Генетический алгоритм
Генетический алгоритм (ГА) разработан Джоном Голландом (John Holland) в 1975 году в Мичиганском университете. В дальнейшем Д. Голдберг (D. Goldberg) выдвинул ряд гипотез и теорий, помогающих глубже понять природу генетических алгоритмов. К.ДеДжонг (K. DeJong) первым обратил внимание на важность настройки параметров ГА для общей эффективности работы и предложил свой оптимальный вариант подбора параметров, который послужил основой для всех дальнейших исследований. Существенный вклад в эти исследования внесли Дж. Грефенстетт (J. Greffenstett) и Г. Сесверда (G. Syswerda).
Генетический алгоритм был получен в процессе обобщения и имитации в искусственных системах таких свойств живой природы, как естественный отбор, приспособляемость к изменяющимся условиям среды, наследование потомками жизненно важных свойств от родителей и т.д. Так как алгоритм в процессе поиска использует некоторую кодировку множества параметров вместо самих параметров, то он может эффективно применяться для решения задач дискретной оптимизации, определённых как на числовых множествах, так и на конечных множествах произвольной природы. Поскольку для работы алгоритма в качестве информации об оптимизируемой функции используются лишь её значения в рассматриваемых точках пространства поиска и не требуется вычислений ни производных, ни каких-либо иных характеристик, то данный алгоритм применим к широкому классу функций, в частности, не имеющих аналитического описания. Использование набора начальных точек позволяет применять для их формирования различные способы, зависящие от специфики решаемой задачи, в том числе возможно задание такого набора непосредственно человеком.
Сила генетических алгоритмов в том, что этот метод очень гибок, и, будучи построенным в предположении, что об окружающей среде нам известен лишь минимум информации (как это часто бывает для сложных технических систем), алгоритм успешно справляется с широким кругом проблем, особенно в тех задачах, где не существует общеизвестных алгоритмов решения или высока степень априорной неопределенности.
Генетический алгоритм: описание
Генетический алгоритм работает с представленными в конечном алфавите строками S конечной длины l, которые используются для кодировки исходного множества альтернатив W. Строки представляют собой упорядоченные наборы из l элементов: S=(s1, s2,..., sl), каждый из которых может быть задан в своём собственном алфавите Vi,  , т.е. siО Vi, , где алфавит Vi является множеством из ri символов:
, т.е. siО Vi, , где алфавит Vi является множеством из ri символов: 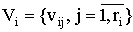 . Для решения конкретной задачи требуется однозначно отобразить конечное множество альтернатив W на множество строк подходящей длины (очевидно, что длина строк зависит от алфавитов, используемых для их задания).
. Для решения конкретной задачи требуется однозначно отобразить конечное множество альтернатив W на множество строк подходящей длины (очевидно, что длина строк зависит от алфавитов, используемых для их задания).
Для работы алгоритма необходимо на множестве строк  задать неотрицательную функцию F(S), определяющую показатель качества, “ценность” строки SО . Алгоритм производит поиск строки, для которой
задать неотрицательную функцию F(S), определяющую показатель качества, “ценность” строки SО . Алгоритм производит поиск строки, для которой 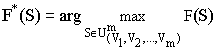
Если на множестве W задана целевая функция f(w), то функцию F(S) на множестве строк 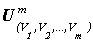 можем определить следующим образом: F(S)=f(w), если элемент w при отображении исходного множества W на множество строк был сопоставлен строке S.
можем определить следующим образом: F(S)=f(w), если элемент w при отображении исходного множества W на множество строк был сопоставлен строке S.
Генетический алгоритм за один шаг производит обработку некоторой популяции строк. Популяция G(t) на шаге t представляет собой конечный набор строк:  ,
, 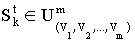 ,
, 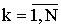 , где N -- размер популяции, причём строки в популяции могут повторяться.
, где N -- размер популяции, причём строки в популяции могут повторяться.
Анализ работы алгоритма удобно производить, используя аппарат схем. Схемой в генетическом алгоритме называют описание некоторого подмножества строк. Схема H=(h1, h2,..., hm ) может рассматриваться как строка, алфавиты для элементов которой дополнены специальным символом “#”: 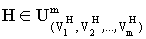 ,
, 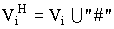 . Если в некоторой позиции r схемы H присутствует символ “#”, то такая позиция называется свободной, а сам символ “#” интерпретируется как произвольный символ из алфавита Vr. Позиция q схемы H называется фиксированной, если в этой позиции присутствует один из символов алфавита Vq. Схема H, в которой определены фиксированные и свободные позиции, описывает подмножество
. Если в некоторой позиции r схемы H присутствует символ “#”, то такая позиция называется свободной, а сам символ “#” интерпретируется как произвольный символ из алфавита Vr. Позиция q схемы H называется фиксированной, если в этой позиции присутствует один из символов алфавита Vq. Схема H, в которой определены фиксированные и свободные позиции, описывает подмножество 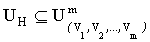 , содержащее такие строки, у которых элементы, соответствующие фиксированным позициям схемы, совпадают с символами схемы, а элементы, соответствующие свободным позициям схемы, являются произвольно заданными в соответствующих алфавитах:
, содержащее такие строки, у которых элементы, соответствующие фиксированным позициям схемы, совпадают с символами схемы, а элементы, соответствующие свободным позициям схемы, являются произвольно заданными в соответствующих алфавитах:  где I[1, m] - множество целых чисел отрезка [1, m].
где I[1, m] - множество целых чисел отрезка [1, m].
Например, для множества строк 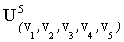 , где Vi= {0, 1},
, где Vi= {0, 1},  , схема H1 ="1###0" задаёт такое множество строк, у которых первым элементом является символ "1", пятым - "0", а остальные - либо "0", либо "1". Строки "10010", "11110" являются примерами строк, принадлежащих множеству
, схема H1 ="1###0" задаёт такое множество строк, у которых первым элементом является символ "1", пятым - "0", а остальные - либо "0", либо "1". Строки "10010", "11110" являются примерами строк, принадлежащих множеству 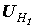 .
.
Часть популяции 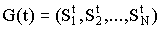 , строки которой удовлетворяют схеме H, обозначают
, строки которой удовлетворяют схеме H, обозначают  , где n(H, t) - число строк схемы H в популяции G(t) и называют подпопуляцией, соответствующей схеме H.
, где n(H, t) - число строк схемы H в популяции G(t) и называют подпопуляцией, соответствующей схеме H.
Суть генетического алгоритма заключается в следующем.
Пусть на шаге t имеется популяция G(t), состоящая из N строк. Для популяции вводится понятие средней ценности популяции Fср (G(t)): 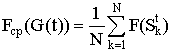
Аналогично для подпопуляции GH(t), удовлетворяющей схеме H, вводится понятие средней ценности подпопуляции Fср (GH(t)):  .
.
Генетический алгоритм осуществляет переход от популяции G(t) к популяции G(t+1) таким образом, чтобы средняя ценность составляющих её строк увеличивалась, причём количество новых строк в популяции равно KЧ N, где K - коэффициент новизны. Если K<1, то популяция будет перекрывающейся, т.е. в новой популяции сохраняются некоторые строки из старой, а если K=1, то она будет неперекрывающейся, т.е. подвергнется полному обновлению.
Генетический алгоритм включает три операции: воспроизводство, скрещивание, мутация.