Содержание
Введение. 3
1. Линейная регрессия. 5
2. Полиномиальная регрессия. 6
3. Нелинейная регрессия. 8
4. Сглаживание данных. 12
5. Предсказание зависимостей. 14
Литература. 15
Введение
Аппроксимация данных с учетом их статистических параметров относится к задачам регрессии. Они обычно возникают при обработке экспериментальных данных, полученных в результате измерений процессов или физических явлений, статистических по своей природе (как, например, измерения в радиометрии и ядерной геофизике), или на высоком уровне помех (шумов). Задачей регрессионного анализа является подбор математических формул, наилучшим образом описывающих экспериментальные данные.
Математическая постановка задачи регрессии заключается в следующем. Зависимость величины (числового значения) определенного свойства случайного процесса или физического явления Y от другого переменного свойства или параметра Х, которое в общем случае также может относиться к случайной величине, зарегистрирована на множестве точек xk множеством значений yk, при этом в каждой точке зарегистрированные значения yk и xk отображают действительные значения Y(хk) со случайной погрешностью k, распределенной, как правило, по нормальному закону. По совокупности значений yk требуется подобрать такую функцию f(xk, a0, a1, …, an), которой зависимость Y(x) отображалась бы с минимальной погрешностью. Отсюда следует условие приближения:
yk = f(xk, a0, a1, …, an) + k.
Функцию f(xk, a0, a1, …, an) называют регрессией величины y на величину х. Регрессионный анализ предусматривает задание вида функции f(xk, a0, a1, …, an) и определение численных значений ее параметров a0, a1, …, an, обеспечивающих наименьшую погрешность приближения к множеству значений yk. Как правило, при регрессионном анализе погрешность приближения вычисляется методом наименьших квадратов (МНК). Для этого выполняется минимизация функции квадратов остаточных ошибок:
a, a1, …, an) =  [f(xk, a0, a1, …, an) - yk] 2.
[f(xk, a0, a1, …, an) - yk] 2.
Для определения параметров a0, a1, …, an функция остаточных ошибок дифференцируется по всем параметрам, полученные уравнения частных производных приравниваются нулю и решаются в совокупности относительно всех значений параметров. Виды регрессии обычно называются по типу аппроксимирующих функций: полиномиальная, экспоненциальная, логарифмическая и т.п.
Линейная регрессия
Общий принцип. Простейший способ аппроксимации по МНК произвольных данных sk - с помощью полинома первой степени, т.е. функции вида y(t) = a+bt. С учетом дискретности данных по точкам tk, для функции остаточных ошибок имеем:
(a,b) = [(a+b·tk) - sk] 2.
Дифференцируем функцию остаточных ошибок по аргументам a, b, приравниваем полученные уравнения нулю и формируем 2 нормальных уравнения системы:
(a+b·tk) - sk º a 1 + b tk – sk = 0,
((a+b·tk) - sk) ·tk º a tk + b tk2 – sk·tk = 0,
Решение данной системы уравнений в явной форме для К-отсчетов:
b = [K tk·sk – tk sk] / [K tk2 – ( tk) 2],
a = [ sk – b tk] /K.
Полученные значения коэффициентов используем в уравнении регрессии y(t) = a+bt. По аналогичной методике вычисляются коэффициенты и любых других видов регрессии, отличаясь только громоздкостью соответствующих выражений.
Реализация в Mathcad. Линейная регрессия в системе Mathcad выполняется по векторам аргумента Х и отсчетов Y функциями:
intercept(X,Y) – вычисляет параметр а, смещение линии регрессии по вертикали;
slope(X,Y) – вычисляет параметр b, угловой коэффициент линии регрессии.
Расположение отсчетов по аргументу Х произвольное. Функцией corr(X,Y) дополнительно можно вычислить коэффициент корреляции Пирсона. Чем он ближе к 1, тем точнее обрабатываемые данные соответствуют линейной зависимости.
Пример выполнения линейной регрессии приведен на рис.2.1.1

