При наличии существенной нелинейности в зависимости вместо простой линейной модели используют эмпирическую аппроксимацию такой зависимости, либо тот или иной нелинейный базис (модельную матрицу с нелинейными функциями).
Наиболее простым непараметрическим «сглаживателем» является локальная аппроксимация в локальном окне с использованием полинома невысокой степени (линейного или квадратичного). В качестве обоснования такой меры используется тот факт, что локально любая функция аппроксимируется с хорошей точностью первыми членами разложения в ряд Тейлора.
Построение непараметрической сглаженной кривой. Функция вычисления локальной модели loess().
loess(formula, data, weights, subset, span = 0.75, enp.target, degree = 2, control = loess.control(...),...)| formula | аналогична формуле функции lm() |
| data | таблица, в которой находятся переменные для формулы (хотя могут использоваться и глобальные переменные) |
| weights | веса строк таблицы |
| subset | индекс для выбора подмножества строк таблицы |
| span | ширина локального окна (в долях от всех строк таблицы) |
| enp.target | альтернатива для span, примерное число параметров (степеней свободы) |
| degree | Степень локальной модели, обычно 1 (линейная) или 2 (квадратичная), они соответствуют локальному поведению функции |
| control | управляющие параметры (для тонкой настройки), см. loess.control. |
Параметры
| Surface | Результат нужно вычислять точно, либо интерполировать по точкам данных? |
| statistics | Статистики нужно вычислять точно или приближенно (медленнее на больших объемах)? |
| trace.hat | Нужно вычислять Hat-матрицу для оценки неопределенности результата (используется только при большом объеме данных, от 1000 точек и более) |
| cell | При использовании аппроксимации управляет точностью, изменяя размер ячеек сетки. Ячейки с числом точек более floor(n*span*cell) точек разбиваются на более мелкие. |
| iterations | Число итераций в робастном оценивании. |
RIKZ <- read.table(file = "RIKZ.txt", header = TRUE)
RIKZ$Richness <- rowSums(RIKZ[, 2:76] > 0)
p.loess <- loess(RIKZ$Richness ~ RIKZ$grainsize, span = 0.5)
ISIT<-read.table("ISIT.txt",header=TRUE)
names(ISIT)
# [1] "SampleDepth" "Sources" "Station" "Time" "Latitude"
# [6] "Longitude" "Xkm" "Ykm" "Month" "Year"
# [11] "BottomDepth" "Season" "Discovery" "RelativeDepth"
Sources<-ISIT$Sources[ISIT$Station==16]
Depth <-ISIT$SampleDepth[ISIT$Station==16]
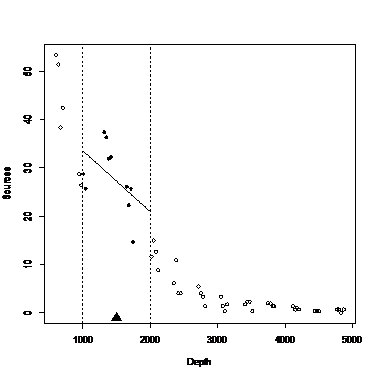
# окно для рисования
plot(Depth,Sources,type="n")
# где собираемся локально аппрокимировать, и размер окна
TargetVal<-1500
Bin<-500
B1<-TargetVal-Bin
B2<-TargetVal+Bin
abline(v=B1,lty=2)
abline(v=B2,lty=2)
points(TargetVal,-1,pch=17,cex=2)
# исходные данные
BinInterval<-vector(length=length(Depth))
BinInterval[1:length(Depth)]<-1
BinInterval[Depth>=B1 & Depth <=B2]<-16
points(Depth,Sources,pch=BinInterval)
# локальная модель
S1<-Sources[BinInterval==16]
D1<-Depth[BinInterval==16]
tmp1<-lm(S1~D1)
# прогноз по локальной модели в окне
DD1<-seq(B1,B2,length=100)
NewData<-data.frame(D1=DD1)
pred1<-predict(tmp1,newdata=NewData)
lines(DD1,pred1,lwd=2)
Пример использования сглаживания разной степени
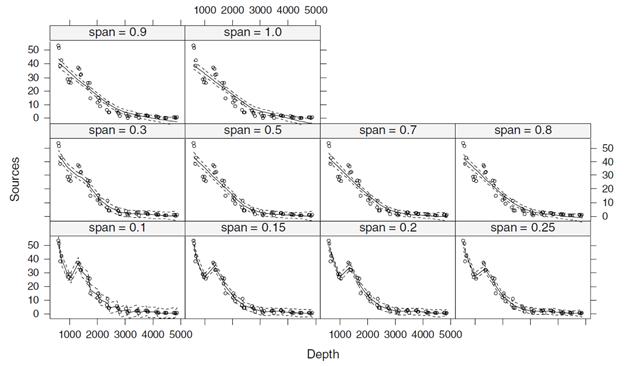
Оптимальная степень сглаживания выбирается с помощью перекрестной проверки.
