1. Исследование точности аппроксимации с помощью полиномиальной модели.
1.1. Используя Excel, получить выборку исходных данных объемом 110 значений (100 для обучения и 10 для контроля),  и
и  , имеющих равномерное распределение в указанных выше пределах (
, имеющих равномерное распределение в указанных выше пределах ( ), и соответствующие этой паре значения
), и соответствующие этой паре значения  . Для этого необходимо использовать последовательность: «Сервис», «Анализ данных», «Генерация случайных чисел», «Количество переменных» (указать 1), «Количество чисел» (указать 110), «Вид закона распределения» - равномерный, «Нижний и верхние пределы»- соответствуют значениям, указанным в задании. Использовать для вывода указанный диапазон (см. рисунок 3.3).
. Для этого необходимо использовать последовательность: «Сервис», «Анализ данных», «Генерация случайных чисел», «Количество переменных» (указать 1), «Количество чисел» (указать 110), «Вид закона распределения» - равномерный, «Нижний и верхние пределы»- соответствуют значениям, указанным в задании. Использовать для вывода указанный диапазон (см. рисунок 3.3).

1.2. Подготовить исходные данные для построения полиномиальной модели исследования, для чего, выделив столбец «С», вставить еще шесть столбцов (для 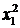 ,
,  ,
,  ,
,  ,
,  ,
,  - соответственно), и реализовать в них данные выражения для получения степенных зависимостей. Выделить 50 первых строк и скопировать их на отдельный лист через «Специальную вставку» - «Значения».
- соответственно), и реализовать в них данные выражения для получения степенных зависимостей. Выделить 50 первых строк и скопировать их на отдельный лист через «Специальную вставку» - «Значения».
1.3. Провести дискриминантный анализ с целью подгонки вида полиномиальной зависимости, обеспечивающей 95%-ю достоверность получаемой регрессионной модели. Для этого с помощью «Сервис», «Анализ данных», «Регрессия» указать: «Диапазон Y» $I$2:$I$51; «Диапазон X» $A$2:$H$51, «Параметры вывода»,«Новый рабочий лист» (см. рисунок 3.4).

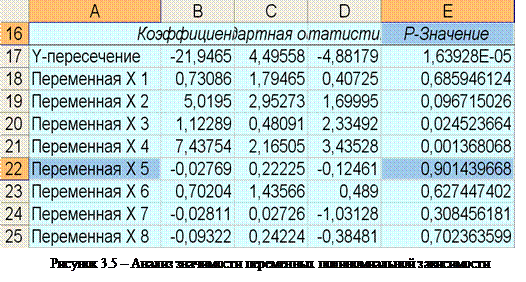
Проанализировать полученные данные на предмет значимости переменных полиномиальной модели и определения номера столбца, который необходимо исключить из анализа. Для этого анализируется столбец «Е» (Р-Значение), значения которого должны быть меньше 0.05 (т.е. 5%). В примере (рисунок 3.5) этим условиям в большей степени не удовлетворяет переменная  (), которая подлежит исключению.
(), которая подлежит исключению.
Последовательно удаляя такие переменные, т.е. соответствующие им столбцы в исходных данных, необходимо найти наиболее адекватный вид полинома. Если назначим свободный член («Y-пересечение»), его исключают, выставляя флажок в основном окне «Регрессия» - «Константа-ноль».
Полученные результаты могут выглядеть следующим образом:
(см. рисунок 3.6), а полиномиальная зависимость иметь следующий вид:
 .
.