Рис.2.1.1
Полиномиальная регрессия
Одномерная полиномиальная регрессия с произвольной степенью n полинома и с произвольными координатами отсчетов в Mathcad выполняется функциями:
regress(X,Y,n) – вычисляет вектор S для функции interp(…), в составе которого находятся коэффициенты ki полинома n-й степени;
interp(S,X,Y,x) – возвращает значения функции аппроксимации по координатам х.
Функция interp(…) реализует вычисления по формуле:
f(x) = k0 + k1·x1 + k2·x2 + … + kn·xn ≡  ki·xi.
ki·xi.
Значения коэффициентов ki могут быть извлечены из вектора S функцией submatrix(S, 3, length(S), 0, 0).
На рис.2.2.1 приведен пример полиномиальной регрессии с использованием полиномов 2, 3 и 8-й степени. Степень полинома обычно устанавливают не более 4-6 с последовательным повышением степени, контролируя среднеквадратическое отклонение функции аппроксимации от фактических данных. Нетрудно заметить, что по мере повышения степени полинома функция аппроксимации приближается к фактическим данным, а при степени полинома, равной количеству отсчетов данных минус 1, вообще превращается в функцию интерполяции данных, что не соответствует задачам регрессии.
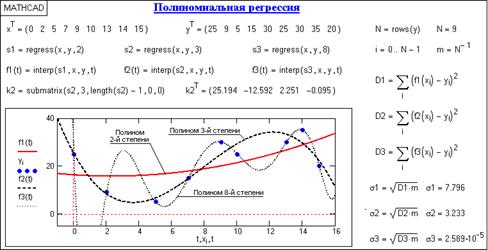
Рис.2.2.1 Одномерная полиномиальная регрессия.
Зональная регрессия. Функция regress по всей совокупности точек создает один аппроксимирующий полином. При больших координатных интервалах с большим количеством отсчетов и достаточно сложной динамике изменения данных рекомендуется применять последовательную локальную регрессию отрезками полиномов малых степеней. В Mathcad это выполняется отрезками полиномов второй степени функцией loess(X, Y, span), которая формирует специальный вектор S для функции interp(S,X,Y,x). Аргумент span > 0 в этой функции (порядка 0.1-2) определяет размер локальной области и подбирается с учетом характера данных и необходимой степени их сглаживания (чем больше span, тем больше степень сглаживания данных).
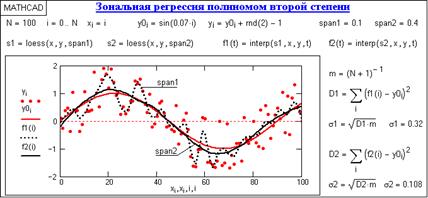
Рис.2.2.2
На рис.2.2.2 приведен пример вычисления регрессии модельной кривой (отрезка синусоиды) в сумме с шумами. Вычисления выполнены для двух значений span с определением среднеквадратического приближения к базовой кривой. При моделировании каких-либо случайных процессов и сигналов на высоком уровне шумов по минимуму среднеквадратического приближения может определяться оптимальное значение параметра span.
Нелинейная регрессия
Линейное суммирование произвольных функций. В Mathcad имеется возможность выполнения регрессии с приближением к функции общего вида в виде весовой суммы функций fn(x):
f(x, Kn) = K1·f1(x) + K2·f2(x) + … + KN·fN(x),
при этом сами функции fn(x) могут быть любого, в том числе нелинейного типа. С одной стороны, это резко повышает возможности аналитического отображения функций регрессии. Но, с другой стороны, это требует от пользователя определенных навыков аппроксимации экспериментальных данных комбинациями достаточно простых функций.
Реализуется обобщенная регрессия по векторам X, Y и f функцией linfit(X,Y,f), которая вычисляет значения коэффициентов Kn. Вектор f должен содержать символьную запись функций fn(x). Координаты xk в векторе Х могут быть любыми, но расположенными в порядке возрастания значений х (с соответствующими отсчетами значений yk в векторе Y). Пример выполнения регрессии приведен на рис.2.3.1 Числовые параметры функций f1-f3 подбирались по минимуму среднеквадратического отклонения.

