 до Е11 в нашем случае).
Выходной интервал – по желанию. Можно на этой же странице, можно на отдельном листе, как удобнее. Для более подробного анализа (на всякий случай, короче говоря) предлагаю ещё поставить галочки около графиков остатков и нормальности. Ну а остальное опять же по желанию.

Рисунок 3
После нажатия «ОК» Excelвыдаст вот такую страшную штуку.
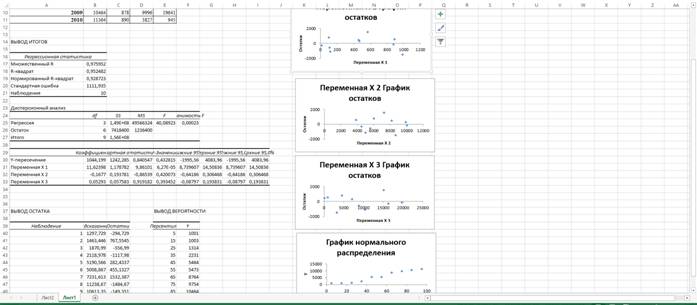
Итак, вкратце разберём, что же значит всё это. Наибольший интерес представляют вот эти штуки.
В первую очередь советую смотреть на самую последнюю таблицу и, если быть точным, на P-значение. Оно выражает вероятность принятия нулевой гипотезы, которая заключается в том, что конкретный параметр является незначимым. Соответственно, переменная СЧИТАЕТСЯ ЗНАЧИМОЙ при P< 0,05. Если Р-значение оказывается больше, то гипотеза принимается, а значит, параметр не оказывает влияния на зависимую переменную и его необходимо «выкинуть» из анализа. На нашем примере видим, что значимым и вовсе является только переменная Х1 (но это и по данным видно).

По идее, после таких результатов надо переделывать регрессию, поочерёдно выкидывая переменные (советовал бы в это случае начать с Х2, т.к. у неё показатель t-статистики ниже, а P-valueвыше). Но в данном случае, т.к. я просто объясняю пример, перестраивать не буду. Так вот исследуете все переменные и строите регрессии до тех пор, пока не получится так, что в анализе останутся только значимые регрессоры. Столбик «коэффициенты» - это и есть оценки параметров при переменных. Как я говорил ранее, регрессионное уравнение имеет следующий вид y = a0 + a1x1+a2x2 + …
В нашем случае Y = a0 + a1x1+a2x2 + a2x3. Коэффициент а – это коэффициент, показывающий насколько изменяется Y при изменении соответствующего Xна одну единицу. Допустим, по результатам нашего анализа выходит, что при увеличении X1 на одну единицу, Yрастёт на 11,624. Если бы переменная Х2 оказалась значимой, то мы бы могли сказать, что увеличение переменной Х2 на 1 единицу вело к сокращению значения зависимой переменной на 0,168 единиц по статистическим данным за период с 2001 по 2010 год.
Далее можно делать выводы на основании регрессионной статистики. Различные R-квадраты по своей сути объясняют, насколько полным является ваше уравнении регрессии. Показывает то, насколько выбранные регрессоры объясняют зависимую переменную (если говорить заумно, то коэффициент детерминации –это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости). Соответственно, чем выше этот коэффициент, тем лучше. Однако, нужно быть внимательным. Включение сильно коррелируемых с Yрегрессоров ложно увеличивают R-квадрат. Как, собственно, и включение большого числа регрессоров. Стандартная ошибка едва ли даст сильно много при анализе, однако по сути своей эта величина говорит, насколько в среднем могут отклоняться полученные оценки. Разумеется, чем ниже эта величина, тем надёжнее расчётный параметр.
Собственно, вот и весь регрессионный анализ в Excel.
Графики можно использовать опять же для себя. Чем ближе точки на графике остатков к прямой (оси абсцисс), тем лучше. Это значит, что остатки меньше – тем уравнение регрессии точнее и имеет более высокие прогнозные возможности. К сожалению или счастью, ничего более подробного и интересного особо не вытащишь из Excel'я.
Но, разумеется, я мог что-то упустить и забыть, так что, если появятся вопросы, я всегда рад помочь ^^