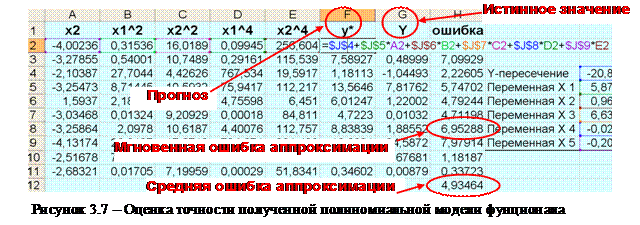
1.4. Провести исследование точности модели, для чего скопировать на отдельный лист 51..60 строчки исходных данных с листа 1, используя «Специальную вставку», «Значения». Удалить все отсутствующие столбцы (те, которые были удалены в результате анализа), и перенести на этот же лист полученные коэффициенты при столбцах. Реализовать полученную полиномиальную зависимость, рассчитать модуль получаемой ошибки для десяти контрольных значений и посчитать ее среднее значение (см. рисунок 3.7).
1.5. Провести исследование точности аппроксимации для объема выборки 60, 70, 80, 90 и 100, повторяя пункты 1.2-1.4. При этом объем контрольной выборки составляет 10 элементов, т.е. 61..70, 71..80, 81..90, 91..100, 101..110 значения исходных данных, соответственно Результаты аппроксимации занести в таблицу 3.1.
Таблица 3.1 – Результаты процедур (средняя ошибка) аппроксимации различными способами.
 Объем выборки
Тип аппроксимации Объем выборки
Тип аппроксимации
| ||||||
| Полиномиальная аппроксимация | ||||||
| Нечеткая аппроксимация моделью Сугено | ||||||
| Нечеткая аппроксимация моделью Мамдани |
2. Исследование точности аппроксимации с помощью модели нечеткого логического вывода, реализованного по схеме Сугено.
2.1. Подготовить исходные данные для аппроксимации в Matlab. Для этого необходимо три столбца ( ) по 110 значений выделить, скопировать в буфер, вставить в блокнот, провести замену «,» на «.» (запятые заменить на точки), выделить все и скопировать в буфер.
) по 110 значений выделить, скопировать в буфер, вставить в блокнот, провести замену «,» на «.» (запятые заменить на точки), выделить все и скопировать в буфер.
Набрать в командном окне:
in(1:110,1:3)=0;
В рабочей области открыть редактор переменных, переменную «in» и скопировать в нее содержание буфера. Создать переменную «in1» - обучающую выборку:
in1=in(1:50,:);
и контрольную выборку «in2»:
in2=in(51:60,:).
2.2. Открыть Fis-редактор, для чего нажать кнопку «Старт», выбрать: «Инструменты» («Toolboxes»), «Нечеткая логика» («Fuzzy Logic»), Fis-редактор («Fis Editor»). В появившемся окне выбрать:«File», «New Fis», «Sugeno».
Так как аппроксимируется зависимость двух аргументов ( и
и 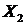 ), то необходимо создать два входа, добавив входную переменную,так, как показано на рисунке 3.8 («File», «Add Variable», «Input»).
), то необходимо создать два входа, добавив входную переменную,так, как показано на рисунке 3.8 («File», «Add Variable», «Input»).

Перейти в окно редактора гибридных нечетких нейросетей ((«File», «Anfis»). В появившемся окне загрузить аналогично переменную «in2» для теста.
ВНИМАНИЕ!!! Установить параметр в окне «Load data» «Type» - «Testing».
Проконтролировать отображение точек в окне.
В окне «Generate FIS» выставить параметр «Grid partition» и нажать Generate FIS. Настраиваемыми параметрами для модели Сугено являются (см. рисунок 3.10):
- количество термов (функций принадлежности для входов): любое натуральное число,
- вид функции активации для нейросети, осуществляющей подбор параметров правил вывода модели Сугено: один из восьми,
- вид функциональной зависимости, формируемый моделью Сугено: константа или логический функционал.

В процессе проведения лабораторной работы необходимо для каждой выборки (50, 60,… 100) провести исследование наиболее удачной архитектуры модели Сугено, для чего осуществить перебор как количества термов на входе (2, 3, 4), так и типа функций активации. При этом всегда использовать функцию вывода, как линейную. Отказ от выбора константы объясняется её гораздо худшими характеристиками по отношению к линейной, в чем можно легко убедиться. Для такого выбора необходимо заполнить следующую таблицу (таблица 3.2).
Таблица 3.2 – Обоснование выбора параметров модели Сугено для выборки №__ (50, 60…).
| Тип функции
активации
Количество термов входов
| trimf | trapmf | gbellmf | gaussmf | gaus2mf | pimf | dsigmf | psigmf |
Проконтролировать, что нейросеть, реализующая поиск правил логического вывода, сформировалась (нажать «Структура»). При правильном выполнении операций структура нейросети для 4 термов будет следующей (см. рисунок 3.11).

