Алфавитный подход позволяет определить количество информации, заключенной в тексте.
Алфавит – множество символов, используемых при записи текста.
Мощность (размер) алфавита – полное количество символов в алфавите.
Введем следующие обозначения:
N – мощность алфавита;
K - количество символов в тексте;
i - количество информации, которое несет каждый символ;
V – объем информации, содержащейся в тексте.
Если допустить, что все символы алфавита встречаются в тексте с одинаковой частотой (равновероятно), то количество информации, которое несет каждый символ, вычисляется по формуле:
 или
или 
Если весь текст состоит из K символов, то при алфавитном подходе объем содержащейся в нем информации равен:
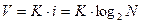
Для представления текста в компьютере используется алфавит из 256 символов. Значит, один символ компьютерного текста несет в себе 8 бит (1 байт) информации, так как

Задачи.
- Книга, набранная с помощью компьютера, содержит 150 страниц, на каждой странице – 40 строк, в каждой строке – 60 символов. Каков объем информации в книге?
- Сколько килобайт составляет сообщение, содержащее 12288 бит?
- Можно ли уместить на одну дискету книгу, имеющую 423 страницы, причем на каждой странице этой книги 46 строк, а в каждой строке 62 символа?
- Сообщение, записанное буквами из 64-символьного алфавита, содержит 20 символов. Какой объем информации оно несет?
- одно племя имеет 32-символьный алфавит, а второе – 64-символьный алфавит. Вожди племен обменялись письмами. Письмо первого племени содержало 80 символов, а письмо второго племени – 70 символов. Сравните объем информации, содержащийся в письмах.
- Информационное сообщение объемом 1,5 Кб содержит 3072 символа. Сколько символов содержит алфавит, при помощи которого было записано это сообщение?
- Объем сообщения, содержащего 2048 символов, составил 1/512 мегабайта. Каков размер алфавита, с помощью которого записано сообщение?
1.Информационный объём текстового сообщения
Расчёт информационного объёма текстового сообщения (количества информации, содержащейся в информационном сообщении) основан на подсчёте количества символов в этом сообщении, включая пробелы, и на определении информационного веса одного символа, который зависит от кодировки, используемой при передаче и хранении данного сообщения.
В традиционной кодировке (КОИ8-Р, Windows, MS DOS,ISO) для кодирования одного символа используется 1 байт (8 бит). Эта величина и является информационным весом одного символа. Такой 8-ми разрядный код позволяет закодировать 256 различных символов, т.к. 28=256
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ два байта (16 бит). С его помощью можно закодировать 216=65536 различных символов.
Итак, для расчёта информационного объёма текстового сообщения используется формула V=K*i, где V – это информационный объём текстового сообщения, измеряющийся в байтах, килобайтах, мегабайтах; K – количество символов в сообщении, i – информационный вес одного символа, который измеряется в битах на один символ.
Рассмотрим примеры.
А) Текстовое сообщение, содержащее 1048576 символов общепринятой кодировки, необходимо разместить на дискете ёмкостью 1,44Мб. Какая часть дискеты будет занята?
Дано:
K=1048576 символов;
i=8 бит/символ
Решение:
V=K*i=1048576*8=8388608бит=1048576байт=1024 Кб=1Мб,
что составляет 1Мб*100%/1,44Мб=69% объёма дискеты
Ответ: 69% объёма дискеты будет занято переданным сообщением
Б) Информация в кодировке Unicode передается со скоростью 128 знаков в секунду в течение 32 минут. Какую часть дискеты ёмкостью 1,44Мб займёт переданная информация?
Дано:
v=128 символов/сек;
t=32 минуты=1920сек;
i=16 бит/символ
Решение:
K=v*t=245760символов
V=K*i=245760*16=3932160бит=491520байт=480 Кб=0,469Мб,
что составляет 0,469Мб*100%/1,44Мб=33% объёма дискеты
Ответ: 33% объёма дискеты будет занято переданным сообщением
Информацию можно разделить на виды по различным критериям:
По способу восприятия:
· Визуальная — воспринимаемая органами зрения.
