Генетический алгоритм включает три операции: воспроизводство, скрещивание, мутация.
Воспроизводство представляет собой процесс выбора K*N N строк популяции G(t) для дальнейших генетических операций. Выбор производится случайным образом, причём вероятность выбора строки Sit пропорциональна её ценности: 
Процесс выбора повторяется K*N N раз. Предполагаемое количество экземпляров строки Sit в популяции G(t+1) равно 
Операция воспроизводства увеличивает общую ценность последующей популяции путём увеличения числа наиболее ценных строк.
Пусть в популяции G(t) содержится n(H, t) строк, удовлетворяющих схеме H. Тогда в результате воспроизводства количество строк, удовлетворяющих схеме H в популяции G(t+1) будет равно n(H, t+1):
 . (1)
. (1)
Используя выражения для средней ценности популяции Fср(G(t)) и подпопуляции Fср(GH(t)), можно записать формулу (1) в виде:
 . (2)
. (2)
Средняя ценность подпопуляции, соответствующей схеме H, может быть представлена в следующем виде:  , где c - некоторая величина. Тогда формула (2) примет вид:
, где c - некоторая величина. Тогда формула (2) примет вид:
 .
.
Предположим, что величина c при изменении t не изменяется; тогда, начиная с t=0, получим:  , т.е. в этом случае число представителей схемы (строк популяции G(t), соответствующих схеме) изменяется в геометрической прогрессии. В общем случае можно сказать, что процесс изменения представителей схемы так же аппроксимируется геометрической прогрессией.
, т.е. в этом случае число представителей схемы (строк популяции G(t), соответствующих схеме) изменяется в геометрической прогрессии. В общем случае можно сказать, что процесс изменения представителей схемы так же аппроксимируется геометрической прогрессией.
Таким образом, в результате операции воспроизводства те схемы, для которых соответствующие подпопуляции имеют среднюю ценность выше средней в популяции, увеличивают количество своих представителей.
Воспроизводство оперирует со строками, уже присутствующими в рассматриваемой популяции, и само по себе не способно открывать новые области поиска. Для этой цели используется операция скрещивания.
Скрещивание представляет собой процесс случайного обмена значениями соответствующих элементов для произвольно сформированных пар строк. Для этого выбранные на этапе воспроизводства строки случайным образом группируются в пары. Далее каждая пара с заданной вероятностью pскр подвергается скрещиванию. При скрещивании происходит случайный выбор позиции разделителя d (d=1, 2,..., l-1, где l - длина строки). Затем значения первых d элементов первой строки записываются в соответствующие элементы второй, а значения первых d элементов второй строки - в соответствующие элементы первой. В результате получаем две новых строки, каждая из которых является комбинацией частей двух родительских строк.
Операция скрещивания создаёт новые строки путём некоторой комбинации значений элементов наиболее ценных в популяции G(t) строк. Получившиеся в результате строки могут превосходить по ценности родительские строки.
Рассмотрим некоторую схему H, для которой определим порядок o(H) - число фиксированных позиций схемы и определяющую длину d (H) - расстояние (число позиций) между первой и последней фиксированными позициями. Допустим, что до операции скрещивания строка S была представителем схемы H, т.е.  . Допустим, что строка S1 получена из строки S в результате скрещивания. Строка S1 будет представителем схемы H в том случае, если позиция разделителя при скрещивании не располагалась между фиксированными позициями схемы. Вероятность того, что позиция разделителя окажется между фиксированными позициями схемы, равна:
. Допустим, что строка S1 получена из строки S в результате скрещивания. Строка S1 будет представителем схемы H в том случае, если позиция разделителя при скрещивании не располагалась между фиксированными позициями схемы. Вероятность того, что позиция разделителя окажется между фиксированными позициями схемы, равна:  .
.
Учтём, что скрещивание происходит с вероятностью pc, а также то, что даже если позиция разделителя окажется между фиксированными позициями схемы, строка S1 может являться представителем схемы H, если данная строка была получена скрещиванием двух представителей схемы H. Тогда вероятность ps,1 того, что строка S1 является представителем схемы H, определяется выражением:  .
.
Полагая независимость операций воспроизводства и скрещивания, оценим совокупный эффект от этих операций, т.е. число представителей схемы H в популяции G(t+1):
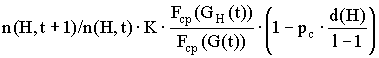 .
.
Так как открытие новых областей поиска в операции скрещивания происходит лишь путём перегруппирования имеющихся в популяции комбинаций символов, то при использовании только этой операции некоторые потенциально оптимальные области могут оставаться не рассмотренными. Для предотвращения подобных ситуаций применяется операция мутации.