Выставить количество эпох обучения - 300 эпох, алгоритм обучения – гибридный. Запустить модель на обучение. Результаты процесса обучения и конечная ошибка будут указаны, как на рисунке 3.12.
Записать ошибку в таблицу 3.2 для выбранных параметров обучения. Проконтролировать, что с увеличением количества термов точность аппроксимации значительно улучшается.
2.3. Выбрать из полученных результатов (таблица 3.2) наименьшее значение и записать его в таблицу 3.1 для заданного объема выборки.
2.4. Повторить пункты 2.2–2.3 для оставшихся значений объема выборки (60, 70, 80, 90, 100), всякий раз перенабирая строки для задания «in1» и «in2».

2.5. Закрыть окно Anfis – редактора и в окне модели Сугено проконтролировать вид воспроизводимой поверхности, полученные линейные зависимости и общую структуру логического вывода с найденными правилами (см. рисунок 3.13).
3. Исследование точности аппроксимации с помощью модели нечеткого логического вывода, реализованного по схеме Мамдани.
3.1. Повторить п. 2.2, за исключением того, что необходимо выбрать модель Мамдани. Создать два входа логического вывода, добавив входную переменную.
Затем переименовать входы, поменяв имя в рубрике Name на и . В каждом аргументе определить функции принадлежности как гаусовские (см. рисунок 3.14) и выставить для обоих входов соответствующие граничные значения ( и
и  ). Определить для выходного аргумента две дополнительные функции принадлежности, добавив их Edit, Add, Add MFs.
). Определить для выходного аргумента две дополнительные функции принадлежности, добавив их Edit, Add, Add MFs.

Выставить значения выхода в пределах от -50 до +50. Определить тип функции принадлежности выхода как гауссовская функция (см. рисунок 3.15).

3.2. Задать правила логического вывода, очевидные из наблюдения формы исходной зависимости (рисунок 3.2) как следующие (см. таблицу 3.3).
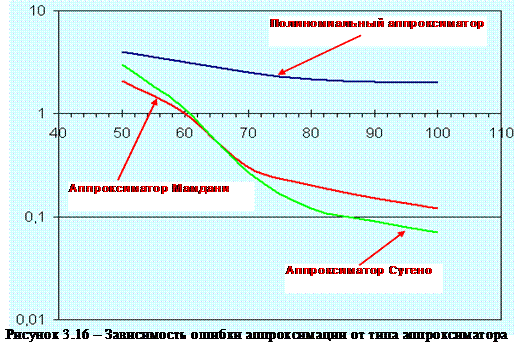
Задать эти правила в модели так, как показано на рисунке 3.16.

Таблица 3.3 – Нечеткая база знаний модели, типа Мамдани
|
|
| 
|
| Низкий | Низкий | Высокий |
| Низкий | Средний | Низкий |
| Низкий | Высокий | Высокий |
| Средний | ---- | Средний |
| Высокий | Низкий | Выше среднего |
| Высокий | Средний | Ниже среднего |
| Высокий | Высокий | Выше среднего |
3.3. Для проведения аппроксимации необходимо, подготовив исходные данные в виде mat файла, воспользоваться программой, осуществляющей параметрическую идентификацию, приведенную в приложении 5. При этом полученную модель нечеткого вывода, в котором реализованы правила (таблица 3.3), необходимо экспортировать на диск в файл «mamdani.fis».
ВНИМАНИЕ!!! Всякий раз при подготовке исходных данных необходимо не забывать изменять объем обучающей выборки и содержание контрольного множества. Имя файла с исходными данными – «exp_data.mat».

4. Исследование эффективности робастных моделей для представления детерминированных функционалов.
4.1. Построение графиков зависимости ошибки аппроксимации от объема обучающей выборки.
4.2. Выявление зон предпочтения типов нечеткого классификатора, относительно объема обучающей выборки (аналогично как на рисунке 3.16).
Список литературы
1. Ярушкина Н.Г., Основы теории нечетких и гибридных систем, - М: 2004 – 320 с.
2. Борисов А.Н., Алексеев А.В., Меркурьев Г.В., Обработка нечеткой информации в системах принятия решений. - М: 1989 – 304 с
3. Заде Л., Понятие лингвистической переменной и его применение к принятию приближенных решений,- М: 1976 – 165 с.
4. Леоненков А.В., Нечеткое моделирование в среде MatLab, - М: 2003 – 736 c.