· Звуковая — воспринимаемая органами слуха.
· Тактильная — воспринимаемая тактильными рецепторами.
· Обонятельная — воспринимаемая обонятельными рецепторами.
· Вкусовая — воспринимаемая вкусовыми рецепторами.
По форме представления:
· Текстовая — передаваемая в виде символов, предназначенных обозначать лексемы языка.
· Числовая — в виде цифр и знаков, обозначающих математические действия.
· Графическая — в виде изображений, предметов, графиков.
· Звуковая — устная или в виде записи и передачи лексем языка аудиальным путём.
· Видеоинформация — передаваемая в виде видеозаписи.
По назначению:
· Массовая — содержит тривиальные сведения и оперирует набором понятий, понятным большей части социума.
· Специальная — содержит специфический набор понятий, при использовании происходит передача сведений, которые могут быть не понятны основной массе социума, но необходимы и понятны в рамках узкой социальной группы, где используется данная информация.
· Секретная — передаваемая узкому кругу лиц и по закрытым (защищённым) каналам.
· Личная (приватная) — набор сведений о какой-либо личности, определяющий социальное положение и типы социальных взаимодействий внутри популяции.
Основоположник кибернетики Норберт Винер дал следующее определение информации: «Информация — это обозначение содержания, полученное нами из внешнего мира в процессе приспосабливания к нему нас и наших чувств»[3].
Кибернетика рассматривает машины и живые организмы как системы, воспринимающие, накапливающие и передающие информацию, а так же перерабатывающие её в сигналы, определяющие их собственную деятельность[12].
Субъективную (семантическую) информацию кибернетика определяет как смысл или содержание сообщения. Информация — это характеристика объекта.
Семиотика — комплекс научных теорий, изучающих свойства знаковых систем. Наиболее существенные результаты достигнуты в разделе семиотики —семантике. Предметом исследований семантики является значение единиц языка, то есть информация, передаваемая посредством языка.
Знаковой системой считается система конкретных или абстрактных объектов (знаков, слов), с каждым из которых определённым образом сопоставлено некоторое значение.
Для передачи информации используют различные знаки или символы, например естественного или искусственного (формального) языка, позволяющие выразить ее в некоторой форме, называемой сообщением.
Сообщение – форма представления информации в виде совокупности знаков (символов), используемая для передачи.
Сообщение как совокупность знаков с точки зрения семиотики (от греч. setneion — знак, признак) – науки, занимающейся исследованием свойств знаков и знаковых систем, — может изучаться на трех уровнях:
1) синтаксическом, где рассматриваются внутренние свойства сообщений, т. е. отношения между знаками, отражающие структуру данной знаковой системы. На этом уровне рассматривают проблемы доставки получателю сообщений как совокупности знаков, учитывая при этом тип носителя и способ представления информации, скорость передачи и обработки, размеры кодов представления информации, надежность и точность преобразования этих кодов и т. п., полностью абстрагируясь от смыслового содержания сообщений и их целевого предназначения. На этом уровне информацию, рассматриваемую только с синтаксических позиций, обычно называют данными, так как смысловая сторона при этом не имеет значения.
Современная теория информации исследует в основном проблемы именно этого уровня. Она опирается на понятие «количество информации», являющееся мерой частоты употребления знаков, которая никак не отражает ни смысла, ни важности передаваемых сообщений. В связи с этим иногда говорят, что современная теория информации находится на синтаксическом уровне.
2) семантическом, где анализируются отношения между знаками и обозначаемыми ими предметами, действиями, качествами, т. е. смысловое содержание сообщения, его отношение к источнику информации. Проблемы семантического уровня связаны с формализацией и учетом смысла передаваемой информации, определения степени соответствия образа объекта и самого объекта. На данном уровне анализируются те сведения, которые отражает информация, рассматриваются смысловые связи, формируются понятия и представления, выявляется смысл, содержание информации, осуществляется ее обобщение.
