Глава 3
ПРЕДСТАВЛЕНИЕданных В ПАМЯТИ ЭВМ
3.1. Понятие структуры данных
Издавна люди обрабатывали числовые данные о своей деятельности и об окружающем их мире, вовлечённом в эту деятельность. Уже к моменту появления ЭВМ (середина XX в.) процессы обработки данных при решении инженерных и научных задач были достаточно хорошо приспособлены для реализации на машине. С иным положением столкнулись экономисты, лингвисты и другие специалисты, для которых применение ЭВМ стало необходимостью. При постановке задач для решения её на ЭВМ потребовалось существенно повысить требования к обобщению представления данных. В ходе развития автоматизации программирования было установлено, что и сами программы следует рассматривать как объекты сложной структуры, подлежащие обработке на ЭВМ. Наконец, переход к интегрированной обработке данных в вычислительных системах и сетях значительно повысил интерес к методам размещения и поиска данных в памяти большого объёма.
В результате были определены объекты, отвечающие понятию струк-туры данных, и процессы, в которых эти объекты преобразуются; этим объектам были сопоставлены классы структур реальных данных. Так возникла прикладная дисциплина структуры данных. Она пользуется методами дискретной математики (теории множеств, математической логики, теории графов). Эти методы применяются для описания общих свойств и структур совокупностей данных. Такое описание строится, чтобы создавать эффективные алгоритмы обработки данных, упорядочивать сбор и хранение данных, и, в конечном счёте, оптимизировать потоки и ресурсы информации.
Правильный подход к разработке эффективного алгоритма для данной задачи - изучить её сущность. Часто задачу можно сформулировать на языке основных математических понятий, таких, как множество, и тогда алгоритм для неё можно изложить в терминах основных операций над основными объектами. Далее нужно проанализировать несколько структур данных и выбрать ту из них, которая лучше всего подходит для задачи в целом. Таким образом, разработка эффективного алгоритма предполагает выбор подходящей структуры данных. Не случайно возникла формула [9]:
Алгоритмы + структуры данных = программы
Информация, обрабатываемая вычислительной машиной при решении какой-либо задачи, состоит из некоторых данных о действительности. Данные являются абстракцией действительности, поскольку в них игнорируются некоторые свойства и характеристики реальных процессов, ситуаций либо объектов, несущественные для решаемой задачи. На основе этой абстракции строится математическая модель задачи (класса задач). Кроме того, данные организуются в определённые структуры (СД).
Итак, сначала надо выбрать (построить) модель и СД, описывающие решаемую задачу. Затем следует выбрать способ представления в памяти машины этой информации; здесь выбор предоставляется средствами, которыми обладает вычислительная машина, точнее, её программное обеспечение. В большинстве случаев эти два этапа взаимозависимы. Выбор представления данных в машине (машинных СД) часто бывает затруднителен, он не определяется однозначно имеющимися средствами. Его следует осуществлять с учётом операций, производимых над данными.
В привычной математической нотации используются числа, множества, последовательности и т. д., а не такие машинно-зависимые понятия, как последовательности разрядов. С другой стороны, неразумно писать программу для машины с помощью абстрактных нотаций, не затрагивая проблему представления. В качестве компромисса между этими край-ностями разработан машинно-независимый язык программирования Паскаль, для которого существует эффективный машинный транслятор. Именно этот язык используется в данном учебном пособии.
В программировании используется принцип, что каждая константа, переменная, выражение или функция бывает определённого типа. Этот тип существенным образом характеризует множество значений, которые являются константами, которые может принимать переменная либо выражение или которые может вырабатывать функция. Информацию о типах использует транслятор для проверки вычислимости и правильности различных конструкций языка.
Память вычислительной машины - это однородная совокупность разрядов без какой-либо структуры. Но именно абстрактная структура позволяет программисту определять типы данных в форме однообразных записей в ЭВМ.
В большинстве случаев новые типы данных определяются с помощью ранее определённых типов данных. Значения, принадлежащие к такому типу, обычно представляют собой совокупность значений компонент, принадлежащих к определённым ранее типам компонент; такие составные значения называются структурированными. Если имеется только один компонент, т. е. все компоненты принадлежат к одному типу, то он называется базовым.
Число различных значений, принадлежащих типу Т, называется кардинальным числом Т. Кардинальное число определяет размер памяти, необходимой для размещения в ней переменной x типа Т. Этот факт обозначается так: x:Т.
