Все созданные человеком тексты построены по единым правилам! Никому не удается обойти их. Какой бы язык ни использовался, кто бы ни писал - классик или графоман - внутренняя структура текста останется неизменной.
Зипф предположил, что слова с большим количеством букв встречаются в тексте реже коротких слов.
Основываясь на этом постулате, Зипф вывел в 1949 г. два универсальных закона.
Первый закон Зипфа "ранг - частота"
Первый закон Зипфа: произведение вероятности встречаемости слова в тексте на ранг частоты есть величина постоянная.
Имеется некоторый текст.
F - частота вхождения слова – количество экземпляров слова в тексте.
Составим таблицу «слово – частота».
| Слово | Частота | Ранг частоты |
| Группа 1 | F1 = max | R1=1 |
| Слово 1 | ||
| Слово 2 | ||
| …. | ||
| Слово n1 | ||
| Группа 2 | F2 < F1 | R2=2 |
| Слово 1 | ||
| Слово 2 | ||
| …. | ||
| Слово n2 | ||
| И т.д. |
Ранг частоты - порядковый номер частоты - R.
Так, наиболее часто встречающиеся слова будут иметь ранг 1, следующие за ними 2 и т.д.
Длина текста – количество слов (всех) в тексте - ℓ.
Вероятность встречаемости слова в тексте - отношение частоты вхождения этого слова к общему числу слов в тексте.
P(встр) (i) = F(i) / ℓ
Математическая запись первого закона Зипфа:
С = P(встр)(i) * R(i) отсюда
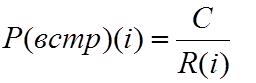
Полученная функция имеет вид y=k/x и ее график - равносторонняя гипербола. Следовательно, по первому закону Зипфа, если вероятность появления в тексте самого распространенного слова равна С/1, то вероятность появления в тексте слова, следующего по встречаемости – С/2. Иными словами, если самое распространенное в тексте слово встречается, например, 100 раз, то следующее по частоте слово вряд ли встретится 99 раз. Частота вхождения второго по популярности слова, с высокой долей вероятности, окажется на уровне 50. (Разумеется, вы должны понимать, что в статистике ничего абсолютно точного нет: 50, 52 - не так уж и важно.)
Значение константы в разных языках различно, но внутри одной языковой группы остается неизменно, какой бы текст мы ни взяли. Так, например, для английских текстов константа Зипфа равна приблизительно 0,1. Для русского языка коэффициент Зипфа составляет 0,06-0,07.
Первый закон Зипфа устанавливает соотношение между группами слов. В группу входят слова, которые встречаются в тексте с одинаковой частотой.
Второй закон Зипфа "количество - частота"
Второй закон Зипфа: для различных текстов произведение частоты слов в группе на количество слов, входящих в группу с этой частотой, есть величина постоянная.
С = F(i) * n(i)
Если построить график, отложив по оси Х частоту вхождения слова, а по оси Y - количество слов в данной частоте, то получившаяся кривая будет сохранять свои параметры для всех без исключения созданных человеком текстов! Как и в предыдущем случае, это утверждение верно в пределах одного языка. Однако и межъязыковые различия невелики. На каком бы языке текст ни был написан, форма кривой Зипфа останется неизменной. Могут немного отличаться лишь коэффициенты, отвечающие за наклон кривой (Рис. 1,2) (в логарифмическом масштабе, за исключением нескольких начальных точек, график - прямая линия).
На рис. 1 представлена графическая интерпретация первого закона Зипфа. Чем больше частота слова в тексте, тем меньше ранг частоты.
На рис. 1 желтым фоном выделены значимые слова. Исследования показывают, что наиболее значимые слова лежат в средней части диаграммы. Это и понятно. Слова, которые попадаются слишком часто, в основном оказываются предлогами, местоимениями, в английском -- артиклями и т.п. Редко встречающиеся слова также, в большинстве случаев, не имеют решающего смыслового значения.
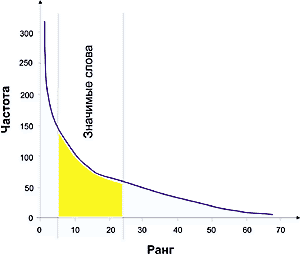 |
Рис. 1
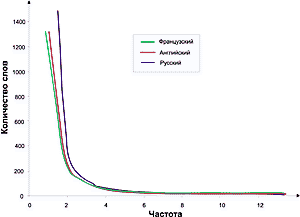 |
Рис. 2
 Из рис. 2 можно видеть, что самые большие по количеству слов группы состоят из редко встречающихся слов, и чем меньше количество слов в группе, тем больше их частота
Из рис. 2 можно видеть, что самые большие по количеству слов группы состоят из редко встречающихся слов, и чем меньше количество слов в группе, тем больше их частота
Законы Зипфа универсальны. В принципе, они применимы не только к текстам. В аналогичную форму выливается, например, зависимость количества городов от числа проживающих в них жителей. Характеристики популярности узлов в сети Интернет тоже отвечают законам Зипфа. Не исключено, что в законах отражается "человеческое" происхождение объекта. Так, например, ученые давно бьются над расшифровкой манускриптов Войнича. Никто не знает, на каком языке написаны тексты и тексты ли это вообще. Однако исследование манускриптов на соответствие законам Зипфа доказало: это созданные человеком тексты. Графики для манускриптов Войнича точно повторили графики для текстов на известных языках.