Мутация представляет собой процесс случайного изменения значений элементов строки. Для этого строки, получившиеся на этапе скрещивания, просматриваются поэлементно, и каждый элемент с заданной вероятностью мутации pмут может мутировать, т.е. изменить значение на любой случайно выбранный символ, допустимый для данной позиции. Операция мутации позволяет находить новые комбинации признаков, увеличивающих ценность строк популяции.
Допустим, что до мутации строка S1 была представителем схемы H, т.е.  . Допустим, что строка S2 получена из строки S1 в результате мутации. Строка S2 будет представителем схемы H в том случае, если ни один из элементов строки, соответствующий фиксированным позициям схемы, не был изменён.
. Допустим, что строка S2 получена из строки S1 в результате мутации. Строка S2 будет представителем схемы H в том случае, если ни один из элементов строки, соответствующий фиксированным позициям схемы, не был изменён.
Учитывая, что мутация происходит с вероятностью pмут, вероятность ps2 того, что строка S2 является представителем схемы H, определяется выражением:  , где o(H) - число фиксированных позиций схемы H.
, где o(H) - число фиксированных позиций схемы H.
Полагая независимость операций воспроизводства, скрещивания и мутации оценим совокупный эффект от этих операций, т.е. число представителей схемы H в популяции G(t+1):
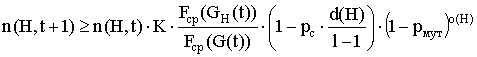 . (3)
. (3)
Так как, при малых значениях pm приближенно можно считать  , то выражение (3) можно записать в виде:
, то выражение (3) можно записать в виде:

или
 .
.
Таким образом, схемы, у которых малы определяющая длина и порядок, и для которых соответствующая подпопуляция имеет среднюю ценность, превышающую среднюю ценность популяции, экспоненциально увеличивают число представителей в последующих поколениях.
Очевидно, что эффективность описанной операции скрещивания значительно зависит от способа кодировки строк. Это свойство оказывается полезным для задач оптимизации функций, заданных на числовых множествах. Однако, если функция задана на произвольном множестве, например, на множестве комбинаций значений признаков объекта, где все признаки одинаковы по предпочтительности, то описанный выше способ скрещивания оказывается не вполне корректным, так как вероятность сохранения значений для групп признаков зависит от расстояния между элементами группы в кодовой строке, а это нарушает принцип равной предпочтительности признаков. Поэтому для таких задач операцию скрещивания предполагается производить путём обмена не частями строк, а отдельными элементами. При этом задаётся некоторое число позиций nП (nПО {1, 2, …, l}), которое определяет количество элементов строк, для которых производится обмен значениями. Число позиций nП может быть задано непосредственно или определяться случайно для каждой пары строк. Далее для каждой пары строк (S1, S2)i, где i - номер пары, случайно выбираются nП номеров ni,j (ni,j О {1, 2, …, l}; jО {1, 2, …, nП}). Затем для строк пары (S1, S2)i производится обмен значениями элементов с номерами ni,j, т.е. каждому элементу с номером ni,j строки S1 присваивается значение элемента с номером ni,j строки S2, а элементу с номером ni,j строки S2 присваивается значение элемента с номером ni,j строки S1.
Допустим, что до операции скрещивания строка S была представителем схемы H, т.е. , а строка S1 получена из строки S в результате поэлементного скрещивания. Вероятность p’s,1 того, что строка S1 будет представителем схемы H, равна:
 ,
,
где o(H) - число фиксированных позиций схемы H.
Совокупный эффект от операций воспроизводства и поэлементного скрещивания, и мутации, т.е. число представителей схемы H в популяции G(t+1) определяется выражением:
 .
.
Таким образом, при поэлементном скрещивании скорость увеличения представителей схемы в последующих поколениях зависит от средней ценности схемы и количества фиксированных позиций и не зависит от расстояния между ними, а значит, не зависит от порядка расположения элементов в строке.
Итак, в результате описанных выше операций получаем K*N N новых строк, которые либо полностью формируют новую популяцию G(t+1) (при K=1), заменяя при этом все строки популяции G(t), либо составляют часть популяции G(t+1), заменяя собой K*N N наименее ценных строк предыдущей популяции.
Как видно из описания алгоритма, закон 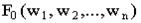 вероятности распределения значений целевой функции определяется и корректируется путём использования набора (популяции) строк, содержащих наилучшие в смысле значений целевой функции комбинации элементов.
вероятности распределения значений целевой функции определяется и корректируется путём использования набора (популяции) строк, содержащих наилучшие в смысле значений целевой функции комбинации элементов.
Список литературы
Для подготовки данной работы были использованы материалы с сайта https://g-u-t.chat.ru/ga/