Большинство так называемых усложненных структур: последовательности, деревья, графы и т. д. - характеризуются тем, что их кардинальные числа бесконечны. Это отличие от структур с конечными кардинальными числами очень важно и имеет существенные практические следствия.
Последовательность с базовым типом Т0 - это любая пустая последовательность либо конкатенация последовательностей (с базовым типом Т0) и значения типа Т0.
Поскольку типы компонент также могут быть составными, можно построить целую иерархию структур, но конечные компоненты структур, разумеется, должны быть атомарными. Самый простой способ описания простого неструктурированного типа - это перечисление значений этого типа. Например, простой тип фигура может быть описан своими значениями: type фигура = (прямоугольник, квадрат, эллипс, круг). Но кроме типов, задаваемых программистом, нужно иметь стандартные типы, которые называются предопределёнными. Они обычно включают числа, логические переменные и множество символов печати.
Неструктурированный простой тип - множество, задаваемое перечислением его возможных значений. Стандартные простые типы - целые числа, вещественные числа, логические значения, множество символов печати, обозначаемые integer, real, boolean, char. Если значения некоторого типа упорядочены, то такой тип называется скалярным.
С учётом практических задач представления и использования данных универсальные языки программирования располагают определёнными методами структурирования. Эти методы позволяют строить структуры, описываемые как статические типы: массив, запись, множество и последовательность (файл). Более сложные структуры (списки, деревья, графы и т.д.) создаются во время выполнения программы, причём их размеры и вид могут изменяться; это динамические типы. Таким образом, различают статические и динамические структуры данных.
Массив - это наиболее широко известная структура данных; во многих языках это единственная структура, которая существует в явном виде. Массив - это регулярная структура: все его компоненты одного типа (базового). Массив - также структура с так называемым случайным (произвольным) доступом, все его компоненты выбираются произвольно и являются одинаково доступными.
Для обозначения отдельной компоненты к имени всего массива добавляется индекс, позволяющий выбирать компоненту. Индекс должен иметь значение типа, определённого как тип индекса массива. Описание регулярного типа Т задаёт таким образом не только базовый тип Т0, но и тип индексов l:
type T = array [l] of Т0
Приведём примеры описания регулярного типа:
type Row = array [1…5] of real
type Card = array [1…80] of char
Обычно считается, что массивы никак не упорядочены. Компоненты массива, в свою очередь, могут быть составными. Переменная-массив, компоненты которой являются массивами, называется матрицей. В качестве примера можно представить себе одномерный массив, компоненты которого являются векторами-столбцами одинаковой длины.
Записи. Самый общий метод получения составных типов - это объединение компонент, принадлежащих к произвольным, возможно, тоже составным типам, в один составной тип. Примеры из математики: комплексные числа, состоящие из двух вещественных чисел; координаты точек, состоящие из двух или более вещественных чисел, в зависимости от размерности пространства, заданного системой координат. Пример из обработки данных - это описание людей с помощью нескольких существенных характеристик, таких, как имя, фамилия, дата рождения, пол и семейное положение.
В теории множеств [5] такой составной тип называется декартовым произведением типов компонент. При этом число компонент составного типа равно произведению чисел компонент всех типов. В обработке данных комбинированные типы, такие, как описание людей или объектов, часто встречаются в файлах или "банках данных" и представляют собой записи существенных характеристик человека или объекта. Поэтому слово "запись" (record) стало широко принятым для обозначения подобной совокупности данных вместо термина "декартово произведение". Декартово произведение в принципе содержит все комбинации значений типов компонент, однако на практике не все такие комбинации могут быть "законными", т.е. иметь смысл.
В общем виде составной тип Т определяется следующим образом:
type T = record S1:T1
S2: T2
…
Sn: Tn
End.
Рассмотрим пример описания записей:
type Date = record day:1…31;
month:1…12;
year:1…2000
End.
Множество. Третья фундаментальная структура данных - множество (set). Значениями переменной x типа Т множества является совокупность элементов базового типа, Т0.
Его тип определяется таким образом: type T = set of T0.
Рассмотрим способы распределения (размещения) данных в оперативной памяти ЭВМ.