Рис.2.3.1 Обобщенная регрессия.
Регрессия общего типа. Второй вид нелинейной регрессии реализуется путем подбора параметров ki к заданной функции аппроксимации с использованием функции genfit(X,Y,S,F), которая возвращает коэффициенты ki, обеспечивающие минимальную среднеквадратическую погрешность приближения функции регрессии к входным данным (векторы Х и Y координат и отсчетов). Символьное выражение функции регрессии и символьные выражения ее производных по параметрам ki записываются в вектор F. Вектор S содержит начальные значения коэффициентов ki для решения системы нелинейных уравнений итерационным методом. Пример использования метода приведен на рис.2.3.2.
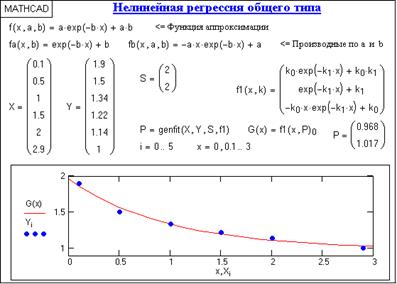
Рис.2.3.2
Типовые функции регрессии Mathcad. Для простых типовых формул аппроксимации предусмотрен ряд функций регрессии, в которых параметры функций подбираются программой Mathcad самостоятельно. К ним относятся следующие функции:
èèè 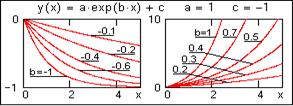
expfit(X,Y,S) – возвращает вектор, содержащий коэффициенты a, b и c экспоненциальной функции y(x) = a·exp(b·x) +c. В вектор S вводятся начальные значения коэффициентов a, b и c первого приближения. Для ориентировки по форме аппроксимационных функций и задания соответствующих начальных значений коэффициентов на рисунках слева приводится вид функций при постоянных значениях коэффициентов a и c.

èèè

lgsfit(X,Y,S) – то же, для выражения y(x) = a/(1+c·exp(b·x)).

èèè pwrfit(X,Y,S) – то же, для выражения y(x) = a·xb+c.
§§è sinfit(X,Y,S) – то же, для выражения y(x) = a·sin(x+b) +c. Подбирает коэффициенты для синусоидальной функции регрессии. Рисунок синусоиды общеизвестен.
èèè logfit(X,Y) – то же, для выражения y(x) =a·ln(x+b) +c. Задания начального приближения не требуется.
§§è medfit(X,Y) – то же, для выражения y(x) = a+b·x, т.е. для функции линейной регрессии. Задания начального приближения также не требуется. График – прямая линия.
На рис.2.3.3 приведен пример реализации синусоидальной регрессии модельного массива данных по базовой синусоиде в сопоставлении с зональной регрессией полиномом второй степени. Как можно видеть из сопоставления методов по среднеквадратическим приближения к базовой кривой и к исходным данным, известность функции математического ожидания для статистических данных с ее использованием в качестве базовой для функции регрессии дает возможность с более высокой точностью определять параметры регрессии в целом по всей совокупности данных, хотя при этом кривая регрессии не отражает локальных особенностей фактических отсчетов данной реализации. Это имеет место и для всех других методов с заданием функций регрессии.
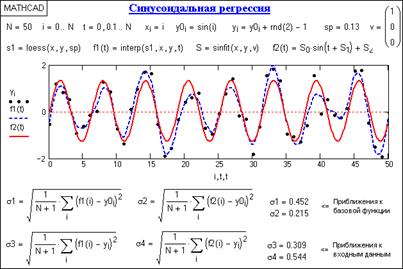
Рис.2.3.3
Сглаживание данных
Сглаживание данных, как искаженных помехами, так и статистических по своей природе, также можно считать частным случаем регрессии без определения символьной формы ее функции, а потому может выполняться более простыми методами. В Mathcad для сглаживания применяются следующие функции:
supsmooth(X,Y) – возвращает вектор сглаженных данных Y с использованием линейного сглаживания методом наименьших квадратов по k-ближайших отсчетов с адаптивным выбором значения k с учетом динамики изменения данных. Значения вектора Х должны идти в порядке возрастания.
ksmooth(X,Y,b) – вычисляет вектор сглаженных данных на основе распределения Гаусса. Параметр b задает ширину окна сглаживания и должен быть в несколько раз больше интервала между отсчетами по оси х.
medsmooth(Y,b) - вычисляет вектор сглаженных данных по методу скользящей медианы с шириной окна b, которое должно быть нечетным числом.
Сопоставление методов сглаживания приведено на рис.2.4.1 Как можно видеть на этом рисунке, качество сглаживания функциями supsmooth(X,Y) и ksmooth(X,Y,b) практически идентично (при соответствующем выборе параметра b). Медианный способ уступает по своим возможностям двум другим. Можно заметить также, что на концевых точках интервала задания данных качество сглаживания ухудшается, особенно в медианном способе, который вообще не может выполнять свои функции на концевых интервалах длиной b/2.

Рис.2.4.1