3) прагматическом, где рассматриваются отношения между сообщением и получателем, т. е. потребительское содержание сообщения, его отношение к получателю.
На этом уровне интересуют последствия от получения и использования данной информации потребителем. Проблемы этого уровня связаны с определением ценности и полезности использования информации при выработке потребителем решения для достижения своей цели. Основная сложность здесь состоит в том, что ценность, полезность информации может быть совершенно различной для различных получателей и, кроме того, она зависит от ряда факторов, таких, например, как своевременность ее доставки и использования.
Для каждого из рассмотренных выше уровней проблем передачи информации существуют свои подходы к измерению количества информации и свои меры информации. Различают соответственно меры информации синтаксического уровня, семантического уроня и прагматического уровня.
Меры информации синтаксического уровня. Количественная оценка информации этого уровня не связана с содержательной стороной информации, а оперирует с обезличенной информацией, не выражающей смыслового отношения к объекту. В связи с этим данная мера дает возможность оценки информационных потоков в таких разных по своей природе объектах, как системы связи, вычислительные машины, системы управления, нервная система живого организма и т. п.
Для измерения информации на синтаксическом уровне вводятся два параметра: объем информации (данных) – Vд (объемный подход) и количество информации – I (энтропийный подход).
Объем информации Vд (объемный подход). При реализации информационных процессов информация передается в виде сообщения, представляющего собой совокупность символов какого-либо алфавита. При этом каждый новый символ в сообщении увеличивает количество информации, представленной последовательностью символов данного алфавита. Если теперь количество информации, содержащейся в сообщении из одного символа, принять за единицу, то объем информации (данных) Vд в любом другом сообщении будет равен количеству символов (разрядов) в этом сообщении. Так как одна и та же информация может быть представлена многими разными способами (с использованием разных алфавитов), то и единица измерения информации (данных) соответственно будет меняться.
Так, в десятичной системе счисления один разряд имеет вес, равный 10, и соответственно единицей измерения информации будет дит (десятичный разряд). В этом случае сообщение в виде п -разрядного числа имеет объем данных Vд = п дит. Например, четырехразрядное число 2009 имеет объем данных Vд = 4 дит.
В двоичной системе счисления один разряд имеет вес, равный 2, и соответственно единицей измерения информации будет бит (bit (binary digit) – двоичный разряд). В этом случае сообщение в виде n -разрядного числа имеет объем данных Vд = п бит. Например, восьмиразрядный двоичный код 11001011 имеет объем данных Vд = 8 бит.
В современной вычислительной технике наряду с минимальной единицей измерения данных бит широко используется укрупненная единица измерения байт, равная 8 бит. Именно восемь битов требуется для того, чтобы закодировать любой из 256 символов алфавита клавиатуры компьютера (256=28).
При работе с большими объемами информации для подсчета ее количества применяют более крупные единицы измерения:
1 Килобайт (Кбайт) = 1024 байт = 210 байт,
1 Мегабайт (Мбайт) = 1024 Кбайт = 220 байт = 1 048 576 байт;
1 Гигабайт (Гбайт) = 1024 Мбайт = 230 байт = 1 073 741 824 байт;
1 Терабайт (Тбайт) = 1024 Гбайт = 240 байт = 1 099 511 627 776 байт;
1 Петабайт (Пбайт) = 1024 Тбайт = 250 байт = 1 125 899 906 842 624 байт.
Количество информации I (энтропийный подход). В теории информации и кодирования принят энтропийный подход к измерению информации. Этот подход основан на том, что факт получения информации всегда связан с уменьшением разнообразия или неопределенности (энтропии) системы. Исходя из этого, количество информации в сообщении определяется как мера уменьшения неопределенности состояния данной системы после получения сообщения. Неопределенность может быть интерпретирована в смысле того, насколько мало известно наблюдателю о данной системе. Как только наблюдатель выявил что-нибудь в физической системе, энтропия системы снизилась, так как для наблюдателя система стала более упорядоченной.