Оперативная память машины однородна и может быть представлена как линейка, состоящая из большого числа ячеек, в каждой из которых размещается одно данное. Доступ к некоторой ячейке для записи либо считывания данного осуществляется благодаря тому, что каждая ячейка имеет свой адрес (номер), явный или неявный; адресация ячеек, по умолчанию, сквозная. Для того, чтобы обеспечить эффективное использование памяти при наличии большого разнообразия математических моделей данных, надо так организовать данные (распределить их в памяти), чтобы был удобным доступ к нужной ячейке и чтобы основные операции над содержимым ячеек памяти: добавление (включение) или удаление (исключение) данного - не нарушали (не затрудняли) порядок следования данных.
Существуют два способа распределения данных в памяти ЭВМ: последовательное и связанное. В первом случае данные расположены в ячейках подряд (номера ячеек идут подряд), т. е. порядок следования элементов задаётся неявно требованием, чтобы смежные элементы последовательности находились в смежных ячейках памяти. Кроме того, имеет место фиксированное соотношение между номером i ячейки и элементом последовательности Si. Во втором случае данные связаны между собой специальными указателями, на которые отводится дополнительное место в ячейке; при этом каждому элементу S i последовательности данных поставлен в соответствие указатель Pi, отмечающий ячейку, в которой записаны элемент Si+1 и указатель на следующий за ним элемент.
Неудобство включения и исключения элементов при последовательном распределении происходит из-за того, что многие элементы последовательности во время включения или исключения должны передвигаться.
С помощью связанных распределений удалось добиться большей гибкости, потеряв некоторую информацию. Последовательное распределение позволяет иметь быстрый и прямой доступ к любому элементу последовательности. В связанном распределении доступ ко всем элементам последовательности, кроме первого, не является прямым и эффективным. Например, при последовательном представлении, если длина последовательности задана, то легко можно найти её срединный элемент. Это же самое труднее сделать, если последовательность задаётся связанным распределением; кроме того, приходится тратить память на указатели Pi.
Последовательное распределение наиболее естественно для статических структур данных, а связанное – для динамических.
При выборе последовательного или связанного представления разумно сначала проанализировать типы операций, которые будут выполняться над последовательностью. Если операции проводятся преимуще-ственно над случайными элементами, осуществляют поиск специфических элементов или проводят упорядочивание элементов, то обычно лучше последовательное распределение. Связанное распределение предпочтительнее, если в основном используются операции включения и/или исключения, а также сцепления и/или разбиения последовательности.
В языках программирования высокого уровня обязательно используются структуры данных, существенно более сложные, чем массивы. Ознакомимся с такими структурами данных, как списки, с помощью которых можно представлять множества, графы и деревья.
Списки и их разновидности
С математической точки зрения список - конечная последовательность элементов, взятых из некоторого подходящего множества. Описание алгоритма часто включает в себя некоторый список, к которому добавляются и из которого удаляются элементы, причём эти элементы в основном находятся где-то в середине списка (в частности, элемент может находиться и на краю списка).
Рассмотрим список
EL1, EL2, EL3, EL4. (3.1)
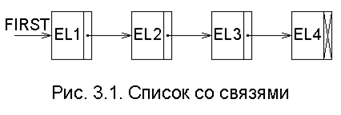 Простейшей его реализацией будет структура последовательно связанных компонент, изображенная на рис. 3.1. Каждая компонента в этой структуре состоит из двух ячеек памяти. Первая ячейка содержит сам эле-мент, вторая - указатель следующего элемента, причём последняя компонента не имеет указателя (точ-нее: его значение равно 0), а указатель на первую компонен-ту (FIRST) является внешним.
Простейшей его реализацией будет структура последовательно связанных компонент, изображенная на рис. 3.1. Каждая компонента в этой структуре состоит из двух ячеек памяти. Первая ячейка содержит сам эле-мент, вторая - указатель следующего элемента, причём последняя компонента не имеет указателя (точ-нее: его значение равно 0), а указатель на первую компонен-ту (FIRST) является внешним.
Такую структуру можно реализовать в виде двух массивов, которые на рис. 3.2 названы NAME и NEXT. Если COMP - компонента в рассматриваемом массиве, то NAME[COMP] - сам элемент, хранящийся там, а NEXT[COMP] - индекс следующего элемента в списке (если такой элемент существует). Если COMP - индекс последнего элемента в этом списке, то NEXT[COMP]=0.