Полиномиальные модели в простейшем случае могут создаваться добавлением в таблице данных степеней переменных, однако это не очень хорошо с вычислительной точки зрения, поскольку такие переменные сильно коррелированы.
x1<-runif(100,50,90)
x2<-x1^2
x3<-x1^3
x4<-x1^4
Cor(cbind(x1,x2,x3,x4))
x1 x2 x3 x4
x1 1.0000000 0.9973913 0.9899101 0.9782437
x2 0.9973913 1.0000000 0.9975434 0.9905948
x3 0.9899101 0.9975434 1.0000000 0.9977349
x4 0.9782437 0.9905948 0.9977349 1.0000000
Поэтому обычно в качестве базиса используют ортогональные полигоны заданной степени, корреляция между которыми равна нулю.
poly(x,..., degree = 1, coefs = NULL, raw = FALSE) Параметры| x | Вектор с точками для вычисления полинома |
| degree | Степень полинома (должна быть меньше числа уникальных точек). |
| coefs | Коэффициенты для прогноза |
| raw | Если TRUE, то используются обычные (не ортогональные) полиномы. |
tmp<-poly(x, degree = 3, raw = FALSE))
1 2 3
[1,] -0.49543369 0.52223297 -0.4534252
[2,] -0.38533732 0.17407766 0.1511417
[3,] -0.27524094 -0.08703883 0.3778543
[4,] -0.16514456 -0.26111648 0.3346710
[5,] -0.05504819 -0.34815531 0.1295501
[6,] 0.05504819 -0.34815531 -0.1295501
[7,] 0.16514456 -0.26111648 -0.3346710
[8,] 0.27524094 -0.08703883 -0.3778543
[9,] 0.38533732 0.17407766 -0.1511417
[10,] 0.49543369 0.52223297 0.4534252
Cor(tmp)
1 2 3
1 1.000000e+00 -3.317659e-17 1.330858e-17
2 -3.317659e-17 1.000000e+00 -4.385598e-17
3 1.330858e-17 -4.385598e-17 1.000000e+00
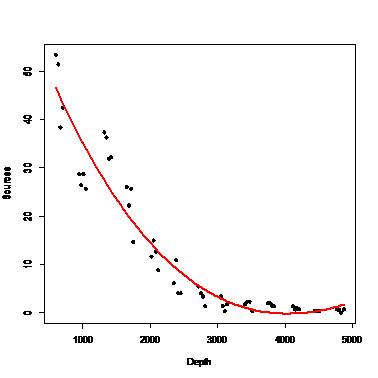
p.lm2<-lm(Sources~poly(Depth, degree=3))
Summary(p.lm2)
Call:
lm(formula = Sources ~ poly(Depth, degree = 3))
Residuals:
Min 1Q Median 3Q Max
-9.4265 -1.9484 -0.1012 1.5367 9.8750
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.4771 0.6043 20.646 < 2e-16 ***
poly(Depth, degree = 3)1 -93.3026 4.3157 -21.619 < 2e-16 ***
poly(Depth, degree = 3)2 43.8321 4.3157 10.156 1.94e-13 ***
poly(Depth, degree = 3)3 -3.6068 4.3157 -0.836 0.408
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.316 on 47 degrees of freedom
Multiple R-squared: 0.924, Adjusted R-squared: 0.9191
F-statistic: 190.4 on 3 and 47 DF, p-value: < 2.2e-16
new.Depth<-data.frame(Depth=seq(min(Depth),max(Depth),len=100))
p.lm2.prd<-predict(p.lm2,newdata=new.Depth)
plot(depth,Sources,pch=20,cex=1.5)
lines(new.Depth$Depth,p.lm2.prd,lwd=3,col="red")