Таким образом, при энтропийном подходе под информацией понимается количественная величина исчезнувшей в ходе какого-либо процесса (испытания, измерения и т.д.) неопределенности. При этом в качестве меры неопределенности вводится энтропия Н, а количество информации равно:
I = Hapr – Haps
где, Hapr – априорная энтропия о состоянии исследуемой системы или процесса; Haps – апостериорная энтропия.
Апостериори (от лат. a posteriori – из последующего) – происходящее из опыта (испытания, измерения).
Априори (от лат. a priori – из предшествующего) – понятие, характеризующее знание, предшествующее опыту (испытанию), и независимое от него.
Получатель информации (сообщения) имеет определенное представление о возможных наступлениях некоторых событий. Эти представления в общем случае недостоверны и выражаются вероятностями, с которыми он ожидает то или иное событие. Общая мера неопределенности (энтропия) характеризуется некоторой математической зависимостью от этих вероятностей, количество информации в сообщении определяется тем, насколько уменьшается мера неопределенности после получения сообщения.
Поясним эту идею на примере.
Пусть у нас имеется 32 различные карты. Возможность выбора одной карты из колоды – 32. До произведения выбора, естественно предложить, что шансы выбрать некоторую определенную карту, одинаковы для всех карт. Произведя выбор, мы устраняем эту неопределенность. При этом неопределенность можно охарактеризовать количеством возможных равновероятностных выборов. Если теперь определить количество информации как меру устранения неопределенности, то полученную в результате выбора информацию можно охарактеризовать числом 32. Однако удобнее использовать не само это число, а логарифм от полученной выше оценки по основанию 2:
H = log2 m,
где m – число возможных равновероятных выборов (При m=2, получим информацию в один бит). То есть в нашем случае
H = log2 32 = 5.
Изложенный подход принадлежит английскому математику Р. Хартли (1928 г.). Он имеет любопытную интерпретацию. Он характеризуется числом вопросов с ответами «да» или «нет», позволяющим определить, какую карту выбрал человек. Таких вопросов достаточно 5.
Если при выборе карты, возможность появления каждой карты не одинаковы (разновероятны), то получим статистический подход к измерению информации, предложенный К. Шенноном (1948 г.). В этом случае мера информации измеряется по формуле:

где pi – вероятность выбора i -го символа алфавита.
Легко заметить, что если вероятности p1,..., pn равны, то каждая из них равна 1/N, и формула Шеннона превращается в формулу Хартли.
Меры информации семантического уровня. Для измерения смыслового содержания информации, т. е. ее количества на семантическом уровне, наибольшее распространение получила тезаурусная мера, которая связывает семантические свойства информации со способностью пользователя принимать поступившее сообщение. Действительно, для понимания и использования полученной информации получатель должен обладать определенным запасом знаний. Полное незнание предмета не позволяет извлечь полезную информацию из принятого сообщения об этом предмете. По мере роста знаний о предмете растет и количество полезной информации, извлекаемой из сообщения.
Если назвать имеющиеся у получателя знания о данном предмете тезаурусом (т. е. неким сводом слов, понятий, названий объектов, связанных смысловыми связями), то количество информации, содержащееся в некотором сообщении, можно оценить степенью изменения индивидуального тезауруса под воздействием данного сообщения.
Тезаурус — совокупность сведений, которыми располагает пользователь или система.
Иными словами, количество семантической информации, извлекаемой получателем из поступающих сообщений, зависит от степени подготовленности его тезауруса для восприятия такой информации.
В зависимости от соотношений между смысловым содержанием информации S и тезаурусом пользователя Sp изменяется количество семантической информации Iс, воспринимаемой пользователем и включаемой им в дальнейшем в свой тезаурус. Характер такой зависимости показан на рис. 2.1. Рассмотрим два предельных случая, когда количество семантической информации Iс равно 0:
а) при Sp = 0 пользователь не воспринимает (не понимает) поступающую информацию;
б) при S —> ∞ пользователь «все знает», и поступающая информация ему не нужна.