На рис. 3.2 NEXT[0] означает постоянный указатель на первую компоненту в списке. Заметим, что порядок элементов в массиве NAME не совпадает с их порядком в списке. Однако рис. 3.2 даёт верное представ-
| Index | NAME | NEXT |
| __ | ||
| EL1 | ||
| EL4 | ||
| POS®3 | EL2 | |
| EL3 | ||
| FREE®5 | __ | __ |
| Рис. 3.2. Представление списка (3.1) из четырех элементов |

ление списка, изображенного на рис. 3.1, так как массив NEXT располагает
Процедура INS c формальными параметрами X, FREE, POS имеет вид
procedure INS (X, FREE, POS);
Begin
NAME[FREE]Х;
NEXT[FREE]NEXT[POS];
NEXT[POS]FREE;
End.
Нетрудно видеть, что время выполнения процедуры INS не зависит от размера списка.
Пример 3.1. Пусть необходимо вставить в список (3.1) новый элемент NEL (New ELement) после элемента EL2 и получить список
EL1, EL2, NEL, EL3, EL4. (3.2)
Если пятая ячейка (FREE=5) в каждом массиве на рис. 3.2 пуста, можно вставить X=NEL после EL2 (POS=3), вызвав процедуру INS c фактическими параметрами NEL, 5, 3. В результате выполнения трёх операторов в процедуре INS получим NAME[5]=NEL, NEXT[5]=4 и NEXT[3]=5; тем самым создадутся массивы, показанные на рис. 3.3.
| Index | NAME | NEXT |
| __ | ||
| EL1 | ||
| EL4 | ||
| POS®3 | EL2 | |
| EL3 | ||
| NEL | ||
| FREE®6 | __ | __ |
| Рис. 3.3. Представление списка со вставленным элементом NEL |

Ещё две основные операции над списками - конкатенация (сцепление) двух списков, в результате которой образуется единственный список, и обратная к ней операция расцепления списка после заданного элемента, результатом которого будут два списка.
Конкатенацию можно выполнить за ограниченное (постоянной величиной) число шагов, включив в представление списка ещё один указатель. Этот указатель даёт индекс последней компоненты списка и тем самым позволяет обойтись без просмотра всего списка для определения его последнего элемента. Расцепление можно выполнить также за ограниченное время, если известен индекс компоненты списка, непосредственно предшествующей месту расцепления.
Тривиальной модификацией связанного списка будет следующее, несколько более гибкое представление последовательности: если Pn указывает на S1 (см. рис. 3.1), то такой список называется циклическим. Это представление даёт возможность достигнуть любого элемента из любого другого элемента последовательности. Включение и исключение элементов здесь осуществляется так же, как и в нециклических списках, в то время как сцепление и расцепление реализуются несколько более сложно.
 Еще большая гибкость достигается, если использовать дважды связанный список, когда каждый элемент SI последовательности вместо одного имеет два связанных с ним указателя на элементы Si-1 и Si+1 (рис. 3.4). В таком списке для любого элемента имеется мгновенный прямой доступ к предыдущему и последующему элементам, в связи с чем облегчаются такие операции, как включение нового элемента перед Si и исключение элемента Si без предварительного знания его предшественника. Если есть необходи-мость, дважды связанный список очевид-ным образом можно сделать циклическим.
Еще большая гибкость достигается, если использовать дважды связанный список, когда каждый элемент SI последовательности вместо одного имеет два связанных с ним указателя на элементы Si-1 и Si+1 (рис. 3.4). В таком списке для любого элемента имеется мгновенный прямой доступ к предыдущему и последующему элементам, в связи с чем облегчаются такие операции, как включение нового элемента перед Si и исключение элемента Si без предварительного знания его предшественника. Если есть необходи-мость, дважды связанный список очевид-ным образом можно сделать циклическим.
 |  | ||
Списки можно сделать проходимыми в обоих направлениях, если добавить ещё один массив, называемый PREV (PREVious – предыдущий). Значение PREV[I] равно ячейке, в которой помещается тот элемент списка, который стоит непосредственно перед элементом из ячейки I.
Рассмотрим широко распространённые специального вида списки, с которыми работают ограниченными приёмами: 1) элементы добавляются или удаляются только на одном конце;2)элементы добавляются на одном конце, а удаляются – с другого конца списка. В первом случае доступ к элементам основан на принципе "последний вошёл - первый вышел" (LIFO - Last Input, First Output), и в этом случае список называется стеком, или магазином. Во втором случае доступ к элементам основан на принципе “первый вошёл - первый вышел” (FIFO - First Input, First Output); такого рода список называется очередью.