Из этих законов видно, что программа – робот должна после анализа текста конкретного документа в качестве значимых слов принять слова, имеющие «среднюю» частоту.
Наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой, как правило, являются предлогами, частицами, местоимениями, в английском языке - артиклями (так называемые "стоп-слова"), а редко встречающиеся слова в большинстве случаев не имеют решающего значения.
Аналогичным образом должен действовать человек при выборе ключевых слов и формировании поискового образа.
Для облегчения анализа создается словарь ненужных слов - стоп-слов. Например, для английского текста стоп - словами станут термины: the, a, an, in, to, of, and, that... и так далее. Для русского текста стоп – словами являются местоимения, предлоги, частицы (я, ты, не, для, потом, следствие и т.д.)
Методика составления списка ключевых слов
Правильный набор ключевых слов имеет определяющее значение для оптимального поиска информации. К примеру, задав поисковой машине в качестве ключевого слова "МАРП", будет получен список документов, в которых встречается эта аббревиатура (Московское Агентство по Развитию Предпринимательства).
Если необходимо получить документы по более широкой теме, например, «развитие предпринимательства», и сформировать простой запрос из этих двух слов, то поисковая машина выдаст список из сотен тысяч наименований, ориентироваться в котором будет весьма непросто.
Поэтому для составления оптимального набора ключевых слов используют процедуру, основанную на применении законов Зипфа, которая заключается в следующем: берут любой текст-источник, близкий к искомой теме, т.е. "образец", и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, Web-страница, любой другой документ.
Анализ текста производится таким образом:
- Удаляются из текста стоп-слова.
- Вычисляется частота вхождения каждого слова и составляется список, в котором слова расположены в порядке убывания их частоты.
- Выбирается диапазон частот, лежащих в середине списка, и отбираются из этого диапазона слова, наиболее полно соответствующих смыслу текста.
- Составляется запрос к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором ИЛИ (OR). Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов (расположению их в порядке убывания частоты вхождения слов запроса в документ), на первых страницах списка практически все документы окажутся релевантными, причем документ-источник может находиться далеко от начала.
Поисковая машина может строить весовые коэффициенты с учетом местоположения термина внутри документа, взаимного расположения терминов, частей речи, морфологических особенностей и т.п.
В качестве терминов могут выступать не только отдельные слова, но и словосочетания. Без этих законов сегодня не обходится ни одна система автоматического поиска информации в процессе индексирования документов. Математический анализ позволяет машине с хорошей точностью, без участия человека распознать суть текста.
Формирование запросов
Запросы составляются так, чтобы область поиска была максимально конкретизирована и сужена. Предпочтение отдается использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится пробная реализация запросов - как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Языки запроса различных машин поиска в основном являются сочетанием следующих функций:
§ Операторы булевой алгебры AND, OR, NOT:
AND (И) - осуществляется поиск документов, содержащих все термины, соединенные данным оператором;
§ OR (ИЛИ) - искомый текст должен содержать хотя бы один из терминов, соединенных данным оператором;
§ NOT (НЕ) - поиск документов, в тексте которых отсутствуют термины, следующие за данным оператором.
§ Операторы расстояния - ограничивают порядок следования и расстояния между словами, например:
§ NEAR - второй термин должен находиться на расстоянии от первого, не превышающем определенного числа слов;
FOLLOWED BY - термины следуют в заданном порядке;
ADJ - термины, соединенные оператором, являются смежными.
§ Возможность усечения терминов - использование символа " * " вместо окончания термина позволяет включить в искомый список все слова, производные от его начальной части (шаблона).
§ Учет морфологии языка - машина автоматически учитывает все формы данного термина, возможные в языке, на котором ведется поиск.
§ Возможность поиска по словосочетанию, фразе.
§ Ограничение поиска элементом документа (слова запроса должны находиться именно в заголовке, первом абзаце, ссылках и т.д.).
§ Ограничения по дате опубликования документа.
§ Ограничения на количество совпадений терминов.
§ Возможность поиска графических изображений.
§ Чувствительность к строчным и прописным буквам.