Рис. 1.2. Зависимость количества семантической информации,
воспринимаемой потребителем, от его тезауруса Ic=f(Sp)
Максимальное количество семантической информации потребитель приобретает при согласовании ее смыслового содержания S со своим тезаурусом Sp (S = Sp opt), когда поступающая информация понятна пользователю и несет ему ранее неизвестные (отсутствующие в его тезаурусе) сведения.
Следовательно, количество семантической информации в сообщении, количество новых знаний, получаемых пользователем, является величиной относительной. Одно и то же сообщение может иметь смысловое содержание для компетентного пользователя и быть бессмысленным для пользователя некомпетентного.
При оценке семантического (содержательного) аспекта информации необходимо стремиться к согласованию величин S и Sp.
Относительной мерой количества семантической информации может служить коэффициент содержательности С, который определяется как отношение количества семантической информации к ее объему:
С = Iс / Vд
Меры информации прагматического уровня. Эта мера определяет полезность информации для достижения пользователем поставленной цели. Эта мера также величина относительная, обусловленная особенностями использования этой информации в той или иной системе.
Если до получения информации вероятность достижения цели равнялась р0, а после ее получения – p1 то ценность информации определяется как логарифм отношения p1/p0:
I = log2 p1 – log2 р0 = log2 (p1/p0)
Таким образом, ценность информации при этом измеряется в единицах информации, в данном случае в битах.
Алгоритм - это организованная последовательность действий, понятных для некоторого исполнителя, ведущая к решению поставленной задачи.
Алгоритм - это конечная последовательность однозначных предписаний, исполнение которых позволяет с помощью конечного числа шагов получить решение задачи, однозначно определяемое исходными данными.
Алгоритм может быть предназначен для выполнения его человеком или компьютером.
Слово алгоритм возникло от algorithm - латинской формы имени великого математика IX века аль-Хорезми, который сформулировал правила выполнения 4 арифметических действий над многозначными числами.
Свойства алгоритма:
1. Массовость - алгоритм должен быть применен для класса подобных задач.
2. Дискретность - алгоритм состоит из ряда шагов.
3. Определенность - каждый шаг алгоритма должен пониматься однозначно и не допускать произвола.
4. Результативность - алгоритм должен приводить к решению поставленной задачи за конечное число шагов
5. Детерминированность (определенность, точность, однозначность). Это свойство заключается в том, что при задании одних и тех же исходных данных несколько раз алгоритм будет выполняться абсолютно одинаково и всегда будет получен один и тот же результат. Свойство детерминированности проявляется также и в том, что на каждом шаге выполнения алгоритма всегда точно известно, что делать дальше, а каждое действие однозначно понятно исполнителю и не может быть истолковано неопределенно. Благодаря этому свойству выполнение алгоритма носит механический характер.
По другому исполнитель алгоритма, выполнив очередную команду, должен точно знать, какую команду необходимо исполнять следующей. Это свойство алгоритма называется детерминированностью.
6. Конечность (финитность) - заключается в том, что последовательность элементарных действий алгоритма не может быть бесконечной, неограниченной, хотя может быть очень большой (если требуется, например, большая точность вычислений).
7. Корректность - означает, что если алгоритм создан для решения определенной задачи, то для всех исходных данных он должен всегда давать правильный результат и ни для каких исходных данных не будет получен неправильный результат. Если хотя бы один из полученных результатов противоречит хотя бы одному из ранее установленных и получивших признание фактов, алгоритм нельзя признать корректным.
Способы записи:
§ Словесный.
§ Формульно-словесный.
§ Графический.
§ Программа
Виды алгоритма
- Линейный - алгоритм, в котором все предписания (шаги) выполняются так, как записаны, без изменения порядка следования, строго друг за другом.
- Разветвляющийся - алгоритм, в котором выполнение того или иного действия (шага) зависит от выполнения или не выполнения какого-либо условия.
- Циклический - алгоритм, в котором некоторая последовательность действий повторяется несколько раз.