Первый специального вида список – стек, который обычно реализуется в виде одного массива. Например, список EL1, EL2, EL3 можно хранить в массиве NAME, как показано на рис. 3.6. Переменная TOP (вершина) является указателем последнего элемента, добавленного к стеку.
 Чтобы добавить новый элемент в стек, значение TOP увеличивают на 1, а затем помещают новый элемент в NAME[TOP]. Однако следует иметь в виду, что массив NAME имеет конечную длину l, поэтому перед попыткой вставить новый элемент следует проверить, что TOP< l -1.
Чтобы добавить новый элемент в стек, значение TOP увеличивают на 1, а затем помещают новый элемент в NAME[TOP]. Однако следует иметь в виду, что массив NAME имеет конечную длину l, поэтому перед попыткой вставить новый элемент следует проверить, что TOP< l -1.
Чтобы удалить элемент из вершины стека, надо просто уменьшить значение TOP на 1.
Чтобы узнать, пуст ли стек, достаточно проверить, не имеет ли TOP значение меньше нуля.
Понятно, что время выполнения операций PUSH (ВТОЛКНУТЬ) и POP (ВЫТОЛКНУТЬ) и проверка пустоты стека не зависят от числа элементов в стеке.
Стек обычно используется (например, в микропроцессорах) для хранения адресов возврата при обращении к подпрограммам, а также для запоминания состояния внутренних регистров при обработке прерываний.
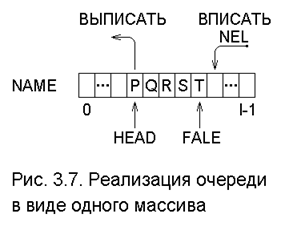 Другой специальный вид списка - очередь. Как и стек, очередь можно реализовать одним массивом, как показано на рис. 3.7, где приведена очередь, содержащая список из эле-ментов P, Q, R, S, T. Два указателя обозначают ячейки текущих концов очереди, переднего (HEAD - голова) и заднего (TAIL - хвост). Чтобы добавить (ВПИСАТЬ) новый элемент к очереди, полагают TAIL = TAIL+1 и помещают новый элемент в NAME[TAIL]. Чтобы удалить (ВЫПИСАТЬ) элемент из очереди, заменяют HEAD на HEAD +1.
Другой специальный вид списка - очередь. Как и стек, очередь можно реализовать одним массивом, как показано на рис. 3.7, где приведена очередь, содержащая список из эле-ментов P, Q, R, S, T. Два указателя обозначают ячейки текущих концов очереди, переднего (HEAD - голова) и заднего (TAIL - хвост). Чтобы добавить (ВПИСАТЬ) новый элемент к очереди, полагают TAIL = TAIL+1 и помещают новый элемент в NAME[TAIL]. Чтобы удалить (ВЫПИСАТЬ) элемент из очереди, заменяют HEAD на HEAD +1.
Так как массив NAME имеет конечную длину (пусть l), указатели HEAD и TAIL рано или поздно доберутся до его конца. Если есть уверенность в том, что длина списка, представленногo этой очередью, никогда не превысит l, то можно трактовать NAME[0] как элемент, следующий за элементом NAME[ l -1]. Другими словами, можно считать этот список кольцевым.
Очередь обычно используется для предварительного анализа команд в конвейере команд (например, в персональных компьютерах) или при организации векторной обработки данных в суперЭВМ.
При работе со списками удаляемые элементы не обязательно физически стирать, однако при этом возникает проблема сбора мусора (ненужных ячеек памяти).
Элементы, расположенные в виде списка, сами могут быть сложными структурами. При работе, например, со списками массивов, на самом деле массивы не добавляются и не удаляются, ибо каждое добавление или удаление потребовало бы времени, пропорционального размеру массива. Вместо этого добавляются или удаляются указатели массивов. Таким образом, сложную структуру можно добавить или удалить за фиксированное время, не зависящее от её размера.
Представление множеств
Как было отмечено выше, выбор структуры данных, т. е. способа организации данных в памяти машины, определяется теми операциями, которые будут проводиться над данными.
Рассмотрим основные операции над множествами:
1. Принадлежать (a, S): Если a ÎS, то выдаётся сообщение "да".
2. Вставить (a, S): S ® SÈ{ a }.
3. Удалить (a, S): S ® S\{ a }.
4. Найти (a). Сообщается имя того множества, которому в данный момент принадлежит а (если а принадлежит более чем одному множеству, то операция не определена).
5. Объединить (S1, S2, S3): S3=S1ÈS2.
6. Пересечь (S1, S2, S3): S3=S1ÇS2.
7. Сцепить (S1, S2, S3): S3=S1. S2.
8. Расцепить (a, S). Предполагается, что множество S упорядочено отношением 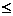 . Операция разбивает S на два множества: S1={ b ï b
. Операция разбивает S на два множества: S1={ b ï b  a и b ÎS}; S2={ b ï b > a и b ÎS}.
a и b ÎS}; S2={ b ï b > a и b ÎS}.
9. MIN (S). Операция выдаёт наименьший (относительно ) элемент множества S.
10. MAX (S). Операция выдаёт наибольший (относительно ) элемент множества S.
Множество в памяти ЭВМ может быть представлено тремя способами: списком, характеристическим вектором и одномерным массивом.
Обычно для представления множеств применяются списки. При этом объём памяти, необходимый для представления множества, пропор-ционален числу его элементов. Время, требуемое для выполнения операций над множествами, зависит от природы операций. Например, пусть А и В - два множества. Операция А 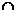 В требует времени, по крайней мере пропорционального сумме размеров этих множеств, поскольку как список, представляющий А, так и список, представляющий В, надо просмотреть хотя бы один раз.
В требует времени, по крайней мере пропорционального сумме размеров этих множеств, поскольку как список, представляющий А, так и список, представляющий В, надо просмотреть хотя бы один раз.
Аналогично операция АÈВ требует времени, пропорционального сумме размеров множеств, поскольку надо выделить элементы, входящие в оба множества, и вычеркнуть каждый экземпляр каждого такого элемента. Если же А и В не пересекаются, можно найти АÈВ за время, не зависящее от размера А и В. Для этого достаточно сделать лишь конкатенацию списков, представляющих А и В. Задача объединения двух непересекающихся множеств усложняется, если необходимо быстро определить, входит ли данный элемент в данное множество.
Рассмотрим представление множества в виде двоичного (битового) вектора. Пусть U - универсальное множество (рассматриваемые множества являются его подмножествами), состоящее из n элементов. Линейно упорядочим его. Подмножество S  U представляется в виде вектора Vs из n битов, такого, что i -й разряд в Vs равен 1 тогда и только тогда, когда i -й элемент множества U принадлежит S. Будем называть Vs характеристическим вектором для S.
U представляется в виде вектора Vs из n битов, такого, что i -й разряд в Vs равен 1 тогда и только тогда, когда i -й элемент множества U принадлежит S. Будем называть Vs характеристическим вектором для S.
Представление в виде двоичного вектора удобно тем, что можно определить принадлежность i -го элемента множества U данному множеству за время, не зависящее от размера данного множества. Более того, основные операции над множествами, такие, как объединение и пересечение, можно осуществлять как операции над двоичными векторами.
Полезность характеристических векторов вытекает из их компактности, существования простого фиксированного соотношения между i и Si (адресом ячейки и значением i -го разряда вектора) и возможности при таком представлении очень легко добавлять и исключать элементы.
Например, характеристический вектор (ХВ) начального сегмента последовательности простых чисел имеет вид
Si 1 2 3 4 5 6 7 8 9 10
ХВ для простых чисел 0 1 1 0 1 0 1 0 0 0
Главное неудобство ХВ состоит в том, что они неэкономичны. Исключение составляют "плотные" (в смысле малого числа нулей) подпоследовательности последовательности S1, S2, S3,.... Кроме того, их трудно использовать, если не существует простого соотношения между i и Si. Если такое соотношение сложное, то использование ХВ может быть очень неэкономичным в смысле времени обработки. Если последовательности недостаточно плотные, то значительным может оказаться объем памяти.
Если операции над двоичными векторами нельзя считать пер-вичными (т. е. выполняемыми за единицу времени), то можно с таким же успехом вместо характеристического вектора определить массив А, для которого А[ i ]=1 тогда и только тогда, когда i -й элемент множества U принадлежит A. При таком представлении все ещё легко выяснить, принадлежит ли данный элемент данному множеству.
Недостаток этого представления в том, что объединение и пересечение занимает время, пропорциональное |U|, а не размерам рассматриваемых множеств. Подобно этому память, требуемая для хранения множества A, пропорциональна |U|, a не |A|.